“ 这篇文章主要为了说明规矩要遵守,但是也别这么死板,要知道因场景不同而变化。了解各自的优缺点,在不同业务中根据需求选择使用。”
我们在项目上进行数据库设计的时候要求遵守三范式,为什么会约束三范式呢:为了减少数据冗余。
回忆下是哪三范式:
-
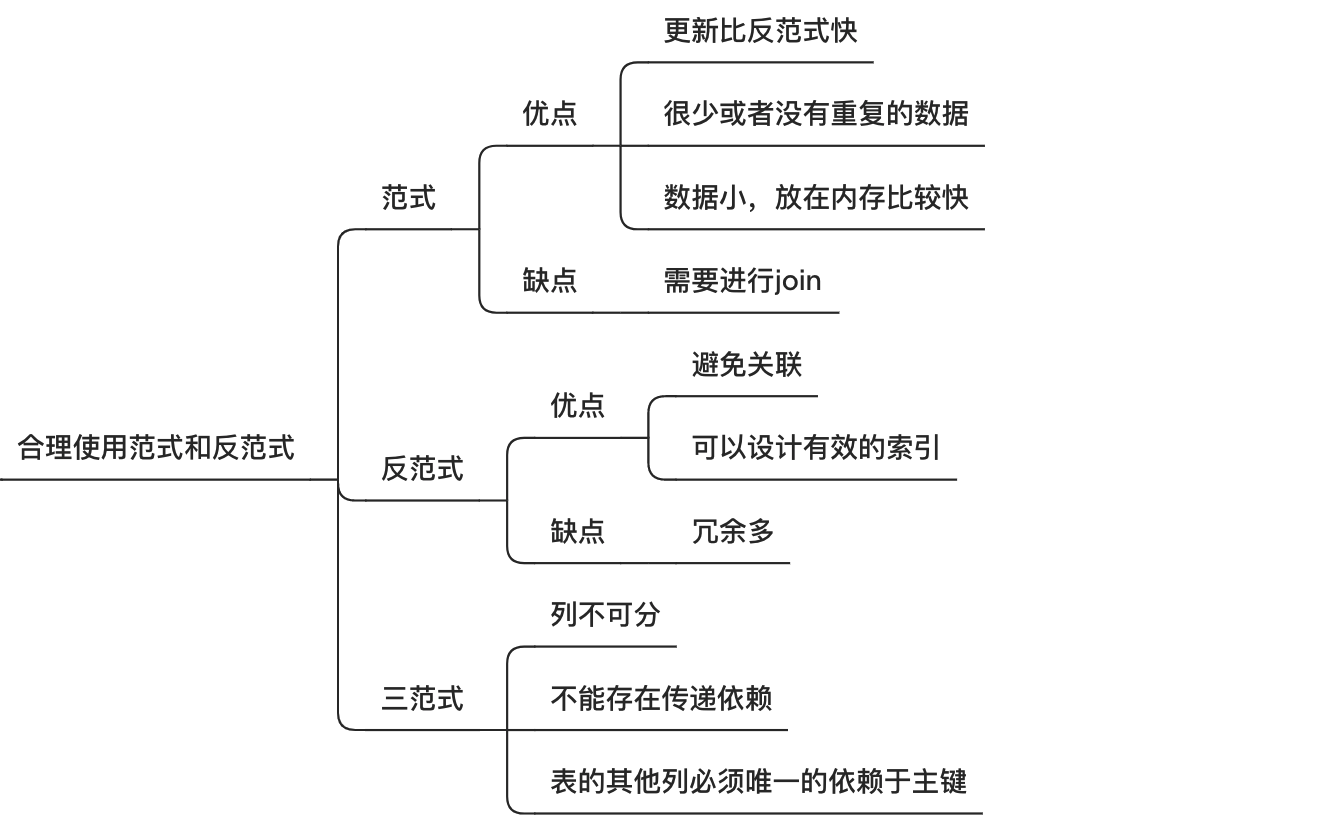
所有属性具有原子性,列不可分割。
例如家庭地址(xx省xx市xx地址),家庭地址作为字段就是非原子的,可以拆分成字段省份,城市,地址。
-
在第一范式的基础上,要求所有非主键字段完全依赖主键,不能产生部分依赖。
一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
-
在第二范式的基础上,保证每列都和主键直接相关,不存在传递依赖
表中的字段和主键直接对应不依靠其他中间字段。传递依赖:A--->B--->C。
范式
优点:
-
范式化的更新通常比反范式更快。
-
当数据较好的范式化后,就只有很少或者没有重复数据。
-
范式化的表通常更小,可以更好的放进内存了,所以执行操作也会更快。
-
很少有多余的数据意味着检索列表数据时更少需要distinct和group by语句。
缺点:
-
通常需要表关联,复杂一点的查询语句可能至少需要一次关联,也可能会使得索引失效。
阿里开发手册中规定表join关联不能超过3个,主要原因就是数据量大的时候join查询非常慢,但是也不一定不能关联多个,具体问题具体分析,数据量少的时候多张表关联也没影响的。
反范式
优点:
-
数据都在一张表中,可以很好的避免关联。
如果不需要关联,则对大部分查询最差的情况---即使表没有使用索引,是全表扫描。当数据比内存大时,可能比关联要快得多,因为这样避免了随机I/O(全表扫描基本上是顺序I/O,但不是100%的和引擎有关).
-
单表可以更有效的使用索引策略。
缺点:
-
表中的冗余较多,删除数据的时候容易造成部分有用数据丢失。
混用范式和反范式
实际上完全范式或者完全反范式都是理论上的。在实际的项目开发中,基本都是混用的,没有严格的规定。
案例分析:
例A: 假设有一个网站,允许用户发送消息,而且其中一些用户是VIP,现在想查看VIP用户的近10条信息。
-
完全范式化 表设计:user(user_id,user_type)表和message(message_id,user_id,message_text,published)表,published构建索引
查询sql:
SELECT message.message_textFROM message INNER JOIN USER ON message.user_id = USER.user_idWHERE USER.user_type = 'VIP' ORDER BY message.published DESC LIMIT 10;
上面sql需要表关联,mysql需要扫描message 表的日期published的索引,对于每一行找到的数据都要到user表检索是不是VIP用户,如果VIP只是很小的一部分,这个效率就很低下了。另一种执行计划是先从user表开始,找所有VIP用户获取并排序,这种可能更糟糕。
2. 完全的反范式,需要在message表中存储user数据,就会存在message数据操作影响user数据的问题。
3. 混用范式和反范式:修改message表结构增加用户类型字段user_type, 如:message(message_id,user_id,message_text,published,user_type),这种设计可以避免完全范式化带来的表关联查询,也避免了完全反范式的插入删除问题(即使没有消息用户的信息也不会丢失)。
例B: 如果部分需求是查询的结果需要排序,从父表中冗余一些数据到子表更方便设计索引,提高查询效率。
例C: 对于缓存衍生值也是有效的,如果需要显示每个用户发了多少消息(论坛发帖),每次需要执行一个统计的自查询计算,其实可以在user表中增加消息数量的字段,当用户发送消息的时候更新这个值(需要平衡更新和查询哪个更好)。
以上只是为了说明范式和反范式以及混用范式而举的例子,但是实际开发中还是要根据业务来选择怎么使用。
在表设计中,使用范式也好,反范式也好,不应该有严格的限制,该用哪种就使用哪种或者两者结合使用。