import pandas as pd
# 导入第三方模块
from sklearn import svm
from sklearn import model_selection
from sklearn import metrics
# 读取外部数据
letters = pd.read_csv(r'F:\python_Data_analysis_and_mining\13\letterdata.csv')
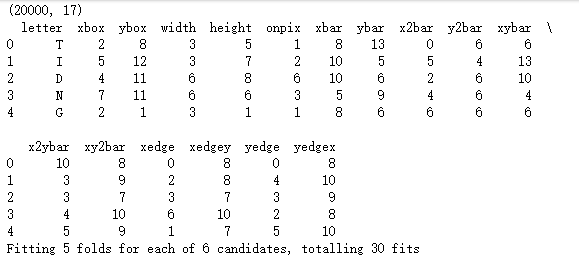
print(letters.shape)
# 数据前5行
print(letters.head())
# 将数据拆分为训练集和测试集
predictors = letters.columns[1:]
X_train,X_test,y_train,y_test = model_selection.train_test_split(letters[predictors], letters.letter, test_size = 0.25, random_state = 1234)
# 使用网格搜索法,选择线性可分SVM“类”中的最佳C值
C=[0.05,0.1,0.5,1,2,5]
parameters = {'C':C}
grid_linear_svc = model_selection.GridSearchCV(estimator = svm.LinearSVC(),param_grid =parameters,scoring='accuracy',cv=5,verbose =1)
# 模型在训练数据集上的拟合
grid_linear_svc.fit(X_train,y_train)
# 返回交叉验证后的最佳参数值
print(grid_linear_svc.best_params_, grid_linear_svc.best_score_)
# 模型在测试集上的预测
pred_linear_svc = grid_linear_svc.predict(X_test)
# 模型的预测准确率
metrics.accuracy_score(y_test, pred_linear_svc)
# 使用网格搜索法,选择非线性SVM“类”中的最佳C值
kernel=['rbf','linear','poly','sigmoid']
C=[0.1,0.5,1,2,5]
parameters = {'kernel':kernel,'C':C}
grid_svc = model_selection.GridSearchCV(estimator = svm.SVC(),param_grid =parameters,scoring='accuracy',cv=5,verbose =1)
# 模型在训练数据集上的拟合
grid_svc.fit(X_train,y_train)
# 返回交叉验证后的最佳参数值
print(grid_svc.best_params_, grid_svc.best_score_)
# 模型在测试集上的预测
pred_svc = grid_svc.predict(X_test)
# 模型的预测准确率
metrics.accuracy_score(y_test,pred_svc)
# 读取外部数据
forestfires = pd.read_csv(r'F:\python_Data_analysis_and_mining\13\forestfires.csv')
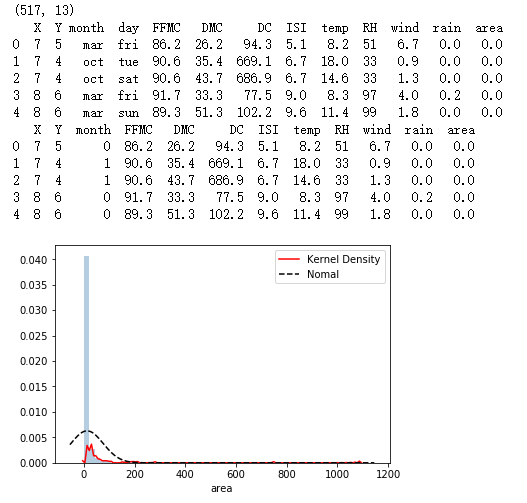
print(forestfires.shape)
# 数据前5行
print(forestfires.head())
# 删除day变量
forestfires.drop('day',axis = 1, inplace = True)
# 将月份作数值化处理
forestfires.month = pd.factorize(forestfires.month)[0]
# 预览数据前5行
print(forestfires.head())
# 导入第三方模块
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import norm
# 绘制森林烧毁面积的直方图
sns.distplot(forestfires.area, bins = 50, kde = True, fit = norm, hist_kws = {'color':'steelblue'},
kde_kws = {'color':'red', 'label':'Kernel Density'},
fit_kws = {'color':'black','label':'Nomal', 'linestyle':'--'})
# 显示图例
plt.legend()
# 显示图形
plt.show()
# 导入第三方模块
from sklearn import preprocessing
import numpy as np
from sklearn import neighbors
# 对area变量作对数变换
y = np.log1p(forestfires.area)
# 将X变量作标准化处理
predictors = forestfires.columns[:-1]
X = preprocessing.scale(forestfires[predictors])
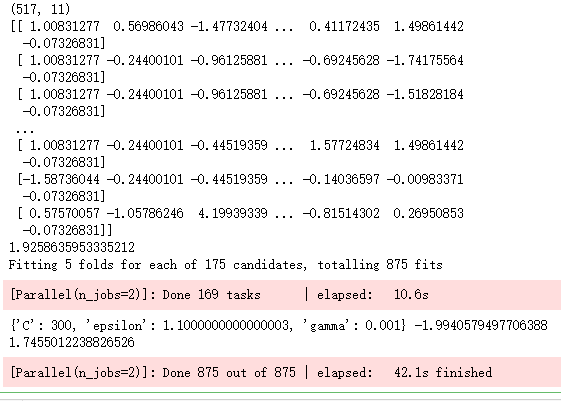
print(X.shape)
print(X)
# 将数据拆分为训练集和测试集
X_train,X_test,y_train,y_test = model_selection.train_test_split(X, y, test_size = 0.25, random_state = 1234)
# 构建默认参数的SVM回归模型
svr = svm.SVR()
# 模型在训练数据集上的拟合
svr.fit(X_train,y_train)
# 模型在测试上的预测
pred_svr = svr.predict(X_test)
# 计算模型的MSE
a = metrics.mean_squared_error(y_test,pred_svr)
print(a)
# 使用网格搜索法,选择SVM回归中的最佳C值、epsilon值和gamma值
epsilon = np.arange(0.1,1.5,0.2)
C= np.arange(100,1000,200)
gamma = np.arange(0.001,0.01,0.002)
parameters = {'epsilon':epsilon,'C':C,'gamma':gamma}
grid_svr = model_selection.GridSearchCV(estimator = svm.SVR(),param_grid =parameters,
scoring='neg_mean_squared_error',cv=5,verbose =1, n_jobs=2)
# 模型在训练数据集上的拟合
grid_svr.fit(X_train,y_train)
# 返回交叉验证后的最佳参数值
print(grid_svr.best_params_, grid_svr.best_score_)
# 模型在测试集上的预测
pred_grid_svr = grid_svr.predict(X_test)
# 计算模型在测试集上的MSE值
print(metrics.mean_squared_error(y_test,pred_grid_svr))