都说SpringDataJpa只适合单表,其实SptringDataJpa的缺陷就是不好优化查询效率,但是如果对用户量小的项目来着,SpringDataJpa还是挺好的。这方面知识还是比较少的,在这里做一个记录。
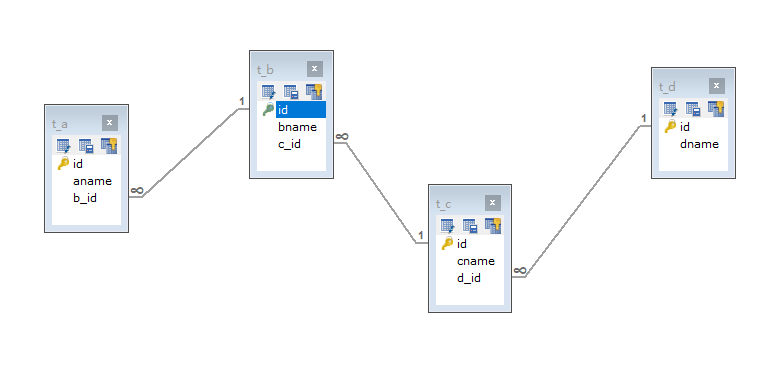
我建四个表,把这四个表通过主外键管理。
enti
@Data @Entity @Table(name = "t_a") class A{ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; private String aname; @OneToOne(cascade = CascadeType.ALL) @JoinColumn(name = "b_id") private B b; } @Data @Entity @Table(name = "t_b") class B{ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; private String bname; @OneToOne(cascade = CascadeType.ALL) @JoinColumn(name = "c_id") private C c; } @Data @Entity @Table(name = "t_c") class C{ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; private String cname; @OneToOne(cascade = CascadeType.ALL) @JoinColumn(name = "d_id") private D d; } @Data @Entity @Table(name = "t_d") class D{ @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; private String dname; }
建完之后是这样的(模拟开发中的多表)
数据建好之后去创建对象A的mapper
public interface AMapper extends JpaRepository<A,Integer> , JpaSpecificationExecutor<A> { }
接下来给四个表添加一条数据,我就简单点儿创了。由于springdatajpa的级联,所以创建a表的数据就会把其他数据也填到对应的表中。
@SpringBootTest class DemoApplicationTests { @Autowired private AMapper mapper; @Test void contextLoads() { D d = new D(); d.setDname("ddd"); C c = new C(); c.setD(d); c.setCname("ccc"); B b = new B(); b.setC(c); b.setBname("bbb"); A a = new A(); a.setB(b); a.setAname("aaa"); mapper.save(a); } }
执行成功后进行一下查询

然后我们假定一个场景,用d的dname属性去查找a的数据。就用到了连接查询了。
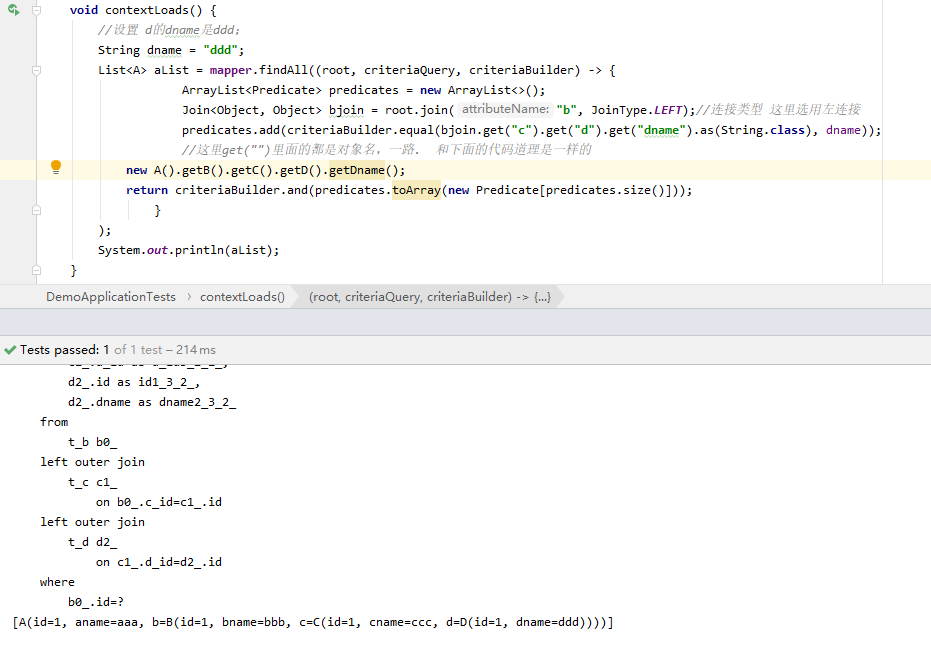
道理就是上图这个样子的,如果还有什么问题 可以留言给我