索引
1. 思考
在图书馆中是如何找到一本书的?
一般的应用系统对比数据库的读写比例在10:1左右(即有10次查询操作时有1次写的操作),
而且插入操作和更新操作很少出现性能问题,
遇到最多、最容易出问题还是一些复杂的查询操作,所以查询语句的优化显然是重中之重
2. 解决办法
当数据库中数据量很大时,查找数据会变得很慢
优化方案:索引
3. 索引是什么
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度
4. 索引目的
索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的,如果我想找到m开头的单词呢?或者ze开头的单词呢?是不是觉得如果没有索引,这个事情根本无法完成?
5. 索引原理
除了词典,生活中随处可见索引的例子,如火车站的车次表、图书的目录等。它们的原理都是一样的,通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是我们总是通过同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂许多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段……这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。

6. 索引的使用
- 查看索引
show index from 表名;
- 创建索引
- 如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致
- 字段类型如果不是字符串,可以不填写长度部分
create index 索引名称 on 表名(字段名称(长度))
- 删除索引:
drop index 索引名称 on 表名;
7. 索引demo
7.1. 创建测试表testindex
create table test_index(title varchar(10));
7.2 使用python程序(ipython也可以)通过pymsql模块 向表中加入十万条数据
1 from pymysql import connect 2 3 def main(): 4 # 创建Connection连接 5 conn = connect(host='localhost',port=3306,database='jing_dong',user='root',password='mysql',charset='utf8') 6 # 获得Cursor对象 7 cursor = conn.cursor() 8 # 插入10万次数据 9 for i in range(100000): 10 cursor.execute("insert into test_index values('ha-%d')" % i) 11 # 提交数据 12 conn.commit() 13 14 if __name__ == "__main__": 15 main()
7.3. 查询
- 开启运行时间监测:
set profiling=1;
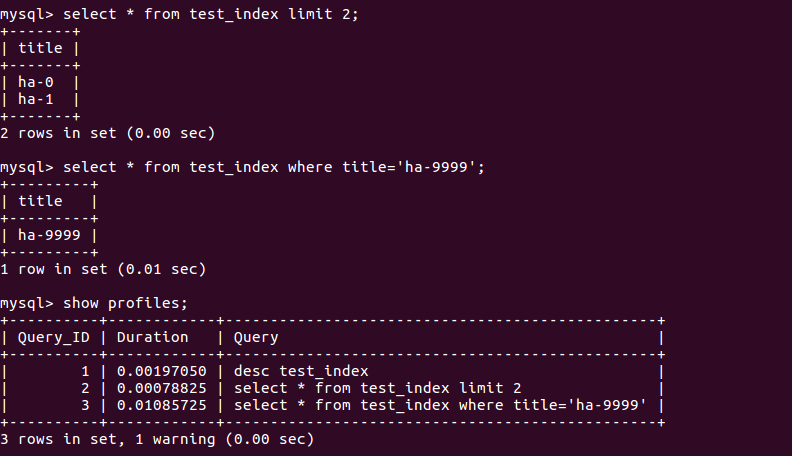
- 查找第1万条数据ha-99999
select * from test_index where title='ha-99999';
- 查看执行的时间:
show profiles;
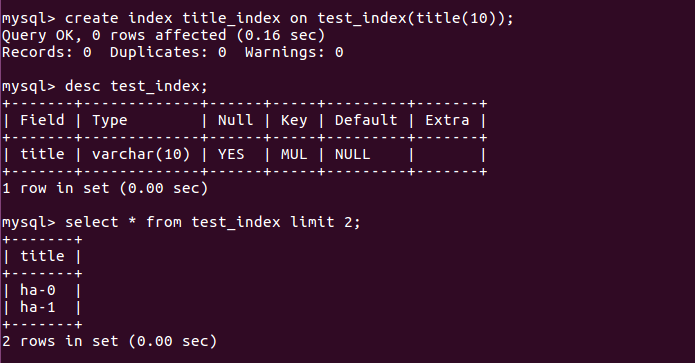
- 为表title_index的title列创建索引:
create index title_index on test_index(title(10));
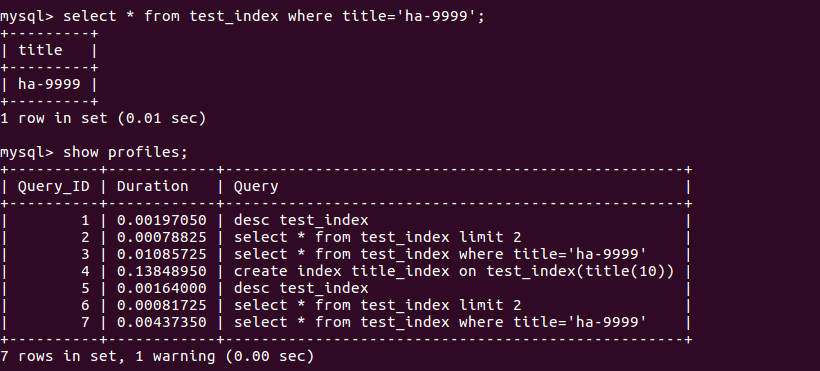
- 执行查询语句:
select * from test_index where title='ha-99999';
- 再次查看执行的时间
show profiles;
运行截图:
1.将1万条数据插入到test_index表中

2.开启运行时间监测

3.输入查询语句,并输出查询时间
4.创建索引
5.创建索引后,输入查询语句,输出查询时间
比较:Query_ID 3 和 7
8. 注意:
要注意的是,建立太多的索引将会影响更新和插入的速度,因为它需要同样更新每个索引文件。
对于一个经常需要更新和插入的表格,就没有必要为一个很少使用的where字句单独建立索引了,对于比较小的表,排序的开销不会很大,也没有必要建立另外的索引。
建立索引会占用磁盘空间.