索引是为了加速数据的检索,但是不合理的表结构或适应不当则会起到反作用。我们在项目中就遇到过类似的问题,两个十万级别的数据表,在做连接查询的时候,查询时间达到了7000多秒还没有查出结果。
首先说明,关联的字段都已经建立了相对应的索引,在执行计划的时候发现另外一张表没有走索引,结果如下图:

具体描述为:Range checked for each record (index map: 0x1); Not exists
优化:
1、当然最直接的想法就是修改两个表的request_id字段的定义,改成相同即可。修改完成后,执行计划还是和没有修改的时候一样
2、由于两张表中的字段类型都是varchar类型的,所以猜测会存在字符集的问题,在Navicat中查看其排序规则不同
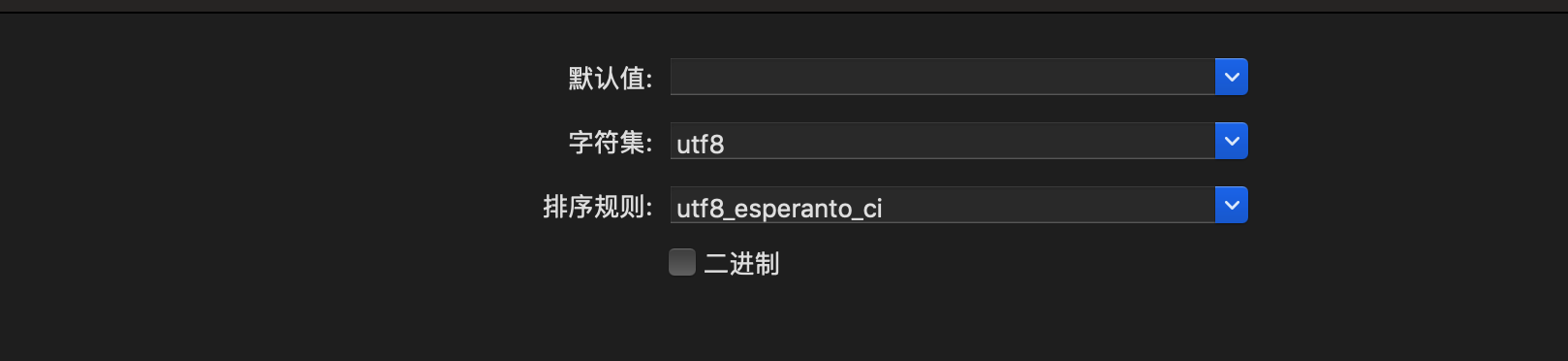
3、修改完成后,执行计划![]() 关联查询走了索引,并且查询速度从之前的7000多秒没有查出结果变成了0.25秒出现了结果
关联查询走了索引,并且查询速度从之前的7000多秒没有查出结果变成了0.25秒出现了结果
结论:
1、表列类型,与where值类型不同会导致全表扫描。
例:phone char(11) select * from table where phone=12345678901;
2、join的两个表的字符编码不同,不能命中索引,会导致笛卡尔积的循环计算(mysql8.0已经做了相关优化,字符集不在影响索引)