作者
张煜,15年加入腾讯并从事腾讯广告维护工作。20年开始引导腾讯广告技术团队接入公司的TKEx-teg,从业务的日常痛点并结合腾讯云原生特性来完善腾讯广告自有的容器化解决方案
项目背景
腾讯广告承载了整个腾讯的广告流量,并且接入了外部联盟的请求,在所有流量日益增大的场景下,流量突增后如何快速调配资源甚至自动调度,都成为了广告团队所需要考虑的问题。尤其是今年整体广告架构(投放、播放)的条带化容灾优化,对于按需分配资源、按区域分配资源等功能都有着更强的依赖。
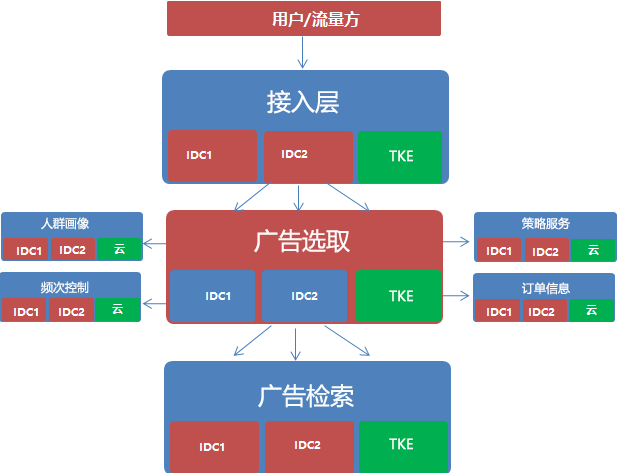
在广告内部,播放流系统承载了整个广告播出的功能,这里的稳定性直接决定了整个腾讯广告的收入,以下为架构图:
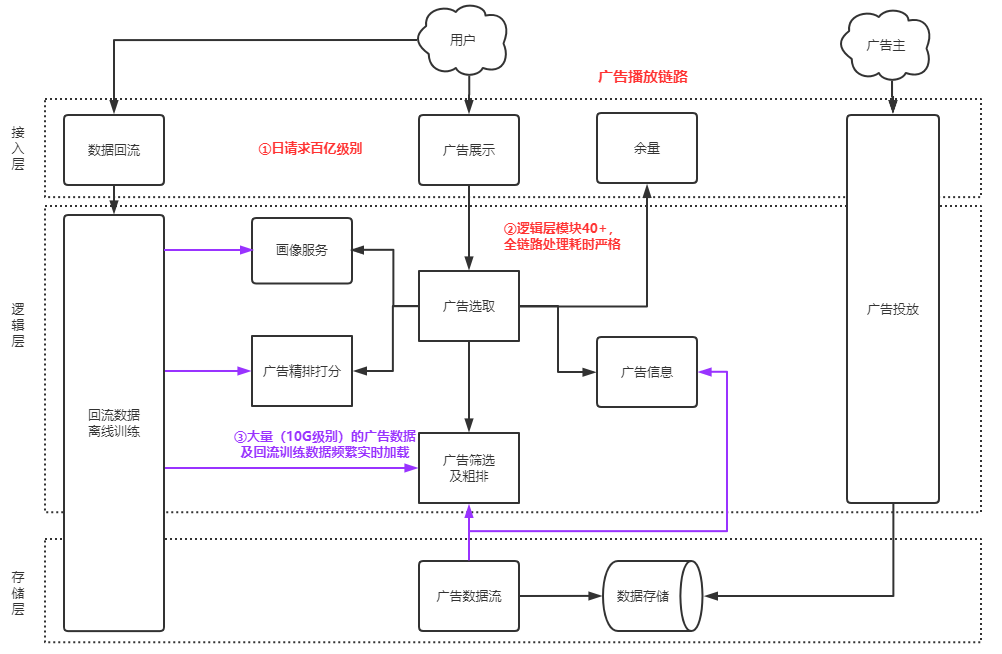
业务特点:
- 请求量大,日均请求量近千亿级别,机器量占了AMS自有机器量的60%以上,整体性能即使是少量的上下波动都会涉及大量机器的变动。
- 链路拓扑复杂及性能压力极大,整个播放链路涉及40+的细分模块。在100~200毫秒(不同流量要求有差异)的极短时间内,需要访问所有模块,计算出一个最好的广告。
- 计算密集型,大量的使用了绑核和关核能力,来面对上百万个广告订单检索的压力。
上云方案选型
在20年腾讯广告已经在大规模上云,主要使用的是 AMD 的 SA2 cvm 云主机,并且已经完成了对网络、公司公共组件、广告自有组件等兼容和调试。在此基础上,基于 CVM 的 Node 云原生也开始进行调优和业务使用,弹性伸缩、Docker 化改造,大量使用各种 PAAS 服务,充分发挥云的高级功能。
以下为广告使用的 TKE 架构:
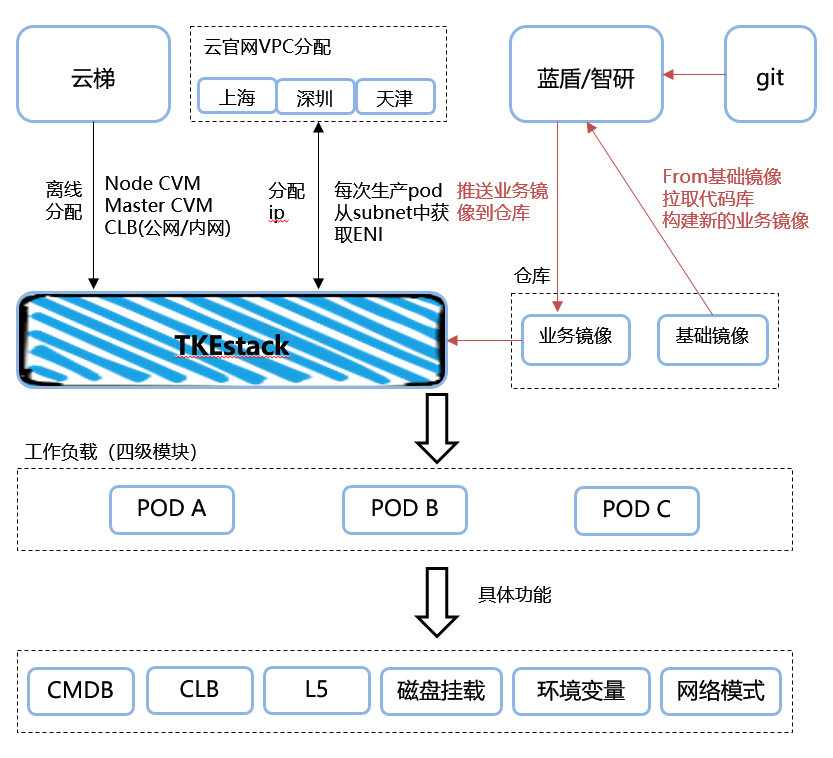
- 前期资源准备(左上):从腾讯内部云官网平台申请 CVM 和 CLB 等资源,并且同时云官网申请 master,node,pods 所需要的 subnet 网段( subnet 是区分区域的,例如深圳光明,需要注意 node 和 pods 在区域上的网段分配,需要一致)。CVM 和 CLB 都导入至 TKEx-teg 中,在选择FIP模式的时候,产生的 PODS 从分配好的 subnet 中获取自己的 EIP。
- 仓库及镜像的使用(右上):广告运维侧提供基础镜像(mirrors.XXXXX.com/XXXXX/XXXXXXX-base:latest),业务在 from 基础镜像的同时,拉取 git 后通过蓝盾进行镜像 build,完成业务镜像的构建。
- 容器的使用模式(下半部分):通过 TKEx-teg 平台,拉取业务镜像进行容器的启动,再通过 clb、北极星等服务进行对外使用。
容器化历程(困难及应对)
困难一:通用性
(1)面对广告84个技术团队,如何实现所有业务的适配
(2)镜像管理:基础环境对于业务团队的透明化
(3)腾讯广告容器配置规范
困难二:CPU密集型检索
(1)广告订单数量:百万级
(2)绑核:各个应用之间的 CPU 绑核隔离
(3)关核:关闭超线程
困难三:有状态服务升级中的高可用
(1)广告资源在容器升级过程中的持续可用
(2)在迭代、销毁重建过程中的持续高可用
通用性
1. 广告基础镜像介绍
广告运维侧提供了一套覆盖大部分应用场景的基础镜像,其中以 XXXXXXX-base:latest 为基础,这里集成了原先广告在物理机上面的各个环境配置、基础 agent、业务 agent 等。
并且基于这个基础镜像,提供了多个业务环境镜像,镜像列表如下:
mirrors.XXXXX.com/XXXXX/XXXXXXX-base:latest
mirrors.XXXXX.com/XXXXX/XXXXXXX-nodejs:latest
mirrors.XXXXX.com/XXXXX/XXXXXXX-konajdk:latest
mirrors.XXXXX.com/XXXXX/XXXXXXX-python:3
mirrors.XXXXX.com/XXXXX/XXXXXXX-python:2
mirrors.XXXXX.com/XXXXX/XXXXXXX-tnginx:latest
具体镜像使用情况如下:
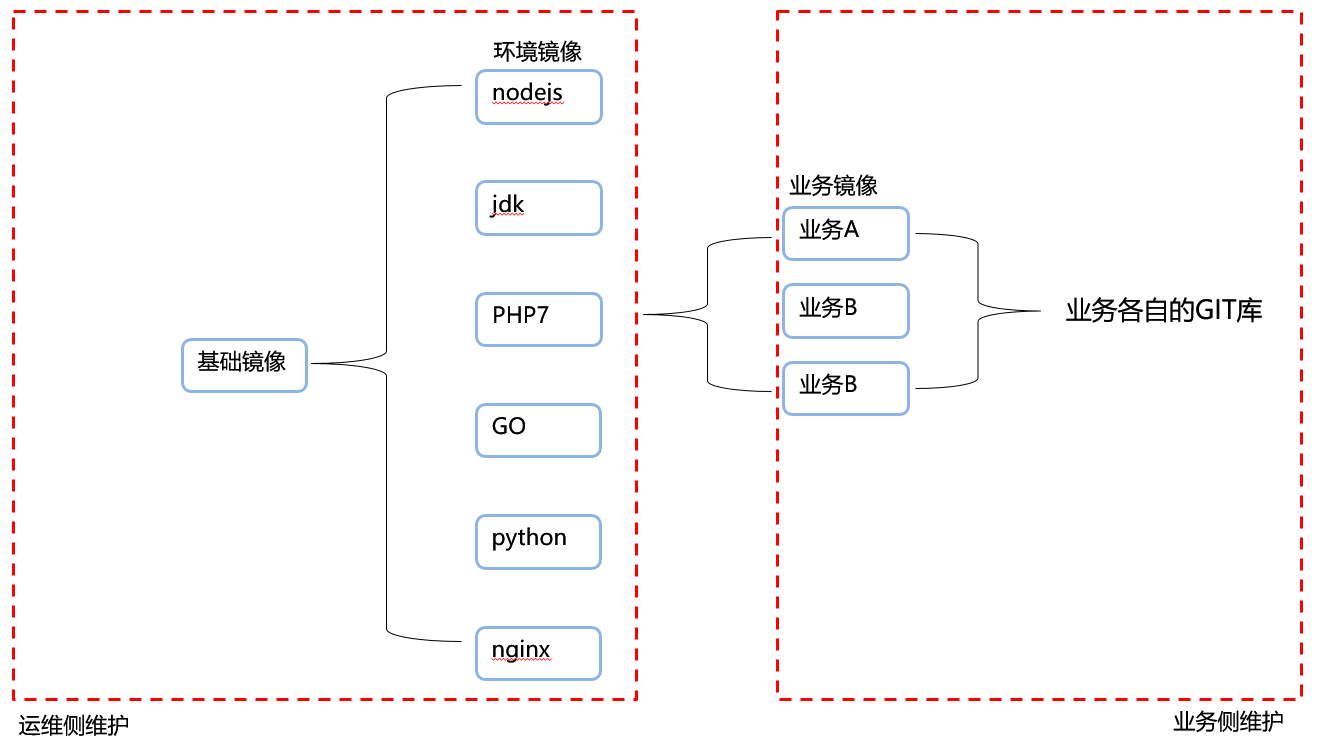
在广告的基础镜像中,由于权限集设置未使用到 systemd,所以使用启动脚本作为1号 PID,并且在基础镜像中内置了一份通用的腾讯通用 Agent & 广告独有 Agent 的启动脚本,在业务镜像启动过程中,可以在各自的启动脚本中选择是否调用。
2. 容器化CI/CD
原先大量使用了其他平台的 CD 部分,但现在使用 TKE 后,其他平台已经无法使用。而 TKEx-teg 上的持续化集成部分对于自动化流水线实现较弱,需手动参与,所以在广告内部引入的 CI/CD 方案是腾讯内部的持续化集成和持续化部署方案:蓝盾。
这里全程实现流水线发布,除了审核外无需人工参与,减少人为因素的问题影响。
stage1:主要使用手动触发、git 自动触发、定时触发、远程触发
-
手动触发:容易理解,需要手动点击后开始流水线。
-
自动触发:当 git 产生 merge 后,可自动触发该流水,适用于业务的敏捷迭代。
-
定时触发:定时每天某个时间点开始整个流水线的触发,适用于 oteam 协同开发的大型模块,预定多少时间内迭代一次,所有参与的人员来确认本次迭代的修改点。
-
远程触发:依赖外部其他平台的使用,例如广告的评审机制在自己的平台上(Leflow),可以在整个发布评审结束后,远程触发整个流水线的执行。
stage2 & stage3:持续化集成,拉取 git 后进行自定义的编译
蓝盾提供了默认的CI镜像进行编译,不进行二进制编译的可以选择默认(例如 php、java、nodejs等),而后台业务腾讯广告内部大量使用 blade,通常使用 mirrors.XXXXXX.com/XXXXXX/tlinux2.2-XXXXXX-landun-ci:latest 作为构建镜像,此镜像由腾讯广告效能团队提供,内部集成了腾讯广告在持续化集成过程中的各种环境和配置。
编译完成后通过镜像插件,依赖 git 库中的 dockerfile 进行镜像 build,然后推送至仓库中,同时保留一份在织云中。
stage4:线上灰度 set 发布,用于观察灰度流量下的数据表现。通过集群名、ns 名、workload 名来对某个工作负载进行镜像 tag 的迭代,并且使用一份 TKEx-teg 内部的 token 进行认证。
stage5:确认 stage4 没问题后,开始线上的全量,每次都经过审核确认。
stage6 & stage7:数据统计。

另外有一个蓝盾中机器人群通知的功能,可以自定义把需要告知的流程信息,推送到某个企业微信群中,以便大家进行确认并审核。
3. 腾讯广告容器配置规范
广告内部的母机都是用的腾讯云星星海 AMD(SA2),这里是90核超线程 cpu+192G 内存,磁盘使用的是高速云硬盘3T,在日常使用中这样的配置这个机型是腾讯云现阶段能提供的最大机型(已经开始测试SA3,最高机型配置会更大)。
-
所以业务在使用的时候,不建议 pods 核数太大(例如超过32核),由于TKE亲和性的默认设置会尽量在空闲的母机中拉取各个容器,这样在使用到中后期(例如集群已经使用了2/3)导致的碎片化问题,会导致超过32核的 pods 几乎无法扩容。所以建议用户在拉取容器的时候如果可以横向扩容,都是把原有的高核服务拆分成更多的低核 pods(单 pods 核数减半,整体 pods 数两倍)。
-
在创建 workload 的时候,对日志目录进行 emptyDir 临时目录的挂载,这样可以保证在升级过程中该目录不会丢失数据,方便后续的问题排查。(销毁重建仍旧会删除该目录下的所有文件)

如果是已经上线的 workload,则可以通过修改 yaml 来增加目录的挂载:
- mountPath: /data/log/adid_service
name: adid-log
volumes:
- emptyDir: {}
name: adid-log
- 在腾讯广告内部,大量使用了条带化功能,也就是服务不在受限于上海、深圳、天津这样的范围。条带化可以做到更细化的区分,例如上海-南汇这样以机房为单位的部署,这样可以实现容灾的实现(大部分的网络故障都是以机房为单位,这样可以快速切到另一路)。也可以实现条带化部署后的耗时减少,例如同上海的两个机房,由于距离的原因自带3ms的耗时,在大包传输的过程中,跨机房部署的耗时问题会被放大,在广告内部有出现10ms的 gap 出现。
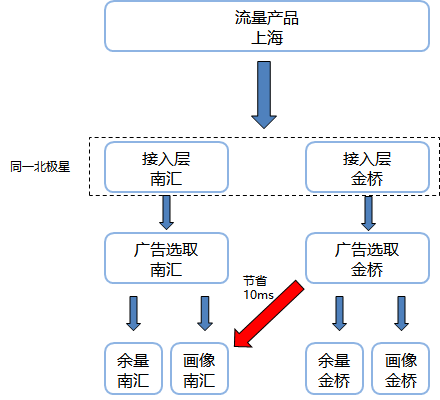
所以在广告的 TKE 条带化使用过程中,我们会去通过 label 的方式来指定机房选择,腾讯云对各个机房的 CVM 都默认打了 label,可以直接调用。

存量的 workload 也可以修改 yaml 来进行强制的调度。
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- "370004"
- 广告内部后台都是建议使用4~16核的容器配置,前端平台大多使用1核,这样可以保证在集群使用率偏高的场景下,也可以进行紧急扩容。并且如果希望亲和性强制隔离各个 pods,也可以使用如下配置进行隔离(values 为具体的 workload 名称):
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- proxy-tj
topologyKey: kubernetes.io/hostname
weight: 100
4. HPA设置
在容器化的使用过程中,有两种方式可以面对业务流量的突增。
- 设置容器的request和limit,request资源可以理解为确定100%可以分配到业务的,而Limit则是超卖的资源,是在buffer池中共享的资源部分。这样的好处在于每个业务可以配置平时正常使用的request资源,当发生流量突增时由limit部分的资源来承担超过request之后的性能问题。
注:但这里的超卖并不是万能的,他有两个问题也非常明显:
- 在当前node剩余使用的资源如果小于limit设定的值,会发生PODS自动迁移到其他node。2)如果需要使用到绑核功能,是需要qos的功能,这里强制request和limit必须设置一样的配置。

- 设置自动扩容,这里可以根据大家各自的性能瓶颈来设置阈值,最后来实现自动扩容的功能。
大部分的业务都是cpu的性能为瓶颈,所以通用方式可以针对cpu的request使用率来设置扩容

百万广告订单检索
1. 广告核心检索模块
广告对于每个流量都存在一个站点集的概念,每个站点集分了不同的 set,为了区分开各个流量之间的影响和不同的耗时要求。在20年我们对每个模块都拆出了一个 set 进行了 CVM 的上云,在此基础上,21年我们针对核心模块 sunfish 进行了容器化的上云。这个模块的特点就是 CPU 高度密集型的检索,所以他无法使用超线程(超线程的调度会导致耗时增加),并且内部的程序都进行了绑核处理(减少多进程之间的 CPU 调度)。
2. 容器绑核
这里是广告最大的一个特性,而且也是 TKE 和 CVM/物理机的最大区别。
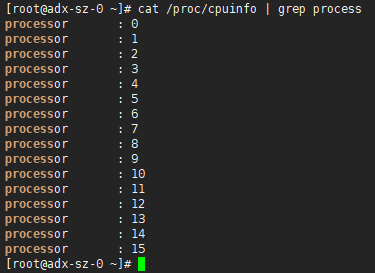
在 CVM/物理机的场景中,虚拟化技术是可以从 /proc/cpuinfo 中获取到正确的 cpu 单核信息,所以在原先的业务绑核过程中,都是从 /proc/cpuinfo 中获取 cpu 的核数和信息,进行每个程序的绑核操作。
但在容器中 cpu 信息产生了很大的偏差,原因是 /proc/cpuinfo 是根据容器自身的核数进行的排序,但这个顺序并不是该容器在母机上的真实cpu序列,真实的 cpu 序列需要从 /sys/fs/cgroup/cpuset/cpuset.cpus 中获取,例如下图两个举例:
/proc/cpuinfo 中的 CPU 序号展示(虚假):
/sys/fs/cgroup/cpuset/cpuset.cpus 中的 CPU 序号展示(真实):

从上面两张图中可以看到,/proc/cpuinfo 中只是按照分配到的 cpu 核数进行了一个排序,但并不是真正对应母机的核数序列,这样在绑核的过程中,如果绑定了15号核,其实是对母机的15号核进行绑定,但母机的第15个CPU并不是分配给了该容器。
所以需要从 /sys/fs/cgroup/cpuset/cpuset.cpus 中获取在母机中真正对应的 cpu 序列,才能实现绑核,如上图2。并且可以通过在启动脚本中加入下面的命令,可以实现对 cpu 真实核数的格式转换,方便绑定。
cpuset_cpus=$(cat /sys/fs/cgroup/cpuset/cpuset.cpus)
cpu_info=$(echo ${cpuset_cpus} | tr "," "
")
for cpu_core in ${cpu_info};do
echo ${cpu_core} | grep "-" > /dev/null 2>&1
if [ $? -eq 0 ];then
first_cpu=$(echo ${cpu_core} | awk -F"-" '{print $1}')
last_cpu=$(echo ${cpu_core} | awk -F"-" '{print $2}')
cpu_modify=$(seq -s "," ${first_cpu} ${last_cpu})
cpuset_cpus=$(echo ${cpuset_cpus} | sed "s/${first_cpu}-${last_cpu}/${cpu_modify}/g")
fi
done
echo "export cpuset_cpus=${cpuset_cpus}" >> /etc/profile
source /etc/profile 调用环境变量,转换后的格式如下:

注意:绑核依赖 qos 配置(也就是 request 和 limit 必须设置成一致)
3. 关闭超线程
超线程在大部分场景下都是打开的,但在计算密集型的场景下需要关闭,此处的解决方法是在申请CVM的时候就选择关闭超线程。
然后对关核的母机做污点并打上 label,让普通的拉取不会拉到关核母机,在需要分配关核资源的时候,在 yaml 中打开容忍和设置 label,就可以获取到相应的关核资源。
yunti 资源申请时的关核配置:

有状态服务升级中的高可用
无状态容器的升级最为简单,业务端口的可用即为容器的可用。
但有状态业务的启动较为复杂,需要在启动脚本中完成状态的前期准备工作。在广告这里主要涉及在广告订单资源的推送和加载。
1. 广告资源在容器升级过程中的持续可用
容器的升级较于物理机最大的区别就在于容器会销毁原有的容器,然后从新的镜像中拉起新的容器提供服务,原有容器的磁盘、进程、资源都会被销毁。
但广告这里的广告订单资源都是百万级别,文件如果在每次升级都需要重新拉取,会直接导致启动过慢,所以我们在容器中都加入了临时挂在目录。


这样的挂载方式,可以让容器在升级过程中保留上述目录下的文件,不需要重新拉取。但 emptyDir 只能在升级场景下保留,销毁重建仍旧会销毁后重新拉取,以下为存量服务直接修改 yaml 的方法:
volumeMounts:
- mountPath: /data/example/
name: example-bf
volumes:
- emptyDir: {}
name: example-bf
2. 升级过程中的业务高可用
在业务迭代的过程中,其实有两个问题会导致业务提供了有损服务。
-
如果针对 workload 关联了负载均衡,这里容器在执行启动脚本的第一句话就会变成 running 可用状态,这时候会帮大家投入到关联过的负载均衡中,但这时候业务进程并未就绪,尤其是有状态服务必须得完成前置的状态后才可以启动。这时候业务就会由于加入了不可用的服务导致业务报错。
-
在升级的过程中,除了 deployment 模式的升级外,其他都是先销毁原有的容器,再拉取新的容器服务。这时候就产生了一个问题就是,我们在升级的时候是先从关联过的负载均衡里剔除,然后立马进入到销毁阶段。如果上游是L5调用那其实并不能快速同步到该 pods 已经剔除,会继续往下游已经销毁的容器中发送请求,这时候整个业务就会报错。
所以我们这里的一个最主要的思路就是:
- 如何把业务的状态,和容器状态进行绑定。
- 在升级/销毁重建的过程中,是否可以做一个后置脚本,在销毁之前我们可以做一些逻辑处理,最简单的就是sleep一段时间。
这里我们引入业务的两个升级的概念:
-
探针就绪
-
后置脚本
1 )探针就绪
需要在workload创建的时候,选择针对端口进行做就绪探测,这样在业务端口启动后才会投入到关联好的负载均衡里。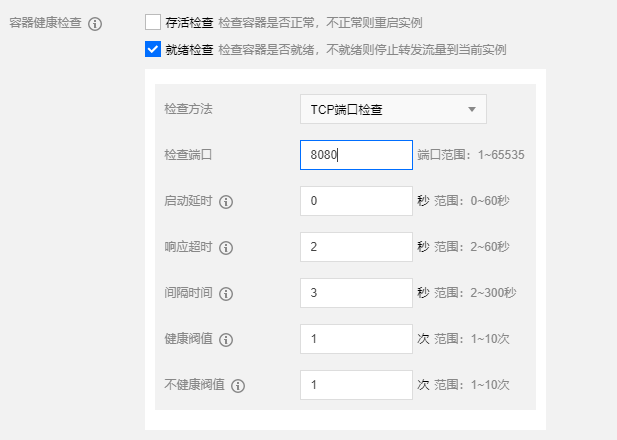 也可以在存量的workload中修改yaml
也可以在存量的workload中修改yaml
readinessProbe:
failureThreshold: 1
periodSeconds: 3
successThreshold: 1
tcpSocket:
port: 8080
timeoutSeconds: 2
出现类似的unhealty,就是在容器启动后,等待业务端口的可用的过程
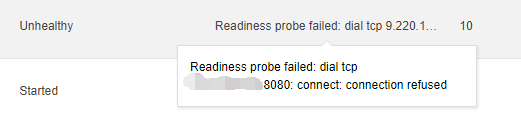
2 )后置脚本
后置脚本的核心功能就是在从关联的负载均衡中剔除后,到销毁容器之间,可以执行一系列业务自定义的动作。
执行顺序是:提交销毁重建/升级/缩容的操作 → 剔除北极星/L5/CLB/service → 执行后置脚本 → 销毁容器
最简单的一个功能就是在上游使用L5调用的时候,在剔除L5后sleep 60s,可以让上游更新到该pods剔除后再进行销毁操作。
lifecycle:
preStop:
exec:
command:
- sleep
- "60"
lifecycle:
preStop:
exec:
command:
- /data/scripts/stop.sh
长期的使用经验来看,主要问题在L5这方面,如果是大流量的服务,那sleep 60s 内就行,如果是请求量较小的,希望一个报错都没的,需要 sleep 90s。
成果展示
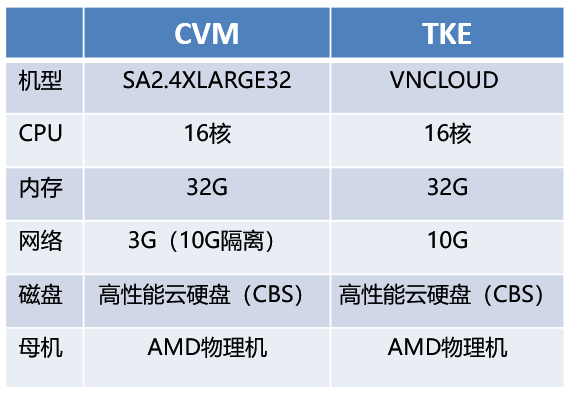
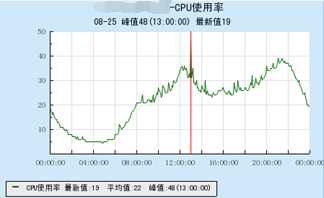
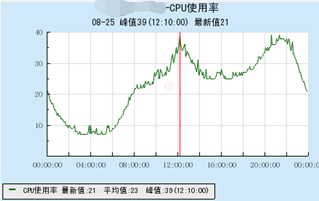
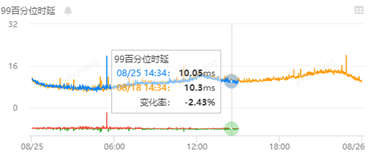
CVM 和 TKE 的使用率和耗时对比
这里在相同配置下,对比了普通机器 CVM 和 TKE 容器之间的 CPU 和耗时,可以看到基本没太大差异,耗时也无变化。
CVM:

TKE:
整体收益
结语
不同于其他从底层介绍云原生的分享,本文主要从业务角度,来介绍云原生在大型线上服务中的优势和使用方法,并结合腾讯广告自有的特点及策略,来实现腾讯广告在高并发、自动化等场景下的容器化实践。
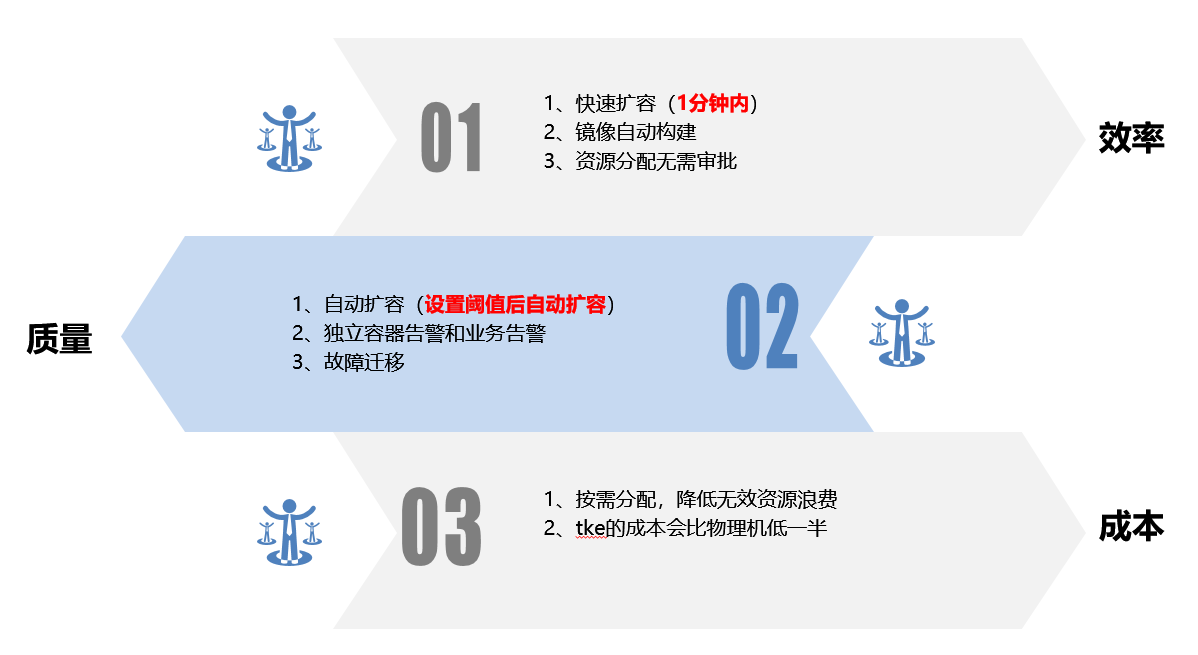
对于业务团队来说,任何的工作都是从质量、效率以及成本出发,而云原生则是能从这三个方面都有所提升,希望未来能有更多来自于我们腾讯广告的分享。
容器服务(Tencent Kubernetes Engine,TKE)是腾讯云提供的基于 Kubernetes,一站式云原生 PaaS 服务平台。为用户提供集成了容器集群调度、Helm 应用编排、Docker 镜像管理、Istio服务治理、自动化DevOps以及全套监控运维体系的企业级服务。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
