一.概念
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
-
若关键字为k,则其值存放在f(k)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数,按这个思想建立的表为散列表。
-
对不同的关键字可能得到同一散列地址,即k1≠k2,而f(k1)=f(k2),这种现象称为冲突(英语:Collision)。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数f(k)和处理冲突的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为散列表,这一映射过程称为散列造表或散列,所得的存储位置称散列地址。
-
若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数(Uniform Hash function),这就是使关键字经过散列函数得到一个“随机的地址”,从而减少冲突。实际工作中需视不同的情况采用不同的哈希函数,通常考虑的因素有:· 计算哈希函数所需时间· 关键字的长度· 哈希表的大小· 关键字的分布情况· 记录的查找频率1.直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a·key + b,其中a和b为常数(这种散列函数叫做自身函数)。若其中H(key)中已经有值了,就往下一个找,直到H(key)中没有值了,就放进去。2. 数字分析法:分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。3. 平方取中法:当无法确定关键字中哪几位分布较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为哈希地址。这是因为:平方后中间几位和关键字中每一位都相关,故不同关键字会以较高的概率产生不同的哈希地址。 [1]例:我们把英文字母在字母表中的位置序号作为该英文字母的内部编码。例如K的内部编码为11,E的内部编码为05,Y的内部编码为25,A的内部编码为01, B的内部编码为02。由此组成关键字“KEYA”的内部代码为11052501,同理我们可以得到关键字“KYAB”、“AKEY”、“BKEY”的内部编码。之后对关键字进行平方运算后,取出第7到第9位作为该关键字哈希地址,如下图所示关键字内部编码内部编码的平方值H(k)关键字的哈希地址KEYA11052501122157778355001778KYAB11250102126564795010404795AKEY01110525001233265775625265BKEY02110525004454315775625315
4. 折叠法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。移位叠加是将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。5. 随机数法:选择一随机函数,取关键字的随机值作为散列地址,即H(key)=random(key)其中random为随机函数,通常用于关键字长度不等的场合。6. 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p,p<=m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。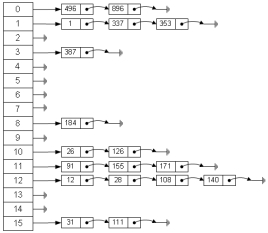
2.代码实现过程
1.员工
public class Emp { int id; String name; Emp next;//默认为null; public Emp(int id, String name) { this.id = id; this.name = name; } }
2.员工的链表
public class EmpLinkedList { private Emp head ;//头指针指向第一个节点 直接指向第一个 /*添加 * 1.添加雇员时id是自动增长 * 因此直接加入到链表最后*/ public void add(Emp emp){ if (head==null){//第一次添加 head=emp; return; } Emp cur = head; while (true){ if (cur.next==null){//链表最后 break; } cur = cur.next;//后移 } //直接将emp 加入链表 cur.next=emp; } /*遍历*/ public void list(int no){ if (head==null){//链表为空 System.out.println("第"+(no+1)+"链表为空"); return; } System.out.print("当"+(no+1)+"前链表信息为:"); Emp cur = head; while (true){ System.out.printf(" =>id=%d name=%s ",cur.id,cur.name); if (cur.next==null){//链表最后 break; } cur = cur.next;//指针后移 } System.out.println(); } /*利用id查询*/ public Emp findById(int id){ if (head==null){//链表为空 return null; } Emp cur = head; while (true){ if (cur.id ==id){ break; } if (cur.next==null){//遍历当前链表最后没有找到 cur=null; break; } cur = cur.next; } return cur; } /*删除*/ }
3.编写哈希表管理多条链表
public class HashTab { private EmpLinkedList[] empLinkedListArr; private int size;//一个有多少条链表 /*构造器*/ public HashTab(int size){ empLinkedListArr= new EmpLinkedList[size]; this.size=size; //有问题 不要忘了分别初始化每一个链表 for (int i = 0; i <size ; i++) { empLinkedListArr[i] = new EmpLinkedList(); } } /*散列函数绝定id对应到那个链表取余*/ public int hashFun(int id){ return id % size; } /*添加*/ public void add(Emp emp){ //根据员工的id 找到应该放到那条链表 int empLinkedListArrNO = hashFun(emp.id); //添加到对应的链表中 empLinkedListArr[empLinkedListArrNO].add(emp); } /*遍历*/ public void list(){ for (int i = 0; i < size; i++) { empLinkedListArr[i].list(i); } } /*查询*/ public void findById(int id){ //根据员工的id 找到应该放到那条链表 int empLinkedListArrNO = hashFun(id); Emp emp = empLinkedListArr[empLinkedListArrNO].findById(id); if (emp!=null){ System.out.printf("在第%d条链表中找到雇员id = %d ",empLinkedListArrNO+1,id); }else { System.out.println("哈希表中没有找到该雇员"); } } /*删除*/ //TODO }
4.进行测试
public class HashTabDemo { public static void main(String[] args) { //创建hash表 HashTab hashTab = new HashTab(7); String key=""; Scanner scanner = new Scanner(System.in); while (true){ System.out.println("a:添加雇员"); System.out.println("l:遍历雇员"); System.out.println("e:退出程序"); System.out.println("f:查找雇员"); key=scanner.next(); switch (key){ case "a": System.out.println("请输入Id:"); int id = scanner.nextInt(); System.out.println("请输入姓名: "); String name = scanner.next(); Emp emp = new Emp(id,name); hashTab.add(emp); break; case "l": hashTab.list(); break; case "f": System.out.println("请输入查找的Id:"); id = scanner.nextInt(); hashTab.findById(id); break; case "e": scanner.close(); System.exit(0); break; default: break; } } } }