总结原因
程序通过UPDATE XX SET WHERE ID IN (a,b,c) 一次性锁大量id,其中某些id被其他session锁住了。当超过innodb_lock_wait_timeout会try restarting transaction
现象
早上来到公司检查公司邮件,发现报错邮件了。
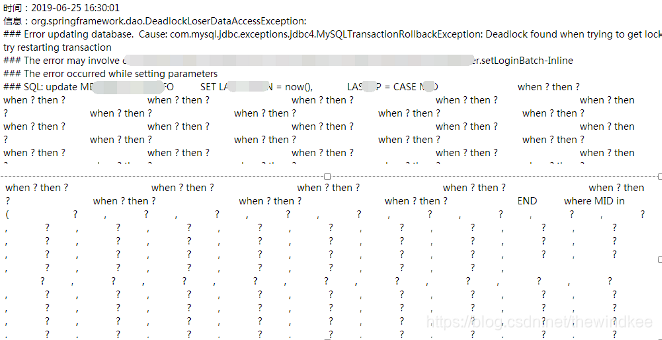
怎么可以忽视, 当然要检查一番。?
已知信息
- 死锁等待一般是A欲锁 a,b B欲锁b a,相互持有对方的锁。
- 联想到昨天同事在线上执行了大量update操作,听说还挺耗时。
- 同事执行的是
update xx set a=b where id =x;这种语句,且没有通过事务执行。 执行update的时候会在主键id上加排他锁,一次只锁一行。
猜想原因
程序中update的时候用到 MID IN () 这种语句想要一次性锁住多行,其中某些id被同事执行的update锁住了。
疑问
如果update xx set a=b where id =x;这种语句一次性锁一行, 那么很快就会释放, 不存在
本地测试
- 开启事务,锁住一条记录。
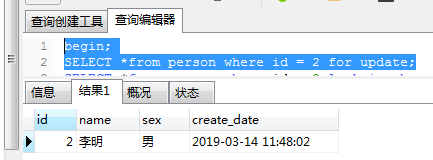
- 尝试锁住多条
直接加写锁

用update让其自动加写锁
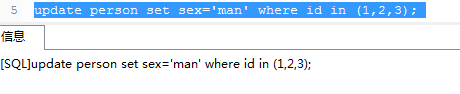
超时后报try restarting transaction , 与线上的情况一致了。

那么try restarting transaction是由什么引起的呢?
查看资料后得知 InnoDB 行锁等待默认超时时间为50秒,可以通过set innodb_lock_wait_timeout xx变更。
执行set innodb_lock_wait_timeout 5后,果然是5秒才报错。try restarting transaction
查询行锁等待情况
查看行锁冲突的线程
select * from information_schema.INNODB_LOCKS;

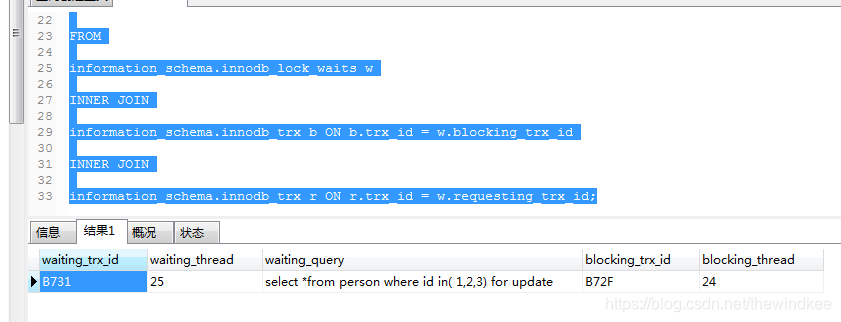
查看被阻塞的线程
SELECT
r.trx_id waiting_trx_id,
r.trx_mysql_thread_id waiting_thread,
r.trx_query waiting_query,
b.trx_id blocking_trx_id,
b.trx_mysql_thread_id blocking_thread
FROM
information_schema.innodb_lock_waits w
INNER JOIN
information_schema.innodb_trx b ON b.trx_id = w.blocking_trx_id
INNER JOIN
information_schema.innodb_trx r ON r.trx_id = w.requesting_trx_id;
解决方法
1.修改innodb_lock_wait_timeout 使其等待更久,更有机会执行成功。
2.手动执行补偿错误的语句。
3.最好避免在线上执行过长的语句。