平均负载
uptime
结果
这个命令可以快速查看机器的负载情况。在Linux系统中,这些数据表示等待CPU资源的进程和阻塞在不可中断IO进程(进程状态为D)的数量。这些数据可以让我们对系统资源使用有一个宏观的了解。
命令的输出分别表示1分钟、5分钟、15分钟的平均负载情况。通过这三个数据,可以了解服务器负载是在趋于紧张还是区域缓解。如果1分钟平均负载很 高,而15分钟平均负载很低,说明服务器正在命令高负载情况,需要进一步排查CPU资源都消耗在了哪里。反之,如果15分钟平均负载很高,1分钟平均负载 较低,则有可能是CPU资源紧张时刻已经过去。
系统核心指标 vmstat 1 结果 vmstat 命令,每行会输出一些系统核心指标,这些指标可以让我们更详细的了解系统状态。后面跟的参数1,表示每秒输出一次统计信息,表头提示了每一列的含义,这几介绍一些和性能调优相关的列: r:等待在CPU资源的进程数。这个数据比平均负载更加能够体现CPU负载情况,数据中不包含等待IO的进程。如果这个数值大于机器CPU核数,那么机器的CPU资源已经饱和。 free:系统可用内存数(以千字节为单位),如果剩余内存不足,也会导致系统性能问题。下文介绍到的free命令,可以更详细的了解系统内存的使用情况。 si, so:交换区写入和读取的数量。如果这个数据不为0,说明系统已经在使用交换区(swap),机器物理内存已经不足。 us, sy, id, wa, st:这些都代表了CPU时间的消耗,它们分别表示用户时间(user)、系统(内核)时间(sys)、空闲时间(idle)、IO等待时间(wait)和被偷走的时间(stolen,一般被其他虚拟机消耗)。 上述这些CPU时间,可以让我们很快了解CPU是否出于繁忙状态。 一般情况下,如果用户时间和系统时间相加非常大,CPU出于忙于执行指令。 如果IO等待时间很长,那么系统的瓶颈可能在磁盘IO。 如果大量CPU时间消耗在用户态,也就是用户应用程序消耗了CPU时间。这不一定是性能问题,需要结合r队列,一起分析。
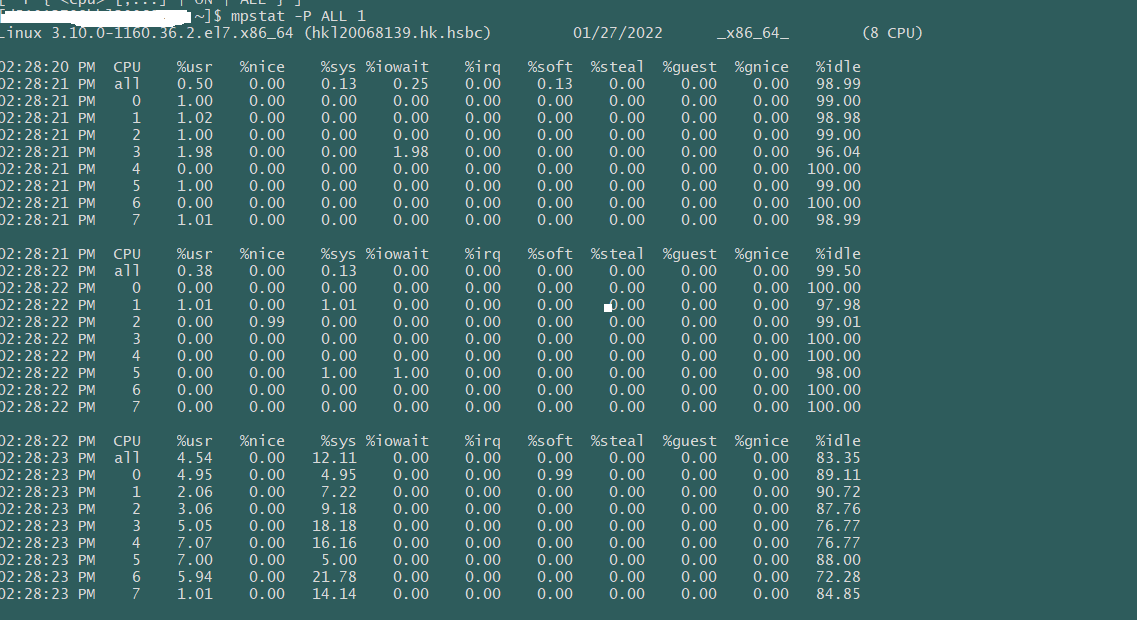
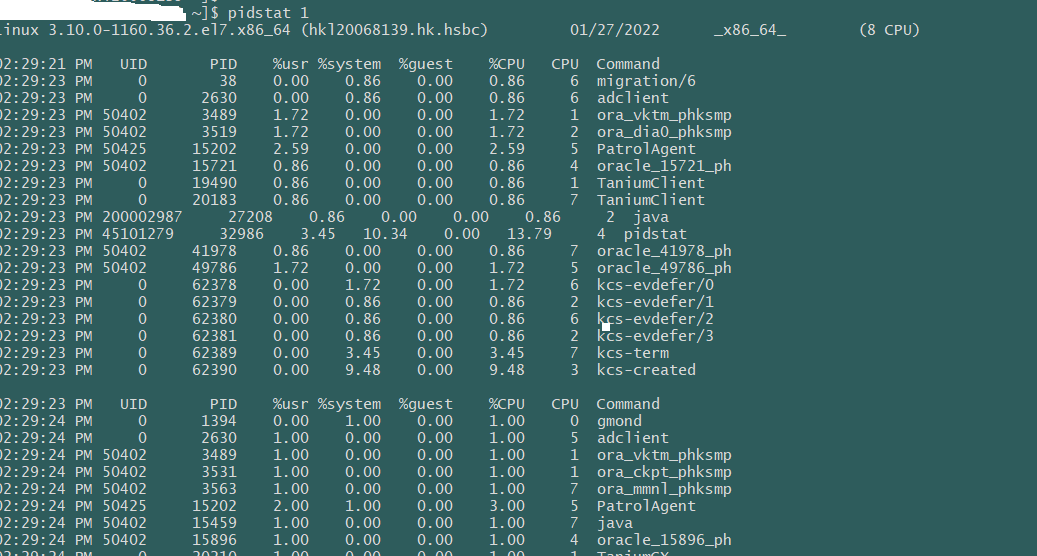
CPU占用情况-每个核心 mpstat -P ALL 1 结果 该命令可以显示每个CPU的占用情况,如果有一个CPU占用率特别高,那么有可能是一个单线程应用程序引起的。 CPU占用情况-每个进程 pidstat 1 结果 pidstat命令输出进程的CPU占用率,该命令会持续输出,并且不会覆盖之前的数据,可以方便观察系统动态。 如上的输出,可以看见两个JAVA进程占用了将近1600%的CPU时间,既消耗了大约16个CPU核心的运算资源。
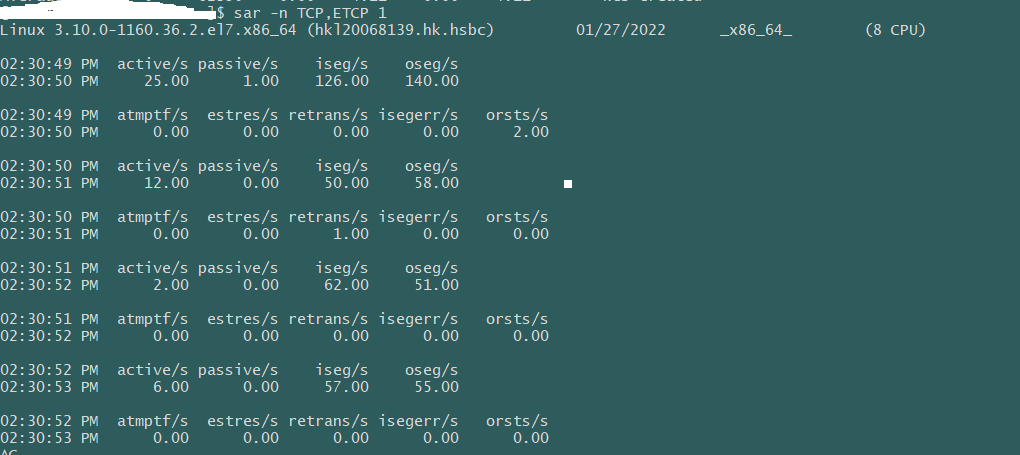
TCP连接数 sar -n TCP,ETCP 1 结果 sar命令在这里用于查看TCP连接状态,其中包括: active/s:每秒本地发起的TCP连接数,既通过connect调用创建的TCP连接; passive/s:每秒远程发起的TCP连接数,即通过accept调用创建的TCP连接; retrans/s:每秒TCP重传数量; TCP连接数可以用来判断性能问题是否由于建立了过多的连接,进一步可以判断是主动发起的连接,还是被动接受的连接。TCP重传可能是因为网络环境恶劣,或者服务器压力过大导致丢包。