来源:1、https://www.bilibili.com/video/BV1F4411y7o7?from=search&seid=18163349097576445033
2、https://www.cnblogs.com/kongweisi/p/10987870.html(感觉写的比我好到天际了,哭了)
3、https://www.cnblogs.com/nsnow/p/4562308.html(CNN介绍链接+1)
根据b站视频做的笔记。本人属于初学,水平不高,记录内容难免有误。请各位不吝赐教,积极指正。
要是能让各位看官有所收获,嘿嘿,那在下就功德无量了(doge)
1 卷积层:提取原始输入的特征
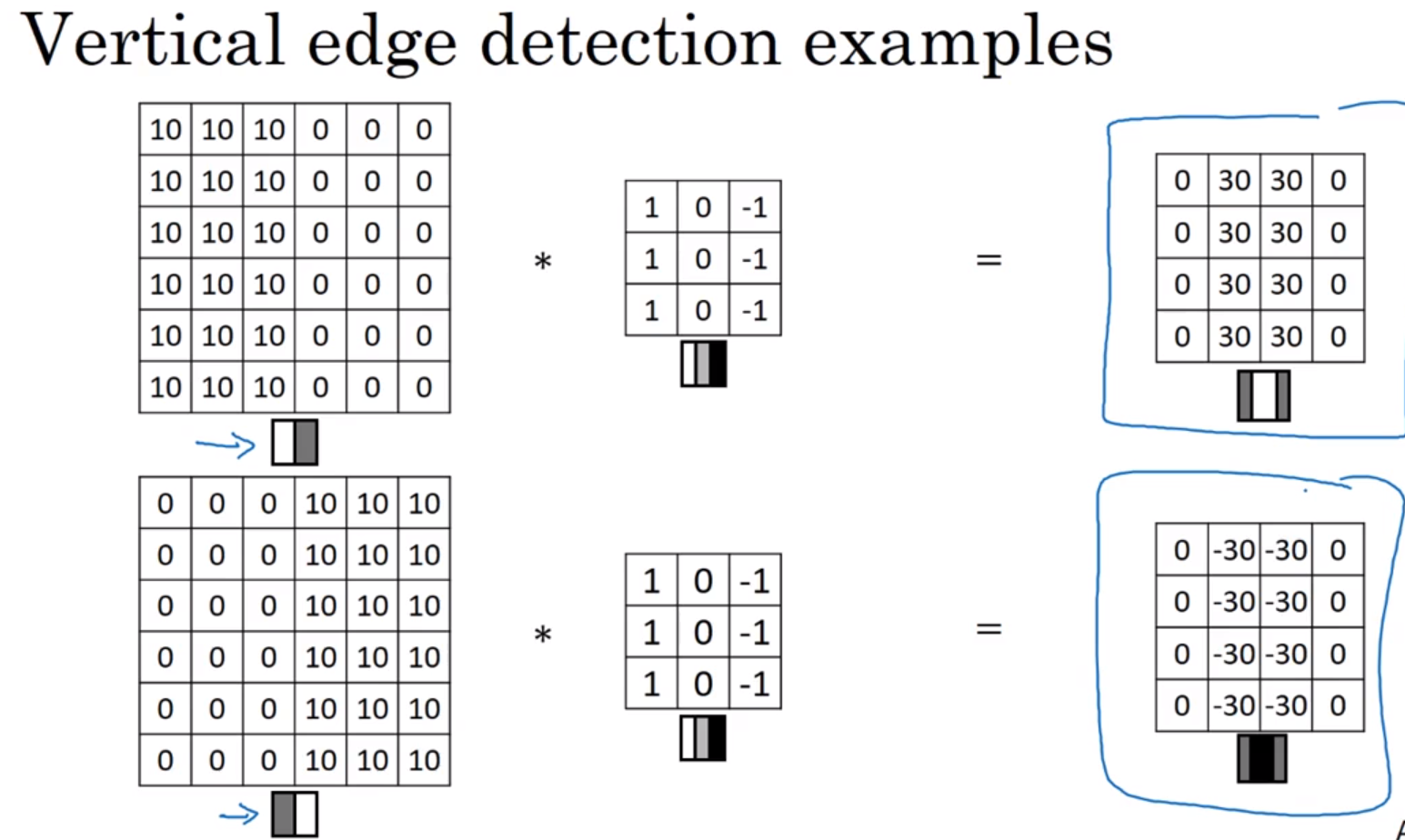
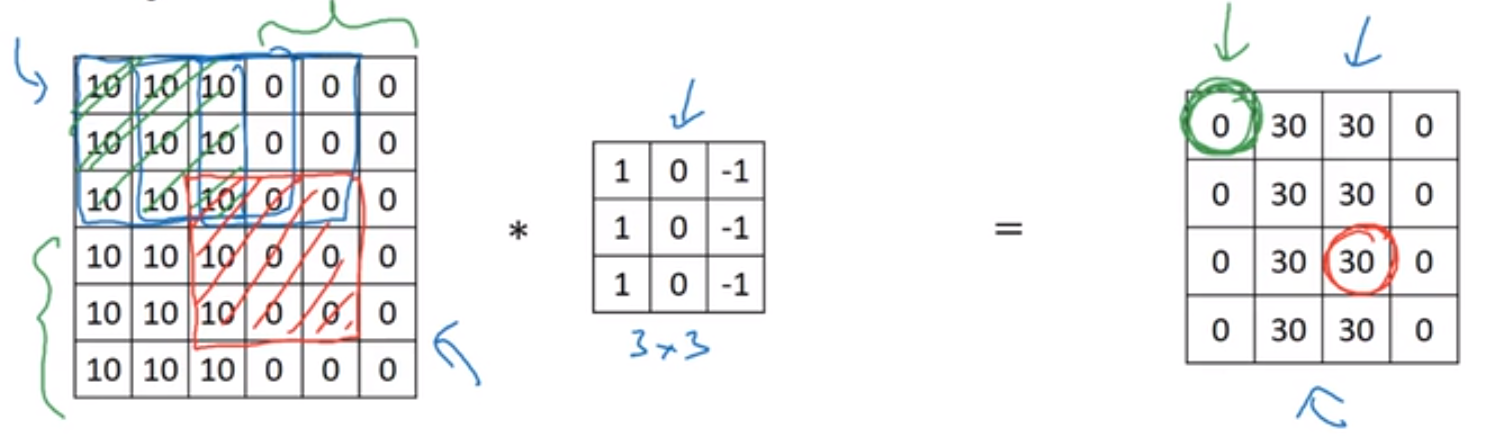
边缘检测:从亮到暗,从暗到亮。上面的卷积核是从亮到暗,而得到的最后边缘结果是正数,则是由亮到暗。
反之,则是下面的卷积核由亮到暗,最后结果是小于0,则原图像就是由暗到亮。
2 Padding 卷积
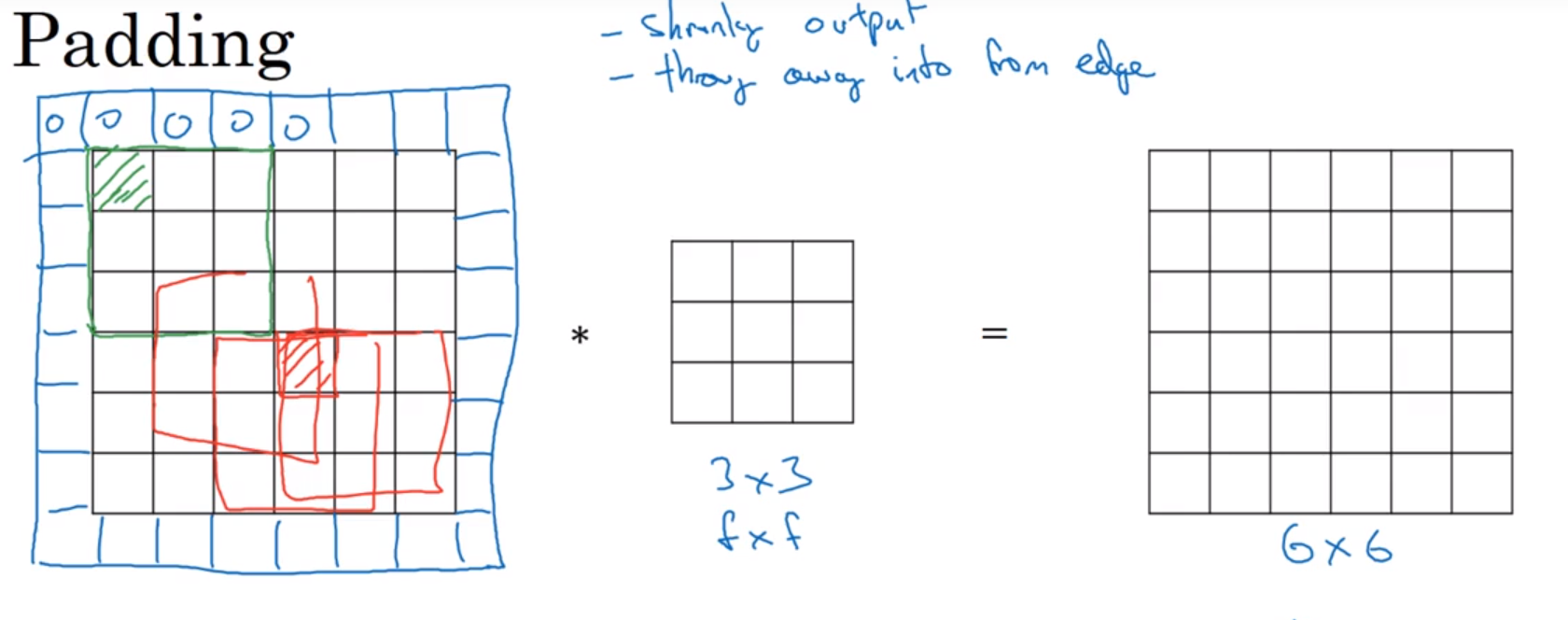
Padding卷积:在利用卷积核对图像进行卷积的时候,如3x3的卷积核,则每卷积一次,图像就会缩小一次。因此可以通过在卷积之前对图像进行扩充来保证图像的大小。可以添加0。(这不是Padding卷积标准定义,只是说明以下内容将的是和Padding卷积相关的内容)
$N*N$的图像,通过$f*f$的滤波,最后得到的图像为$(N-f+1)*(N-f+1)$
但是这样一来,添加的像素就会对最后的结果产生影响,但由于添加的是图像边界的像素,对最后的结果影响较小,这一缺点就被削弱了。(当然,添加的不一定仅仅是一层像素)
像素填充的策略:
1、valid :不进行填充 ,直接进行卷积,得到最后的结果
2、same:根据卷积核窗口的大小决定向原图片外侧添加几层像素,来保证得到的结果图片大小与原图片保持一致。如原图片为$N*N$的,若核为$f1=3*3$,则需要添加1层,变为$(N+1)*(N+1)$;若核函数为$f2=5*5$则需要添加两层,变为$(N+2)*(N+2)$【很少有偶数的窗口进行使用】
3、tips:以上添加几层像素的讨论建立在卷积的步长为 1 的状态之下。总结一下,对于Padding卷积,原图大小为$N*N$,卷积核大小为$f*f$,得到的结果图片大小为$(N+2p-f+1)*(N+2p-f+1)$,其中$p$是对原图片补充的层数

3 对于卷积步长不是 1 的卷积
对于卷积步长不是为 1 的卷积:假设卷积步长为$s$,则对于Padding卷积,最后得到的结果图片大小为$frac{N+2p-f+1}{s}*frac{N+2p-f+1}{s}$,再次过程中,若出现不为整数的情况,则可以进行向下取整。
tips:在数学领域上,两个矩阵的相互卷积实际上需要将卷积核进行水平和竖直两个方向上的翻转,然后在进行乘加操作。
在图像处理领域,两个矩阵的卷积就是我们熟悉的乘加操作,但在数学本质上是一个互相关的操作。但在图像处理领域,根据惯例,我们叫他卷积。
4 RGB图像卷积(三维卷积)
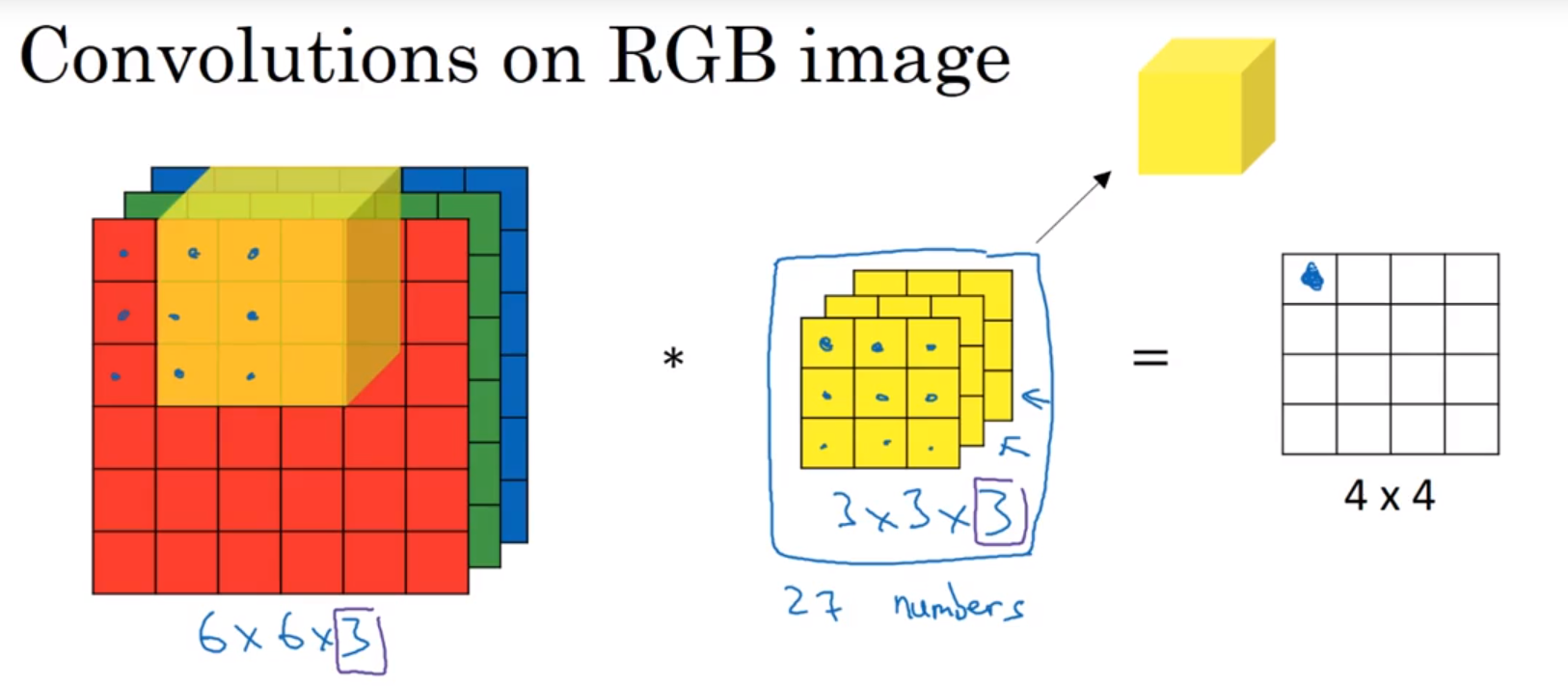
$6*6*3$ 的原图片,$3*3*3$的卷积核,最后得到的卷积结果图片大小为$4*4$的一个二维图片,其过程就是 27 个对应的像素值进行乘加,最后得到一个值,对应到二维图像中。
tips:红绿蓝不同通道的卷积核可以不同,若不关心红色通道的结果,则可以将红色通道的窗口置为0。
如果不仅仅想检测垂直方向的边缘,还有水平方向的边缘,则可以用两个窗口进行流程相同的卷积操作。
在算得最终结果之前,需要进行乘以激活函数和加上偏移量,最后才能得到需要的结果。(暂时不理解)
激活函数介绍:https://zhuanlan.zhihu.com/p/32824193
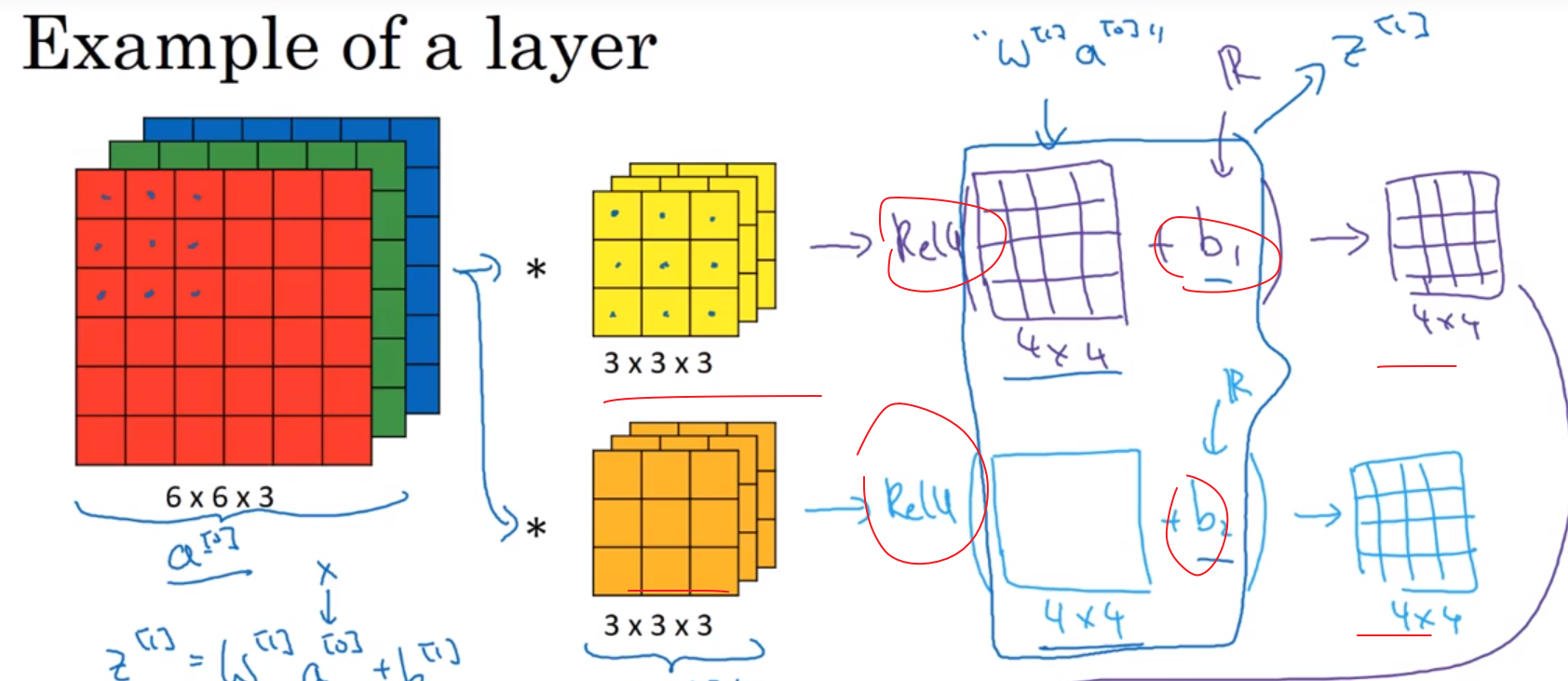
此中是假设图像有两个特征,因此用了两个滤波器进行特征提取,最后得到一个$4*4*2$的一个结果。要是有十个特征,则也可以用是个滤波器进行滤波。
5 卷积层小总结
其中$l$代表的是第$l$层卷积;$f$表示滤波器的大小;$p$表示Padding的选择,可以选择无Padding,则结果图片变小,也可选择有Padding(即在滤波前将原图片按照一定规则变大),则结果图片与原图片大小一致。
tips:首先要注意的是,这一层的输入不一定就是图片,而是某个维度的、由上一层计算得到的数据(如$N_H*N_W*n_c$维),其中$n_c$为通道数(如上面的通道数就是2)。因为输入的维度高度和宽度不一定相等,因此加入下标H和W。
经过这一层的卷积运算得到的图像大小为:$N_H=[dfrac{N_H^{[l-1]}+2p^{[l]}-f^{[l]}}{s^{[l]}}+1]$;$N_W=[dfrac{N_W^{[l-1]}+2p^{[l]}-f^{[l]}}{s^{[l]}}+1]$
其中的激活函数的维度:$a^{[l]}=N_H*N_W*n_c$ (其中等式代表他的维度是多少,不代表具体值)
若有$m$个激活函数的时候,则激活函数的维度就是$A^{[l]}=m*N_H^{[l]}*N_W^{[l]}*n_c^{[l]}$ (其中等式代表他的维度是多少)
权重(所有过滤器的集合)的维度:$f_{[l]}*f_{[l]}*n_c^{[l-1]}*n_c^{[l]}$ 注意,前一个$n_c$代表通道数,后一个$n_c$代表的是滤波器个数。(其中等式代表他的维度是多少)
小tips :$n_c$的大小在最初等于图像的通道数,在经历过一次多个卷积核的卷积之后,得到的结果图像的通道数就和卷积核的数量相同。即上一层有多少个滤波器,下一层的输入就有多少个通道
偏移量的维度:$1*1*1*n_c^{[l]}$,其中参数意义同 “权重”部分

$a^{[1]}=g(z^{[1]})$;$z^{[1]}=W^{[1]}a^{[0]}+b^{[1]}$其中$a$就是原图片,$W$就是多个滤波窗口的集合
6 卷积过程中数据纬度变化
原图:$39*39*3 ; N_H^{[0]}=N_W^{[0]}=39 ;n_c^{[0]}=3(通道数) $
滤波:$f_{[1]}=3 ; s_{[1]}=1 ;p_{[1]}=0 ;10个filters $
结果:$37*37*10 ; N_H^{[1]}=N_W^{[1]}=37$ ;$n_c^{[1]}=10$(通道数) ;其中$37=frac{n+2p-f}{s}+1$,是由前面的公式得到。
滤波:$f_{[2]}=5 ; s_{[2]}=2 ;p_{[2]}=0 ;20个filters $
结果:$17*17*20 ; N_H^{[2]}=N_W^{[2]}=17$ ;$n_c^{[0]}=10$(通道数) ;其中$17=frac{n+2p-f}{s}+1$,是由前面的公式得到。
再次根据要求进行如上操作,最终提取得到一个$7*7*40=1960$的特征,最终将这个矩阵展开成一个长向量,将其输入到一个如softmax样的回归函数当中,用来产生最后的预测结果。
tips:首先,不一定非得是正方形,也可以$N_H和N_W$不同,这就要看初始图像的大小情况了
其次,在各次滤波中间还会有W权重,b偏移和激活函数的加入。$a^{[1]}=g(z^{[1]})$;$z^{[1]}=W^{[1]}a^{[0]}+b^{[1]}$
其中$N_H$ 为此时图像高度,$f$为滤波器宽度,$p$为采不采取Padding卷积,$n_c$为通道数

7 池化层
池化层:用来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性
个人理解:max pool(最大池化) 用来找到最大的特征,即使猫这个对象在图片中平移位置,但是这个最大的特征还是会被捕捉到。
个人理解:实际上,池化层就是在压缩大小
一个简单的示例:原图为$4*4$,最后得到的示$2*2$,用到的示最大池化层(按照规则取最大值),用到的核函数大小为$f=2$,$s=2$,

利用最大池化层的另一个例子
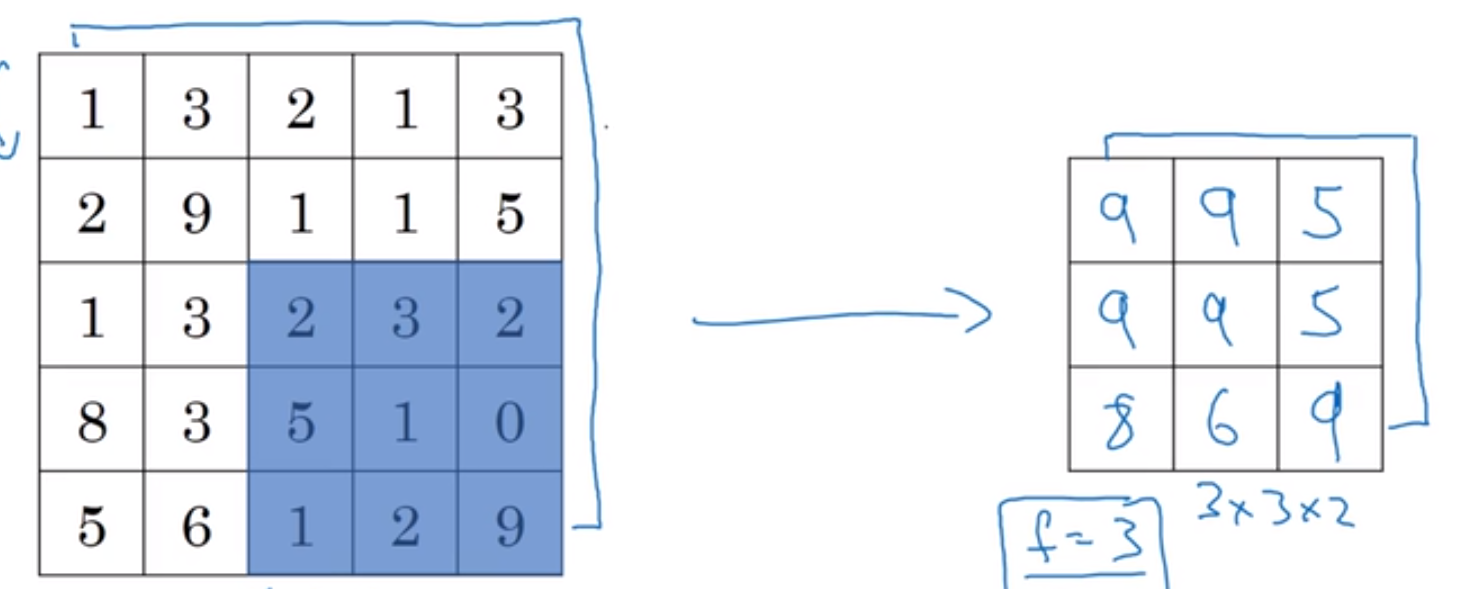
8 池化层简介
也有平均池化层的例子。但是一般上用最大池化层的情况较多。只在有限的情况之下(如深度很深的神经网络)
池化层的超级参数值为$f和s$,常用的值为$f=2 , s=2$。在最大池化时,很少用到Padding参数,但也有例外。(其中s为步长)
池化的输入输出基本维度和卷积层相同(只是池化层很少用到Padding参数),如下面图片,上面是输入维度,下面是输出维度。
tips:池化层没有参数需要学习,在反向传播中没有参数适用于最大池化。他只是计算神经网络中的某一层的静态属性,不需要学习。
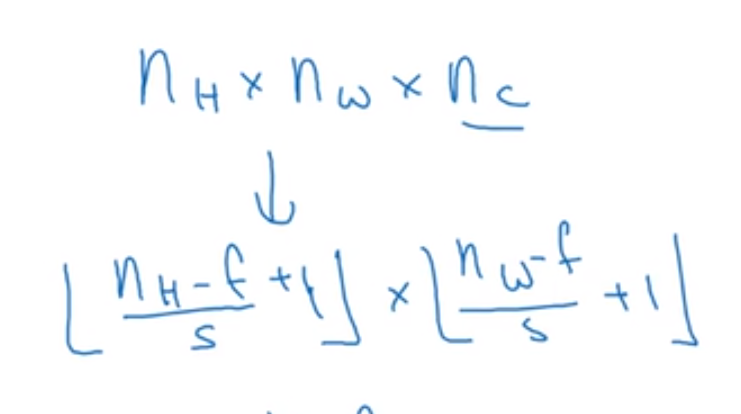
9 池化层举例
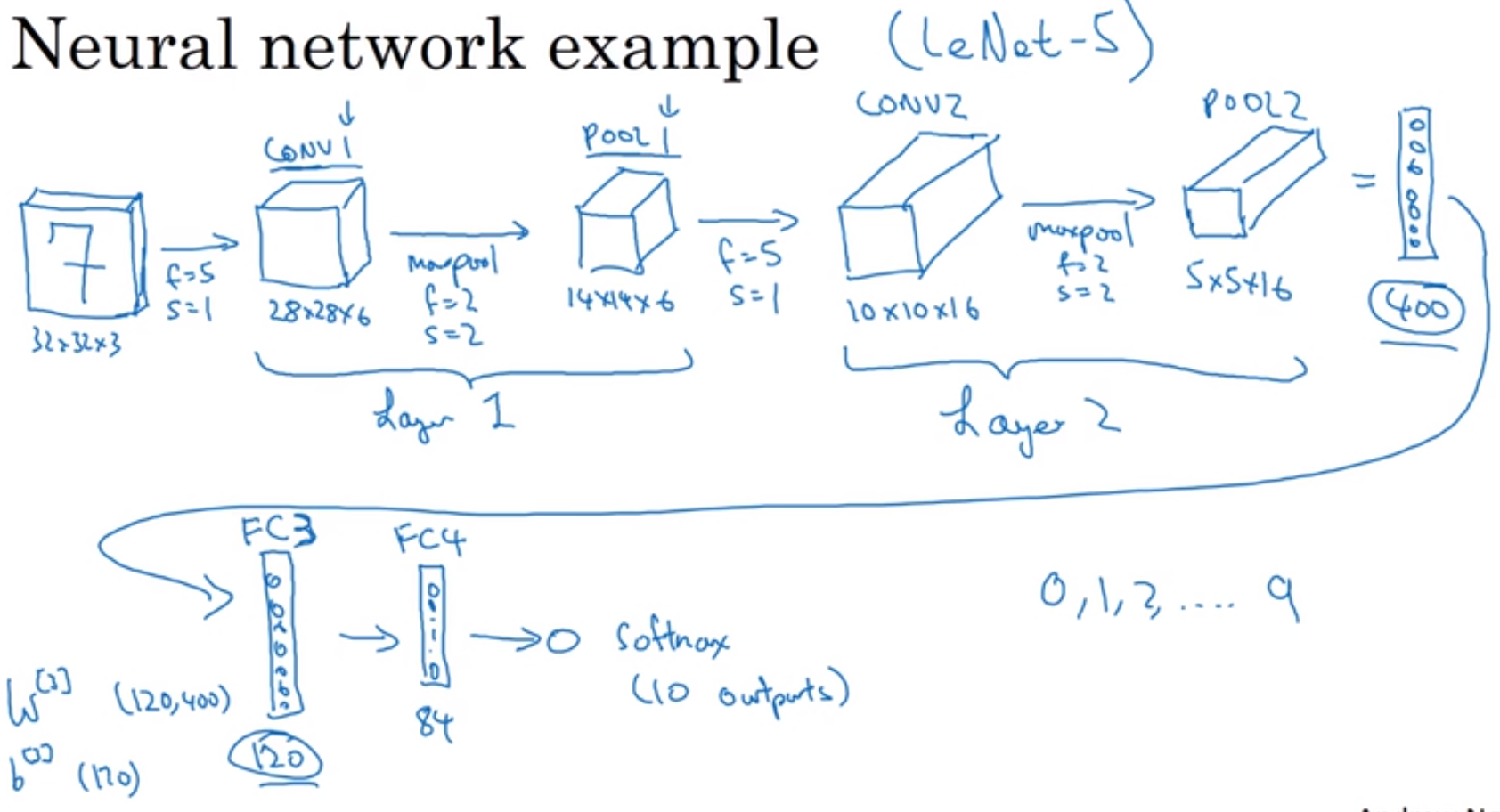
视频中老师用的模型和经典的LeNet-5很相似,灵感也来源于此。许多参数的选取都与之类似。
一个例子:
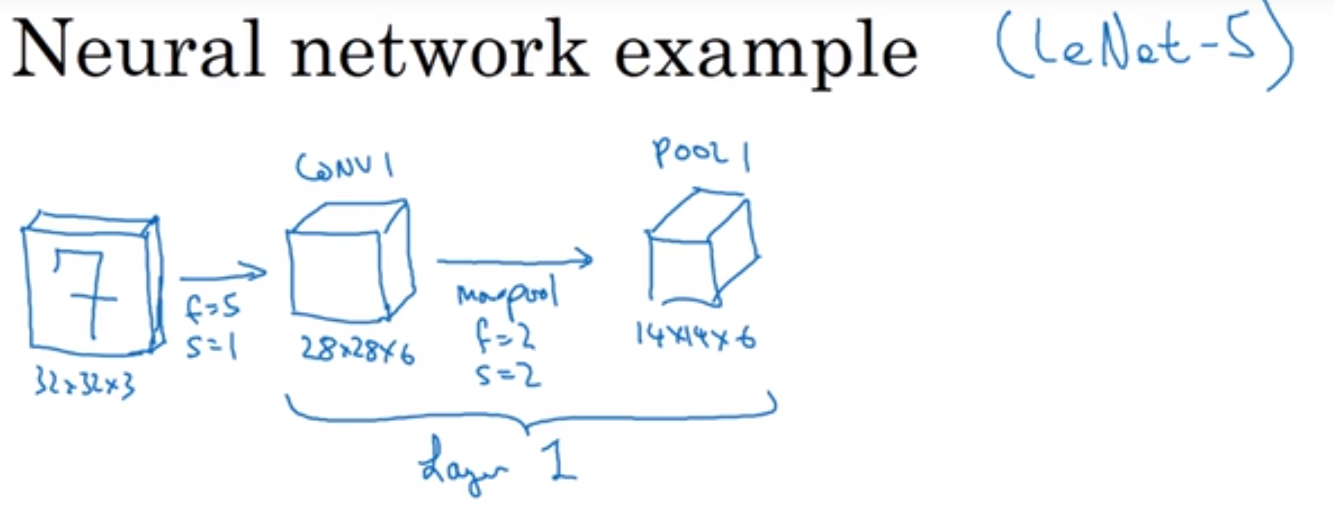
卷积层:输入$32*32*3 f=5 s=1 p=0$, 6 个过滤器,增加了偏差,应用了非线性函数,结果为$conv1 28*28*6$
池化层:$max pool f=2 s=2 p=0$,一个过滤器,最后结果为 $Pool1 14*14*6$
一般文献中会将有权重和参数的层作为一层,因为池化层没有参数和权重(只有一些超级参数),因此将这里的Pool1划分到Conv1中,两者作为一层,称为layer1(如下图)。
tips:也有可能将卷积层和池化层各作为一层,这只是标记术语不同。
进一步的例子,如下。对以上结果再卷积,再池化。
10 全连接层
全连接层作用:就是把分布式特征representation映射到样本标记空间,什么听不懂,那我说人话,就是它把特征respresentation整合到一起,输出为一个值。
以上一句话出自:https://www.zhihu.com/question/41037974
下图中,layer2是最后得到的数据,将$5*5*16=400$的数据展开称为一维向量,择有400个值,通过全连接层让400个变为120个(人为设定的值),再通过一次全连接层将120个变为84个。
对于$F_{c3}$这一层,由400个数的一维向量(设为$pool_v$),通过与维度为$120*400$的权重矩阵$W[3]$相乘再加上偏移$b$,$F_{c3}=W[3]*pool_v+b$,得到
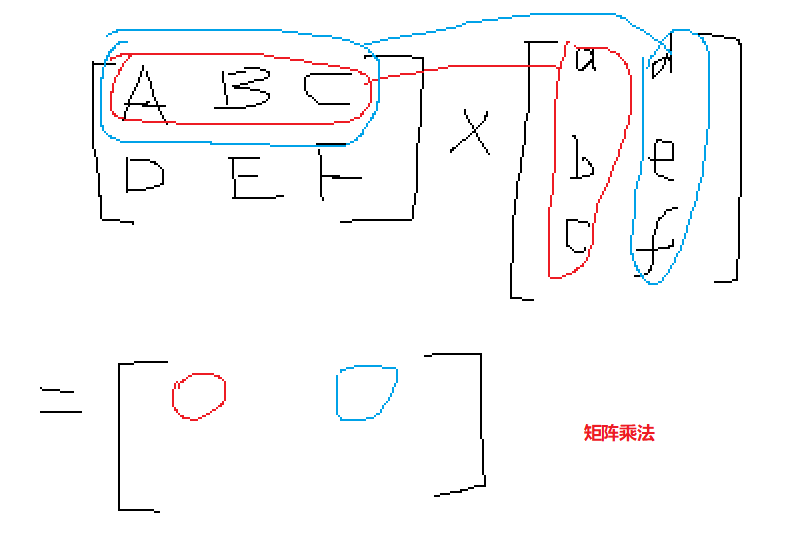
我竟然忘了矩阵乘法是啥,罪过,罪过。
小插入:softmax函数的作用 https://zhuanlan.zhihu.com/p/25723112
11 网络中不同层的激活值形状,大小和参数量
由图可见,激活值越来越小;池化层没有参数,在全连接层的参数是最多的。
如:在input处,激活函数的形状为$(32,32,3),size=32*32*3=3072$。则此处得到的图像(这里的就是输入图像)维度为$32*32*3$,总数据量为3072
如:在CONV1处,激活函数形状为$(28,28,8),size=28*28*8=6272$。则此处得到的图像维度为$28*28*28$,总数据量为6272

12 卷积的优点
卷积的优点:和之用全连接层相比,卷积层优势在于参数共享和稀疏矩阵。神经网络可以通过这两种机制减少参数,一边用更小的训练集来训练,防止过拟合。
参数共享:如一个垂直边缘检测的$3*3$的窗口,它能检测左上角的垂直边缘,就能检测右上角的垂直边缘,而且参数无需改变。
系数矩阵:还是一个垂直边缘检测,一个像素输出仅仅依赖于一个窗口罩住的九个像素,与其他输入的像素(或叫特征)没有关系。
13 神经网络的训练
训练神经网络需要做的就是梯度下降法(或者其他的方法,如含忡量的梯度下降,RMSProp,或其他),来减小代价函数,最终达到优化神经网络中的参数的目的。

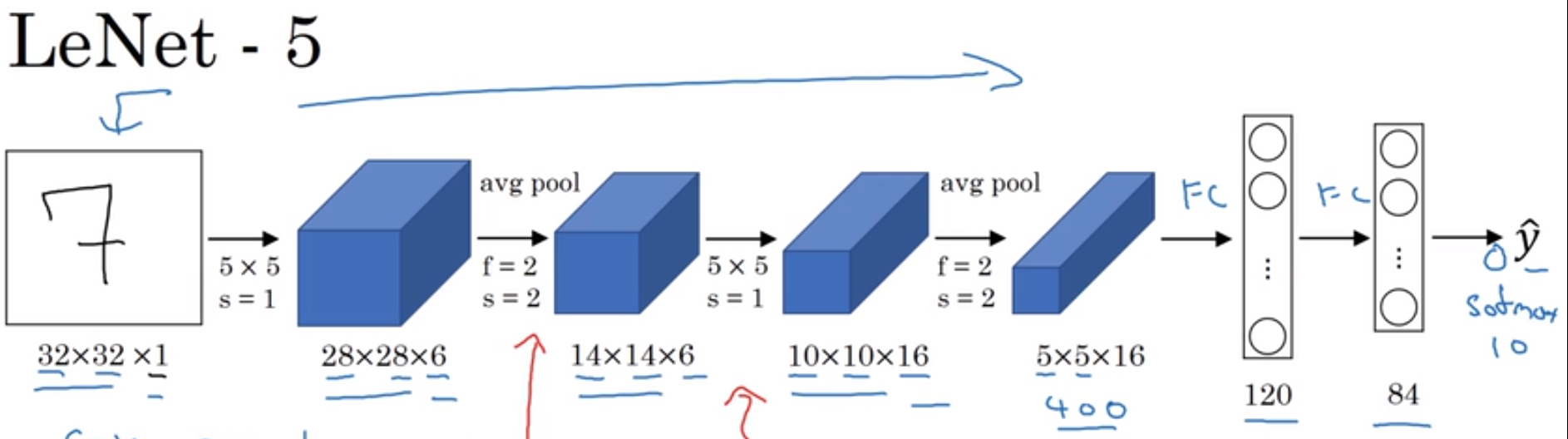
14 LeNet - 5 神经网络
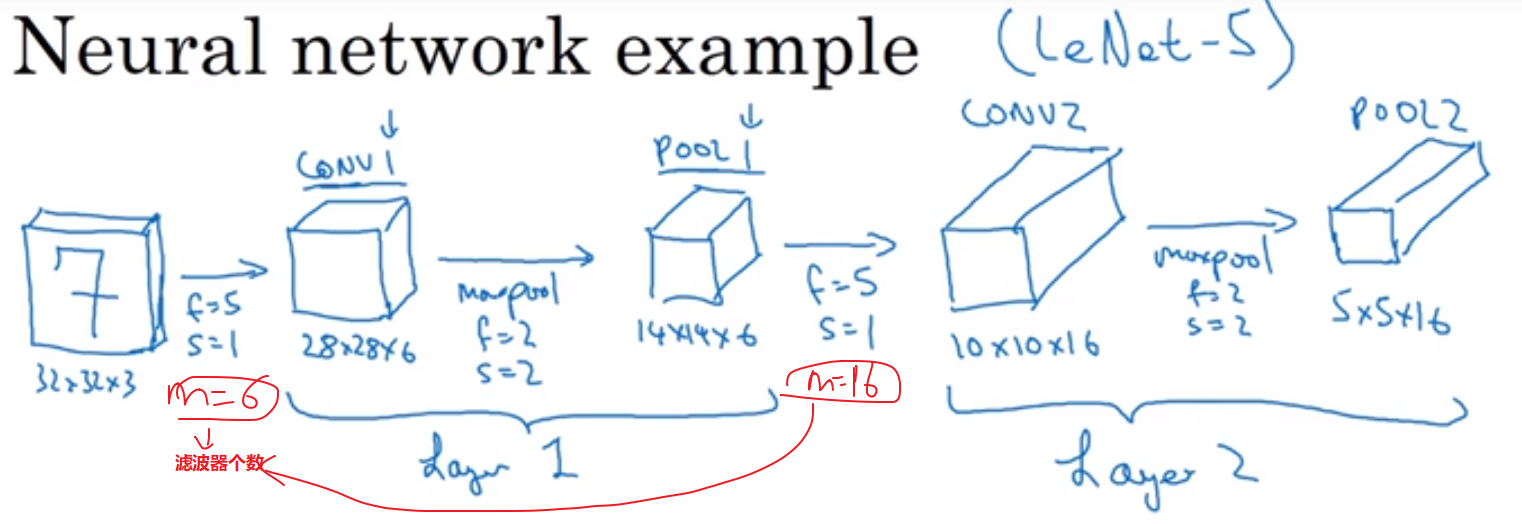
下图中的卷积过程中没有明确写出用到的滤波器数量。实际上,第一个卷积用了6个滤波器;第二个卷积用了16个滤波器。
tips:实际上,卷积中使用的滤波器的数量可以在下图中看出。卷积得到的结果图像的通道数,就是用到的滤波器个数。
因为一个三维(或多维)的滤波器最后得到的是一个通道的图像,有$n_c$个滤波器,就会有$n_c$个通道。
这里的s是卷积步长。f是窗口大小。
15 AlexNet 神经网络
下图的卷积神经网络中,卷积前后图像大小不变的原因是采用了same Padding,在卷积前对图像进行扩充。
最后是将卷积得到的数据展开成为一维,进入三次全连接层,最后经过Softmax函数看结果是1000个可能对象中的哪一个。
在下图的整个过程中间还会有ReLU激活函数。**回想一下** $g(z)$ $z=Wa+b$;

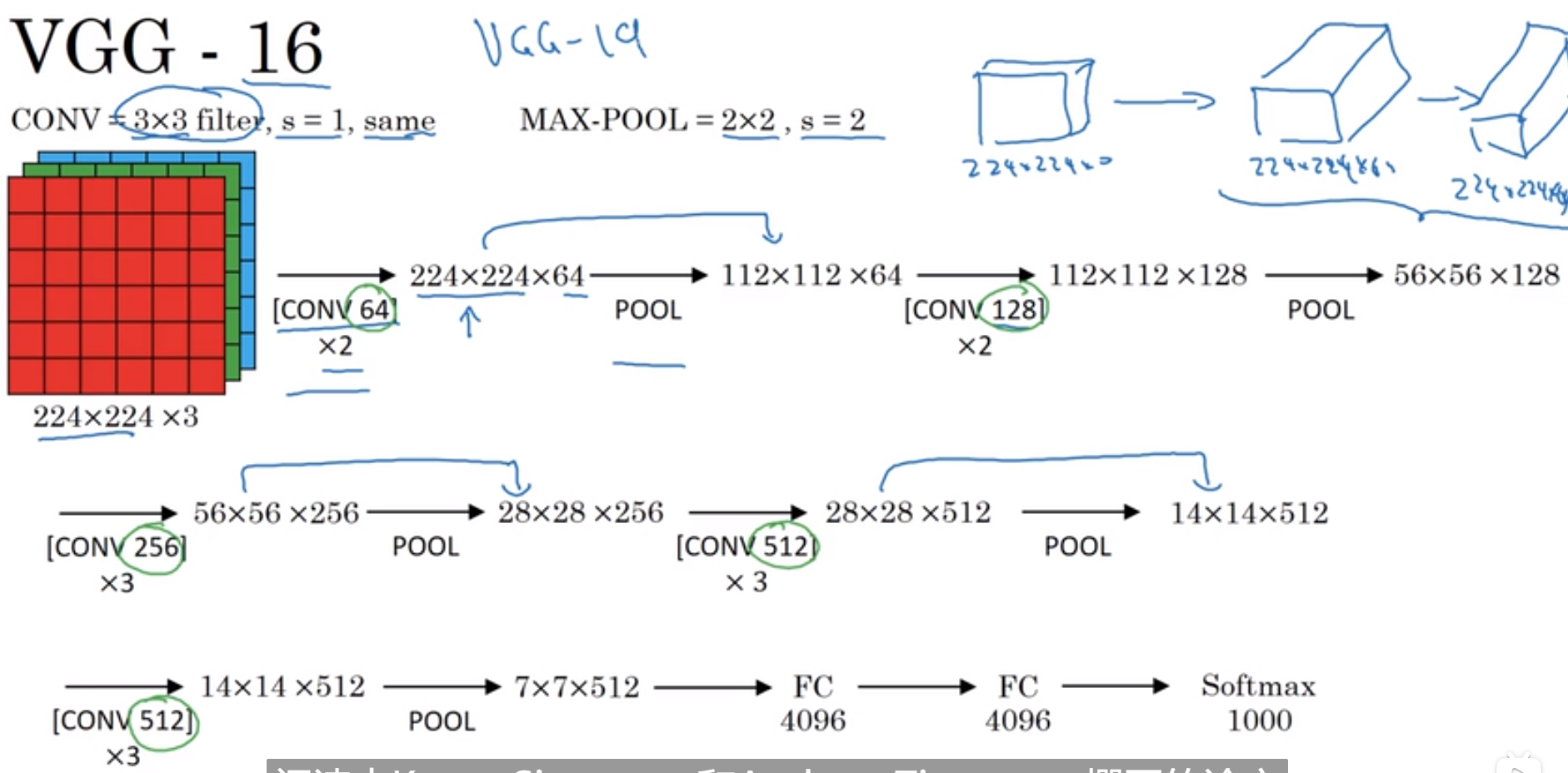
16 VGG - 16 神经网络
首先用$3*3$,步长为1 的过滤器构建卷积层,Padding参数为same
tips:这里的[CONV 64]代表的是用64个滤波窗口进行滤波,$*2$代表执行两次
17 ResNets(残差网络)
梯度消失和梯度爆炸:https://www.cnblogs.com/XDU-Lakers/p/10553239.html
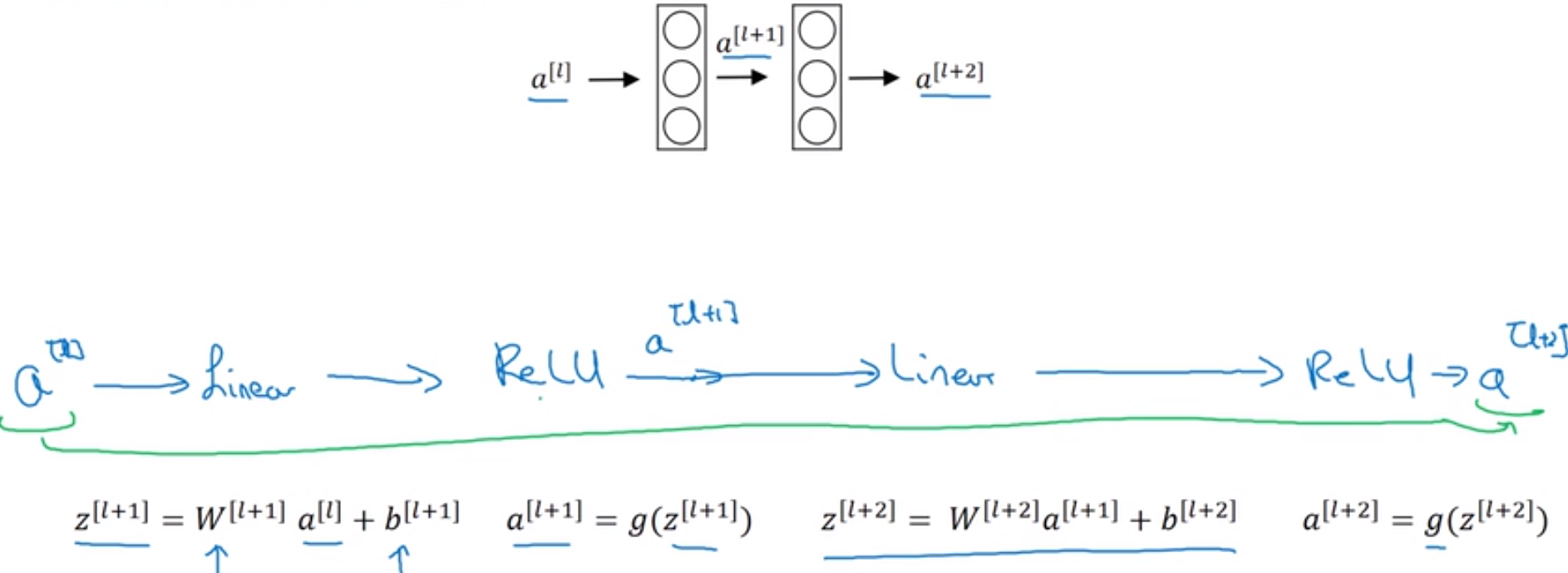
非残差的,正常的,最基本的激活函数样式,如下四行(不要把它当成是残差网络的基本组成,这是最基本神经网络的组成部分)
||| $a^{[l]} ightarrow{Liner}stackrel{z^{[l+1]}}{longrightarrow}{ReLU}stackrel{a^{[l+1]}}{longrightarrow}{Liner}stackrel{z^{[l+2]}}{longrightarrow}{z^{[l+2]}} ightarrow$
||| 其中Liner为线性激活,ReLU为非线性激活,$z^{[l+1]}$为线性激活结果;$a^{[l+1]}$为非线性激活结果,具体如下:
||| $z^{[l+1]}=W^{[l+1]}a^{[l]}+b^{[l+1]}$
||| $a^{[l+1]}=g(z^{[l+1]}) $
18 Residual block(残差块)
正常情况下:如下,一个两层神经网络,在L层进行激活。其运行模式按照如上方式进行
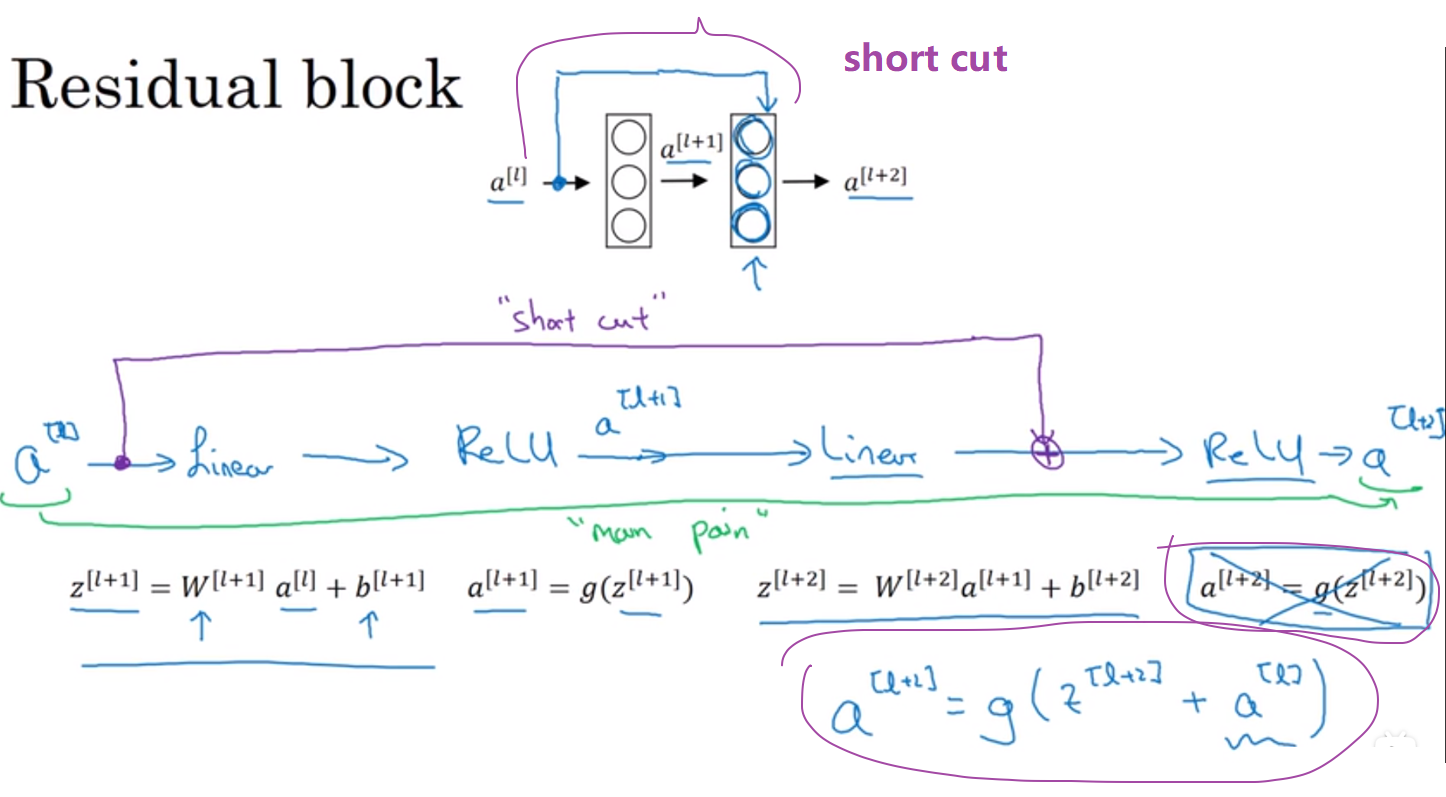
在残差网络中:有一些变化(注意图中紫色线和第二级的非线性激活之前)
这里$a^{[l]}$的信息直接通过“short cut”路径传达到后级的非线性激活之前,导致后级的非线性激活产生变化(加上了一个$a^{[l]}$)。
有时“short cut”(捷径)也称为“skip connection”(远调连接),指的就是a^{[l]}跳过一层或好几层从而将信息传递到神经网络的深层。
tips:图中表现的远跳连接的意义是把a^{[l]}放到后级的非线性激活之前,这一点要明白
残差网络图示
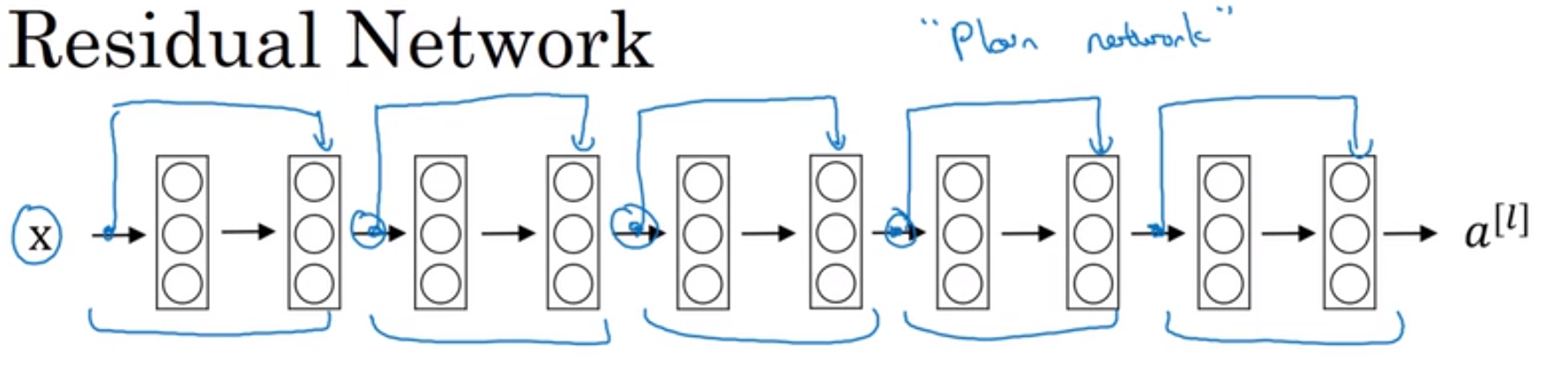
残差网络能够有效减小梯度消失和梯度爆炸这两个问题。
若残差块从前面给到后面的$a^{[l]}$和后面非线性激活函数用到的矩阵维度不一样,则要在$a^{[l]}$上乘以一个矩阵,即$W_s*a^{[l]}$
19 正则化项,$1*1$卷积的作用
机器学习中正则化项L1和L2的理解:https://blog.csdn.net/jinping_shi/article/details/52433975
$1*1$卷积的用处
一个例子:一个$28*28*192$的输入,池化层只能对它的高度和宽度进行压缩。但对于192个通道却没有效果,而32个$1*1*192$的卷积核可以使它的通道数变为32个。
当然也可用其他的滤波器个数,如192个(此时通道数量不变)。结论,$1*1$卷积可以用于降低通道数量
20 Inception 模块(通过学习选择所用的窗口以及相关参数)
Inception 模块:在不知道使用$1*1 3*3 5*5$的窗口的时候,可以通过这个模块学习得到参数(计算成本会增加)
以下图片指的是一个输入通过几个不同规格的滤波器,通过Padding滤波,将结果堆叠的结果。其中要注意的是,最后黄色是一种特殊的池化操作,它采用的是Padding滤波,$s=1$,很特殊。
tips:这里的几个规格的滤波器每次应用的数量是不同的。如$1*1$的滤波窗口是64个,$3*3$的是128个,这个可以从哪个后面彩色块的通道数值看出。
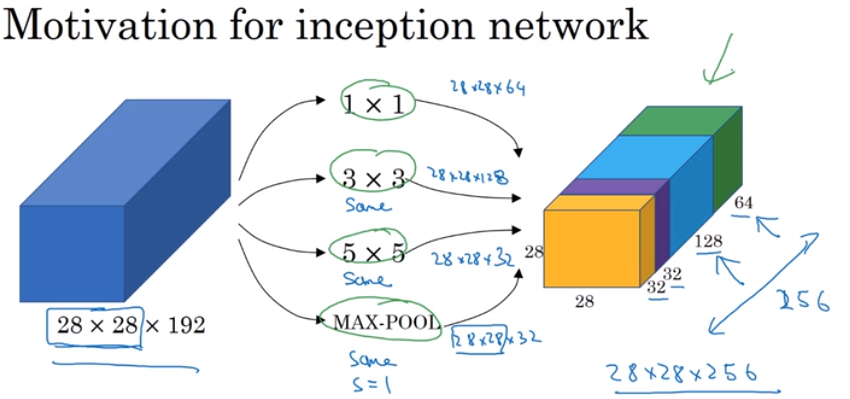
Inception network 不需要人为决定需要什么样的滤波窗口,而是人为的给出这些参数的可能值,由机器学习并决定最终用什么参数。(这样就会有一个计算成本的问题)
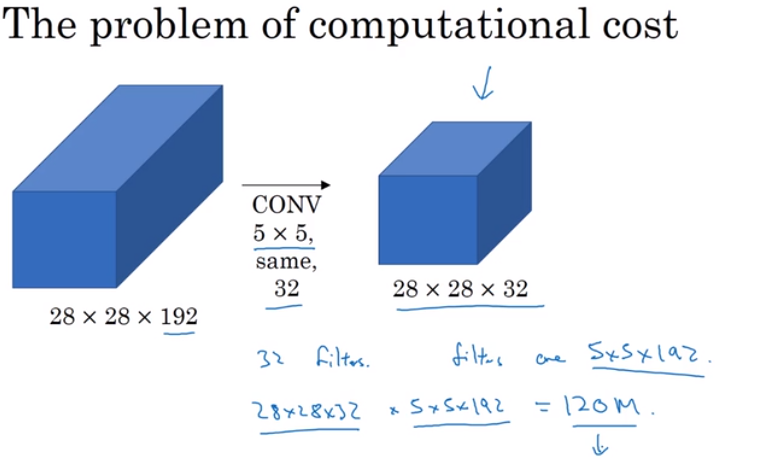
21 Inception 模块计算成本
Inception模块计算成本:只统计了一种类型窗口的计算成本
考虑从$28*28*192$通过32个$5*5*192$的窗口得到$28*28*192$的结果,其计算成本为 $计算次数*最后结果$<——>$(28*28*32)*(5*5*192)=120M$
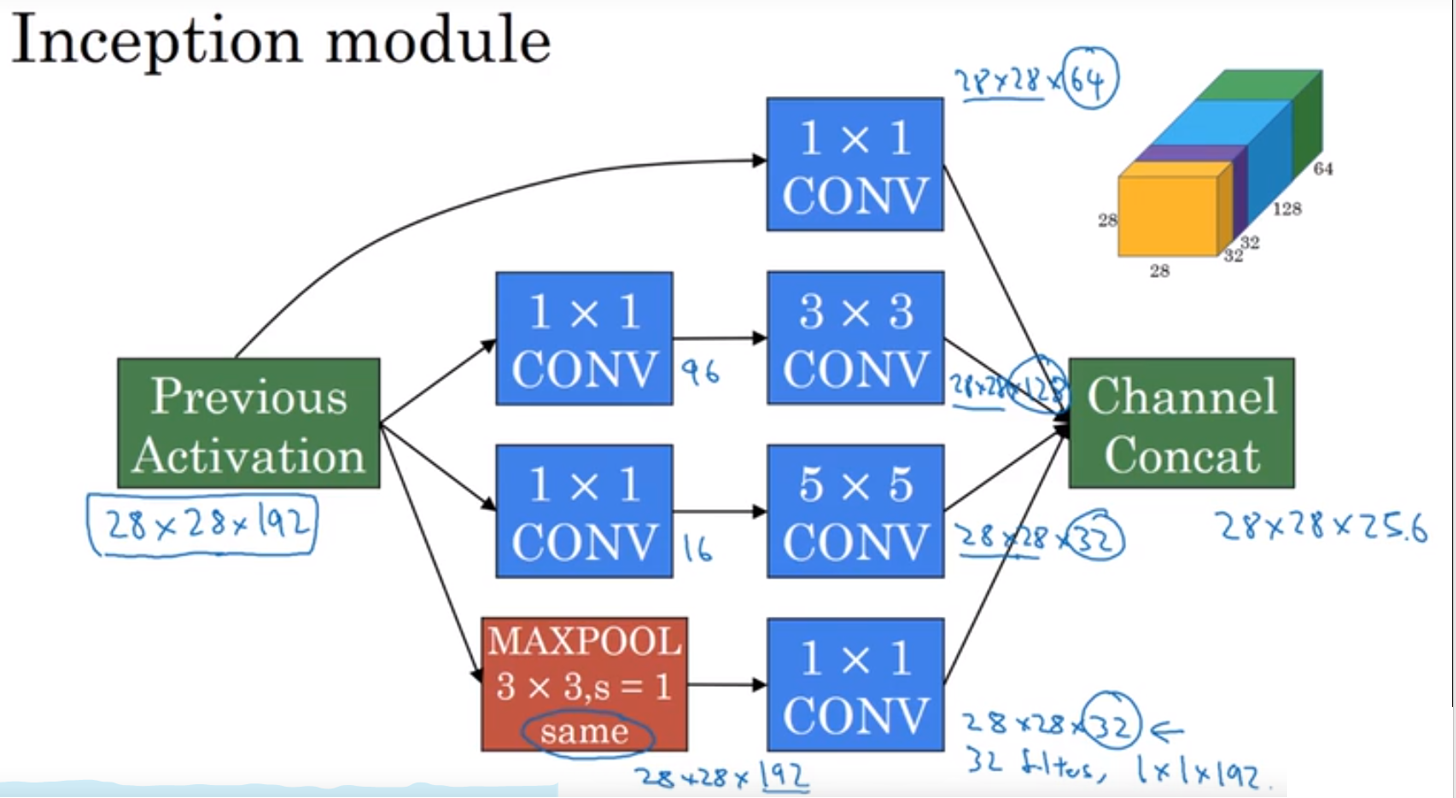
使用$1*1$窗口降低计算成本(只要使用这样的窗口瓶颈合理,则不会影响网络性能)
使用16个$1*1192$ 滤波窗口先进行处理,然后再使用32个$5*5*16$的窗口进行处理,最后得到的结果和上面一样,是$28*28*32$,但是最终的计算成本则为12.4M,计算成本大大降低。

tips:以上两次计算成本只统计了乘法,加法的数量与乘法运用次数近似相等。
22 Inception 网络
此网络中的额外$1*1$滤波器都是为了降低通道数,减少计算量。最后将得到的结果的通道合并起来
下面一张图片代表了Inception网络的基本构造
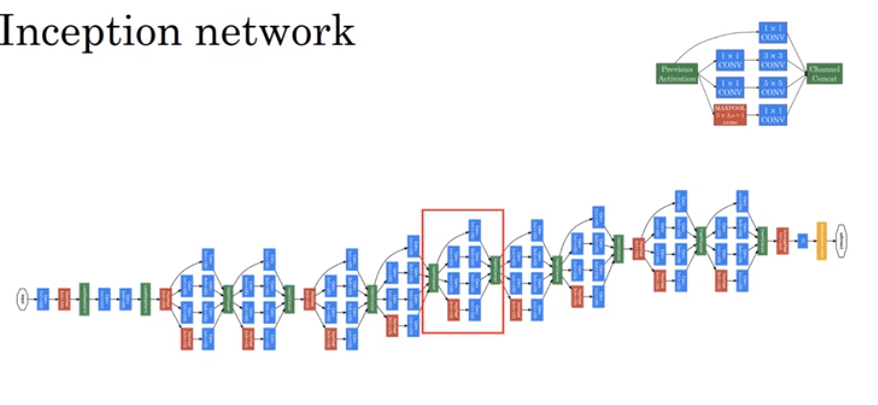
而实际上,网络的形状为以下所示,会加入一些预测分支,意味着中间层和隐藏层也会参与到最后的预测结果。

23 构建自己的工程
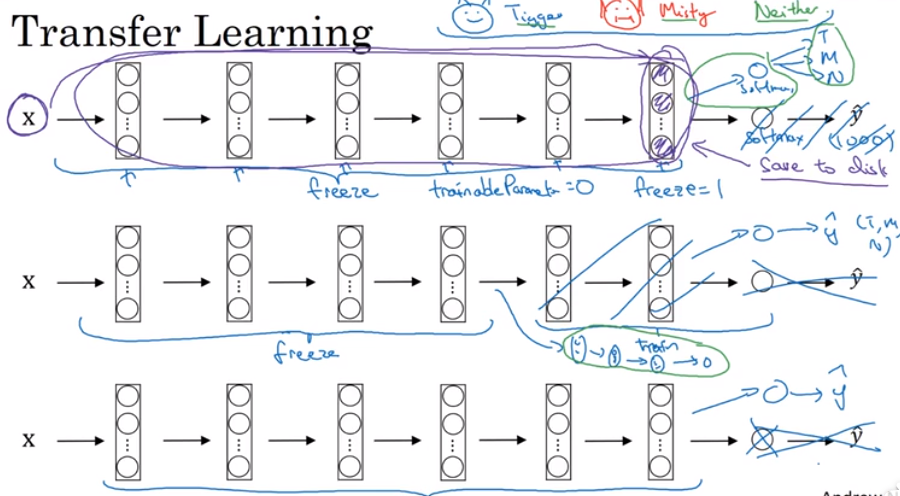
迁移学习:下载别人的模型,根据需要和实际情况冻结、改动部分,最后训练出自己的模型。(很适合在你又较小的数据集的情况)
神经网络的利用可以用别人训练好的卷积层、池化层、全连接层以及相关参数。可以自己训练Softmax层有关的参数。
当自己的训练集很小时,把别人训练好的卷积层当做一个固定函数(即冻结所有层),通过输入x得到函数运算的结果,不断训练自己的Softmax分类器。
当自己的训练集较大时,应该冻结更少的层来训练参数,这时要训练的参数除了Softmax分类器,还有没有被冻结的卷积层(也可以将这些层替换为自己设计的卷积层)
当自己的训练集很大时,极限情况下,可以用下载而来的卷积层的参数作为初始化,然后通过训练集训练自己的参数
小总结:自己的训练集越大,自己需要训练的越多。
tips:下面图片就对应了以上三种情况
24 数据增强
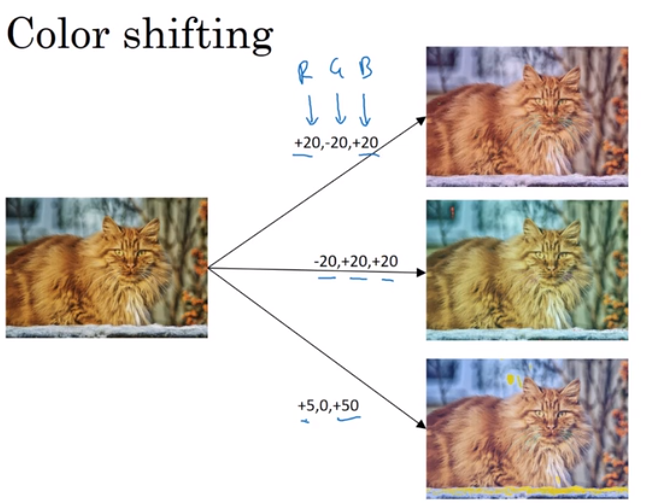
数据增强:包括镜像,剪裁,色彩转换等方法。用这些方法扩充自己的数据集,来提高训练网络的性能。(数据增强的方法很多,之前介绍的两种较为简单,应用较多)
数据增强介绍:https://zhuanlan.zhihu.com/p/41679153
tips:当然,对于随机剪裁,最好是要能看出这是个猫;对于颜色转换,需要按照一定的规则对三个通道的颜色进行处理。可能会用到主成分分析的思想对颜色进行改变。
主成分分析法(PCA)介绍:https://zhuanlan.zhihu.com/p/30145700

25 对象分类
对象分类:如下,将一张图片输入到卷积网络中,输出一个特征向量,将这个向量反馈给softmax单元来预测图片类型
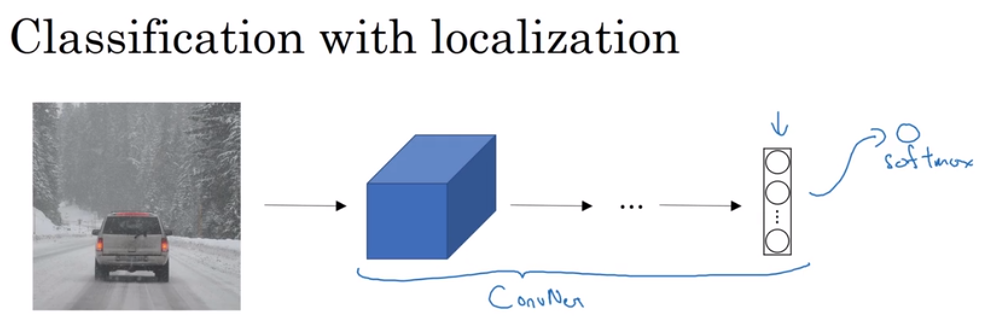
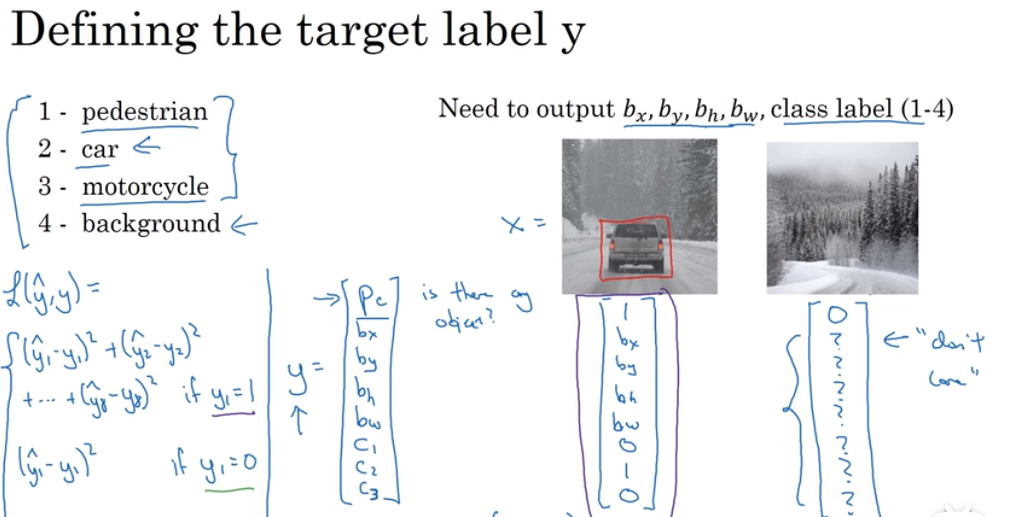
对于对象的分类定位:如下,有四个输出:行人,汽车,摩托车,背景(这里仅用单张图片中只有一个对象的例子)
对于最后的输出,$P_c$代表的是否是对象,输出y中:$P_c=1$代表的是对象,$b_x,b_y,b_h,b_w,b_w$用来定位对象坐标,$c_1,c_2,c_3$代表的是对象的具体分类。
tips:这里应用到的代价函数示例采用简单的平方差,若$y_1=1$,即相应的$P_c=1$,则采用8个元素的平方差的和,若$y_1=0$,则说明没有对象,误差就是$y_1$自己的平方差。
使用卷积神经网络,可以使用一定大小的滑动窗口,通过一定的步长表里整个图像,同时将每个滑动窗口的内容输入到神经网络中。通过判别每个窗口中是否有目标对象来检测整幅图片。

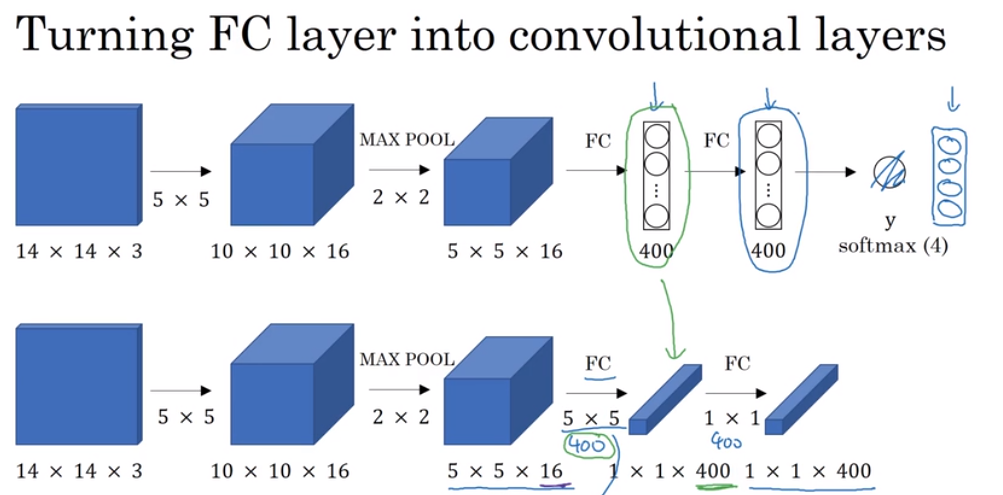
26 将全连接层转化为卷积运算
为了构建滑动窗口的卷积应用,需要知道如何把神经网络的全连接层转化为卷积层。
将全连接层转化为卷积层:在第一个$F_c$处,有400个$5*5*16$的窗口,卷积后得到的结果在数学上就是一个全连接层;再用400个$1*1*400$的窗口卷积,得到下一层的全连接层。
交并比 :交并比(Intersection-over-Union,IoU),目标检测中使用的一个概念,是产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率,即它们的交集与并集的比值。最理想情况是完全重叠,即比值为1。
交并比介绍:https://blog.csdn.net/TaylorMei/article/details/79119147
目标检测中的非极大值抑制:https://blog.csdn.net/shuzfan/article/details/52711706
暂时笔记做到这里,ho~ho~ho~