classification_report的调用为:classification_report(y_true, y_pred, labels=None, target_names=None, sample_weight=None, digits=2, output_dict=False)
y_true : 真实值
y_pred : 预测值
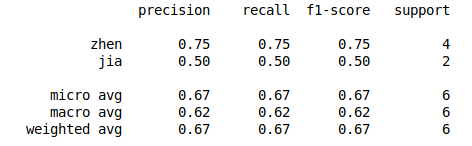
from sklearn.metrics import classification_report truey = np.array([0,0,1,1,0,0]) prey = np.array([1,0,1,0,0,0]) print(classification_report(truey,prey,target_names=['zhen','jia']))
1)fraction of true positives/false positive/false negative/true negative
True Positive (真正, TP)被模型预测为正的正样本;
True Negative(真负 , TN)被模型预测为负的负样本 ;
False Positive (假正, FP)被模型预测为正的负样本;
False Negative(假负 , FN)被模型预测为负的正样本;
2)precision/recall,准确率和召回率
系统检索到的相关文档(A)
系统检索到的不相关文档(B)
相关但是系统没有检索到的文档(C)
不相关但是被系统检索到的文档(D)
召回率R:R=A/(A+C)
精度P: P=A/(A+B).
3)F1-score
F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0。
