公司的ORM用的是EF,比较重量级的一个工具了,写查询方法时是用的LINQ TO SQL的形式,前些时觉得关于分页查询有些不对劲,昨天特意深究了一下。
先看一个基础仓储类定义的一个查询列表的公共方法:
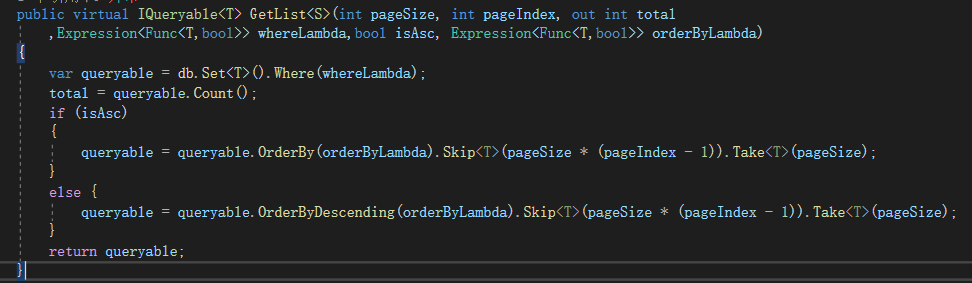
参数部分就不说了,如果有对泛型T和表达树不熟悉的萌新可以去看我前面写过的一片博文。这里主要看方法体内部实现细节:
首先定义了一个queryable的对象接收where后的查询结果集,然后做一次count统计(用于分页),紧接着在这个对象上进行OrderBy、Skip、Take等操作,最后返回处理过后的结果集。从开发的角度讲,我们把初步过滤后的查询结果赋值给一个对象,后面再对对象进行过滤查询,是很符合我们常用思维的,避免多次连接数据库。对C#比较熟悉的朋友可能就知道,queryable对象自被创建并赋值的那刻起就存在了内存之中,后续的所有查询其实就是在这部分内存里去过滤数据,所以是没有重新连接库的,查询效率相对较高。
而我的疑问也在于此。queryable对象存在内存里了,如果返回的结果集很大, 就会很占内存,通常,我们在获取分页列表时,都是获取分页后的数据,而这里,where后是获取了过滤后的所有数据,此时是没有带上分页的,也就是说第一行代码,queryable对象存储了过滤后的所有数据。起初我觉得可能我猜测错误,EF怎么可能做这种事,搞出一个假分页?是否在where的时候并没有执行查询,而是在后面的OrderBy,Skip等操作以后才连库执行的查询?但是如果是这样的话,total又是如何统计出总数的?
这就是矛盾所在,为了验证where后究竟有没有查询,我写了一个测试方法调用GetList,断点调试执行到total=queryable.Count()时,total是0,表示此时断点在这行但是还没开始执行,那上一行代码肯定执行过了,监测queryable,是有值的,数据也能展开出来,这个时候可以证明第一行代码过后数据库执行了查询(这已经能证明了,在座各位真要杠可以自己动手调试,顺带去看sql执行记录)。当然,我并不觉得EF会搞出一个假分页,如果仅仅只是在内存数据上做分页过滤,那微软的工程师也太假了。于是网上科普了一下知识盲点,发现原因所在了!
where之后并不会执行查询,但是当把表达式赋值给对象后,就会执行查询了!所以当我们内存不富裕且查询数据量较大时推荐连写:
var total=db.Set<T>().Where(whereLambda).Count();
var queryable=db.Set<T>().Where(whereLambda).OrderBy(orderByLambda).Skip<T>(pageSize * (pageIndex - 1)).Take<T>(pageSize);
上面这样写会生成两条sql,一条查总数,一条查分页数,都不会很占内存。通常的分页都是会有这样的两条sql,这里会连接数据库两次,如果想只连接一次,可以按照前面的写法,提前将数据加载到内存,再进一步在内存做过滤查询,也就是伪分页。这样做不能说完全不对,看具体场景了,不过还是不推崇加载到内存的做法,尽量还是去执行分页sql比较好。
当然了,非要一次连接+不占内存的方式去实现的话,也是有路子的=>存储过程,一条指令完事,只不过存储过程不利于数据库迁移和维护,也还是少用为妙。
以上。综合分析,根据自身情况去使用就好,知道了前因后果以后出性能问题也知道如何排查。