Spark伪分布式安装
下载 Spark 安装包
官网下载 http://spark.apache.org/downloads.html
安装前准备
- Java8 已安装
- hadoop2.7.5 已安装
修改 Hadoop 配置文件
修改 Hadoop yarn-site.xml配置
vim ~/App/hadoop-2.7.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
重启yarn服务
stop-yarn.sh
start-yarn.sh
启动 MapReduce History Server
sbin/mr-jobhistory-daemon.sh start historyserver
在浏览器中打开 MapReduce history server 地址
[http://bigdata:19888](http://bigdata:19888)
Spark 安装、配置
1、 解压缩 spark-2.1.0-bin-hadoop2.7.tgz
tar -zxvf spark-2.1.1-bin-hadoop2.7.tar -C ~/App
2、 进入 conf 配置文件目录,修改 spark-env.sh
cd ~/App/spark-2.1.1-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export HADOOP_CONF_DIR=~/App/hadoop-2.7.3/etc/hadoop
export HIVE_CONF_DIR=~/App/apache-hive-2.1.1-bin/conf
export SPARK_DIST_CLASSPATH=$(~/App/hadoop-2.7.3/bin/hadoop classpath)
3、 进入 conf 配置文件目录,修改 spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
spark.master=local
spark.yarn.historyServer.address=bigdata:18080
spark.history.ui.port=18080
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs:///tmp/spark/events
spark.history.fs.logDirectory=hdfs:///tmp/spark/events
4、 在 HDFS 上创建目录 /tmp/spark/events
hadoop fs –mkdir –p /tmp/spark/events
配置环境变量
vim ~/.bash_profile
export SPARK_HOME=/Users/baihe/App/spark-2.1.1-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
source ~/.bash_profile
启动
- 启动 Hdfs
start-dfs.sh - 启动 Spark
~/App/spark-2.1.1-bin-hadoop2.7/sbin/start-all.sh - 启动 Spark History Server
~/App/spark-2.1.1-bin-hadoop2.7/sbin/start-history-server.sh
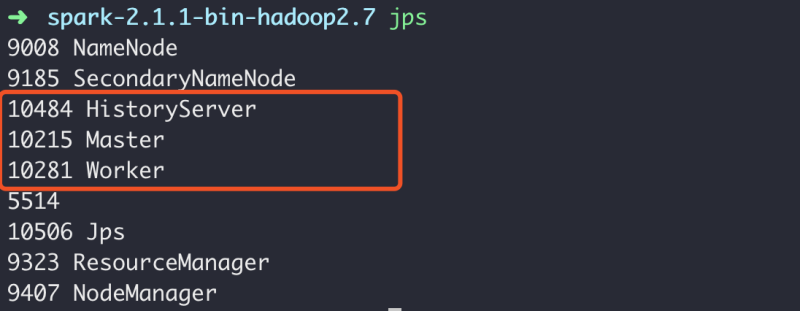
查看进程
➜ spark-2.1.1-bin-hadoop2.7 jps
9008 NameNode
9185 SecondaryNameNode
10484 HistoryServer
10215 Master
10281 Worker
5514
10506 Jps
9323 ResourceManager
9407 NodeManager
查看web界面

 扫码关注有惊喜
扫码关注有惊喜
(转载本站文章请注明作者和出处 白贺-studytime)