seq2seq
是RNN的变种,也叫 Encoder-Decoder 模型。它的输入是一个序列,输出也是一个序列,常用于翻译等场景。
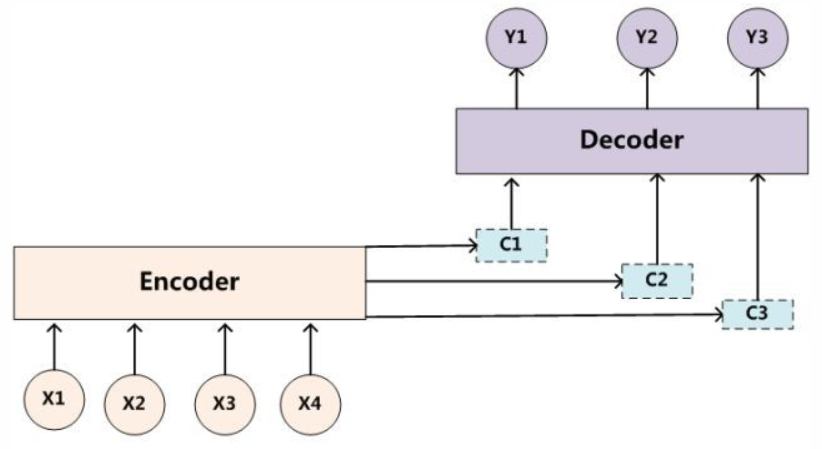
利用两个 RNN,Encoder 负责将输入序列压缩成指定长度的上下文向量c,Decoder 则负责根据上下文向量c生成指定的序列。
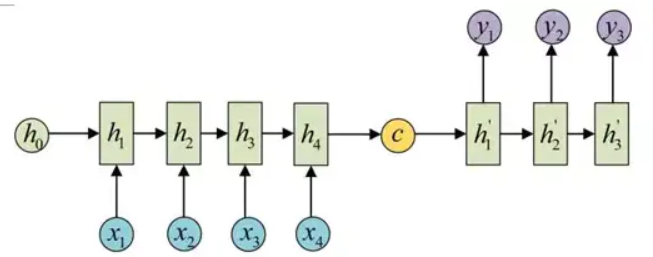
上下文向量c也可以参与序列所有时刻的运算。
Decoder 输出时刻t的每个词向量概率(softmax)。
直接选择每个时刻最大概率的词就是基本的贪心形式。改进有 beam search 算法。假如 beam_size 为3,词库一共n个词,那么第一个词a1选择概率最高的3个词作为可能的集合。前两个词a1a2使用a1的3个可能词分别与字典中的所有词进行组合,选择概率最高的三个组合作为a1a2。a1a2a3同样选择组合中概率最高的三个这样循环下去。
attention机制
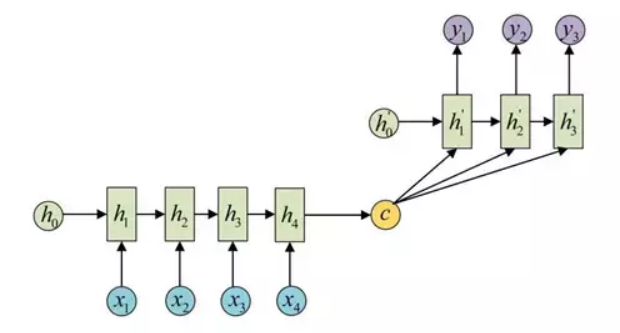
基本的seq2seq的Encoder得到的上下文向量可以理解为信息的有损压缩,信息量越大损失的就越多。seq2seq + attention 相当于每个时刻的 Decoder 考虑了 Encoder 此时的相关位置(注意力集中处)。
假设输入 Marry is reading book 这句话,在处理"读"这个词时,会给出此时每个词相关度的概率分布 (Marry, 0.1) (is, 0.3) (reading, 0.4) (book, 0.2),也就是注意力分配的权重,使用这些权重与对应的词的 hidden value 做乘积,作为输入c。原先固定的c变为会随生成位置变化。即下图公式,aij表示权重,f函数得到状态值 hidden value。
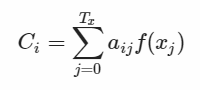
权重aij计算的使用了当前元素和其它元素之间的匹配度,这里计算的定义方法很多。然后softmax一下得到概率。
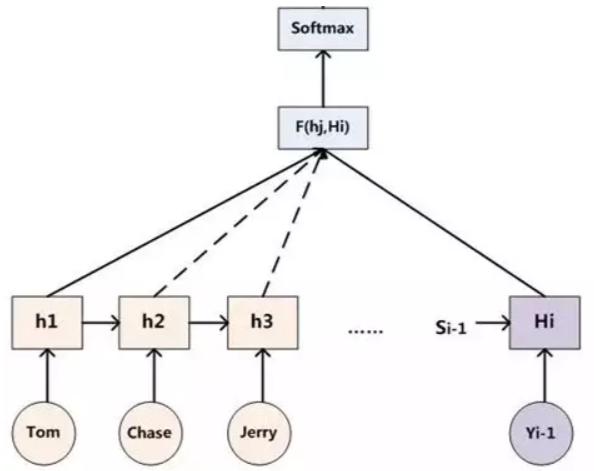
第一步,Decoder 当前隐藏状态和 Encoder 中的每一个隐藏状态进行点积,得到得分score,表示当前的下个输出受每个Encoder 影响的程度。
第二步,SoftMax一下得到权重分布。
第三步,用每个 Encoder 的隐藏状态乘以 SoftMax之后的得分,得到对齐矢量。此时注意力集中的位置,Encoder 的隐藏状态保留的值就大。
第四步,对这些向量求和,生成上下文向量,也就是前面公式里的ci。得到的向量与 Decoder 的上一个隐藏状态作与为 Decoder 的输入。
目标句子生成的每个单词对应输入句子单词的概率分布,可以理解为输入句子单词和这个目标生成单词的对齐概率。
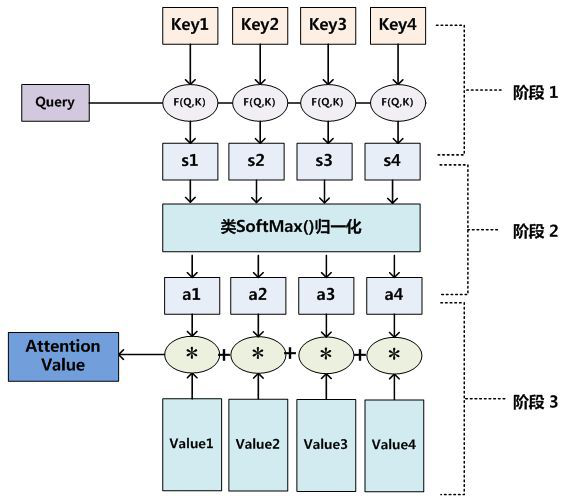
把 Attention 机制从 Encoder-Decoder 框架中剥离,Attention 机制的本质:将Source中的构成元素想象成是由一系列的 <Key,Value> 数据对(nlp中 Key 和 Value 一般相同,Encoder的隐藏状态)构成,此时给定 Target 中的某个元素 Query(Decoder的隐藏状态),通过计算 Query 和各个 Key 的相关性,得到每个 Key 对应 Value 的权重系数,然后对 Value 进行加权求和,即得到了最终的 Attention 数值。所以本质上 Attention 机制是对 Source 中元素的 Value 值进行加权求和,而 Query 和 Key 用来计算对应Value的权重系数。
即经过三步计算 attention value:(1)Q与K进行相似度计算得到权值。(2)SoftMax归一化。(3)用归一化的权值与V加权求和。
![]()
Self-attention
可以理解为内部元素之间发生的 Attention 机制,而非 Target 和 Source 之间,也可以理解为 Target = Source 这种特殊情况下的 Attention。
Self-Attention 可以捕获同一个句子中单词之间的一些句法特征(比有一定距离的短语结构)或者语义特征(its)。而不像LSTM要根据序列顺序计算,远距离单词之间特性难以捕获。
Query, Key, Value 三个矩阵来自同一输入乘以它们各自的参数矩阵 WQ,WK,WV,然后将 Query 点乘 Key 得到矩阵 A^,再经过 softmax 得到权重矩阵 A,最后 A * Value 得到输出。