列表
概念:Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
列表的使用
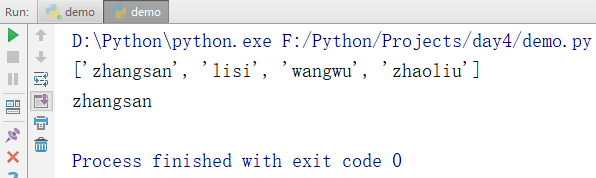
names = ['zhangsan','lisi','wangwu','zhaoliu'] //定义一个了列表 print(names) //输出列表的所有内容 print(names[0]) //输出列表的第0个内容
//用索引来访问list中每一个位置的元素,记得索引是从0开始的。
输出结果:
如果要取最后一个元素,除了计算索引位置外,还可以用-1做索引,直接获取最后一个元素:
names = ['zhangsan','lisi','wangwu','zhaoliu','vector'] print(names[-1])
输出结果:
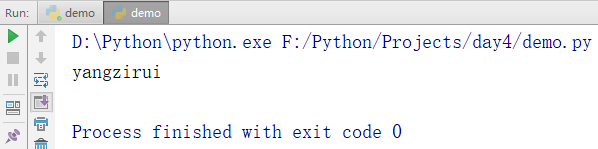
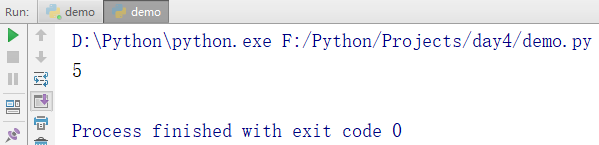
用len()函数可以获得list元素的个数。
names = ['zhangsan','lisi','wangwu','zhaoliu','yangzirui'] print(len(names))
输出结果:
当索引超出了范围时,Python会报一个IndexError错误,所以,要确保索引不要越界,记得最后一个元素的索引还可以是len(classmates) - 1。
切片
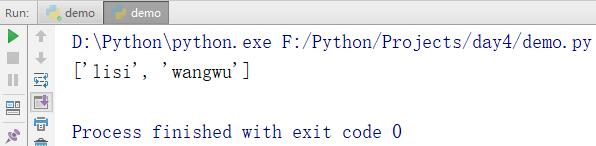
如果想取出中间一段连续的元素,则用name[1:3]的方式,这个参数是左闭右开的。也就是说从第1位取到第2位。
names = ['zhangsan','lisi','wangwu','zhaoliu'] print(names[1:3])# 切片
输出结果:
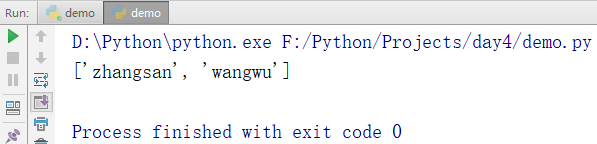
跳着切片
names = ['zhangsan','lisi','wangwu','zhaoliu']
print(names[0:-1:2]) # 从第0个到倒数第2个, 每两个元素取一个
输出结果:
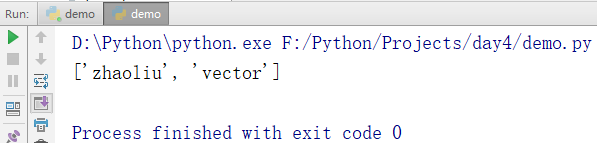
倒着切片
names = ['zhangsan','lisi','wangwu','zhaoliu','vector','zhaoliu']
print(names[-3,-1]) # 这也是左闭右开的,表示从倒数第三个切到倒数第二个
# 如果想切到倒数第一个, 就这样写 name[-3:] 这样就表示从倒数第三个切到最后一个了
输出结果:
追加元素
如果想在列表的最后面追加一个元素, 就用函数append('元素')。
names = ['zhangsan','lisi','wangwu','zhaoliu','vector','zhaoliu']
names.append('sunqi')
print(names)
输出结果:

插入元素
插在任意元素的前面, 用函数insert(2,'元素')。
names = ['zhangsan','lisi','wangwu','zhaoliu','vector','zhaoliu'] names.insert(1,'yangsan') # 插在下标为1的元素的前面 print(names)
输出结果:

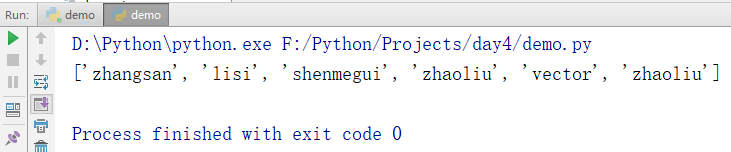
修改元素
names = ['zhangsan','lisi','wangwu','zhaoliu','vector','zhaoliu'] names[2] = 'shenmegui' print(names)
输出结果:
删除元素的三种方法
names = ['zhangsan','lisi','wangwu','zhaoliu']
names.remove('shenmegui') # 根据内容删除 del names[2] # 根据下标删除 names.pop(2) # 如果输入下标,则效果=del names[2], 如果不输入下标,则默认删除最后一个元素
根据元素内容找到元素的下标
names = ['zhangsan','lisi','wangwu','zhaoliu','vector','zhaoliu']
print(names.index('zhangsan')) //利用index函数将下标取出来
# 还有一种方式是在循环的时候取出下标
for i in enumerate(names):
print(i) # 这样取的时候就会有下标
# 但是如果我想把下标分离出来, 该怎么处理
for index,i in enumerate(names):
print(index,i) # 这样index里面就装了分离出来的下标
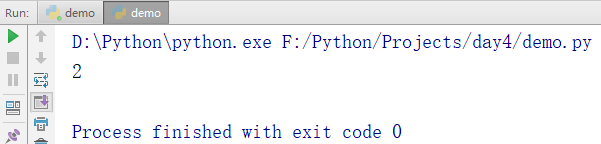
计算某个元素的个数
names = ['zhangsan','lisi','zhangsan','zhaoliu','vector','zhaoliu']
print(names.count('zhangsan'))
输出结果:
清空列表
names = ['zhangsan','lisi','zhangsan','zhaoliu','vector','zhaoliu'] names.clear()
翻转列表
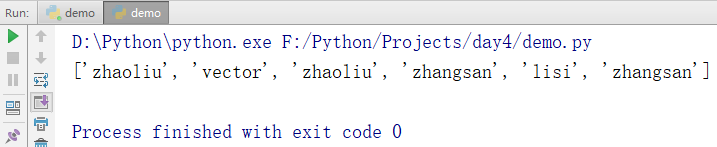
names = ['zhangsan','lisi','zhangsan','zhaoliu','vector','zhaoliu'] names.reverse() print(names)
输出结果:
排序
规则是按照ASCII码表的顺序排的。
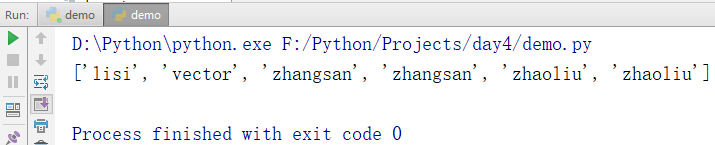
names = ['zhangsan','lisi','zhangsan','zhaoliu','vector','zhaoliu'] names.sort() print(names)
输出结果:
追加合并
names = ['zhangsan','lisi','zhangsan','zhaoliu','vector','zhaoliu'] names2 = [1,2,3,4] names.extend(names2)
print(names)
输出结果:

浅拷贝列表
这个第一维时是深拷贝,第二维开始是浅拷贝。
names = ['zhangsan','lisi','wangwu','zhaoliu']
names3 = names.copy() // 第一种方式 p1 = names[:] // 第二种方式 p2 = list(names) // 第三种方式
深拷贝 需要引入copy模块
names = ['zhangsan','lisi','zhangsan','zhaoliu','vector','zhaoliu'] import copy names2 = copy.copy(names)
循环列表
names = ['zhangsan','lisi','zhangsan','zhaoliu','vector','zhaoliu']
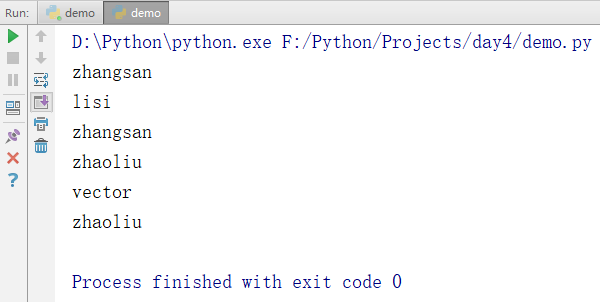
for i in names:
print(i)
输出结果:
判断一个元素是否在列表里
names = ['zhangsan','lisi','zhangsan','zhaoliu','vector','zhaoliu']
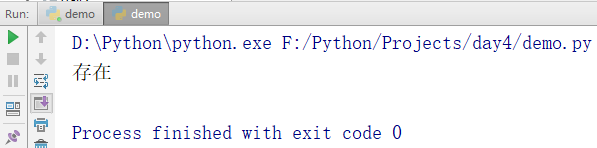
if 'zhangsan' in names:
print('存在')
输出结果:
元组
元组就是只能查数据的列表。
定义格式:
names = ('zhangsan','lisi')
它只有两个方法, count 和 index。