一:hive简介
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,
Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
二:hive工作原理
(一)Hive和Hadoop之间的工作流程图
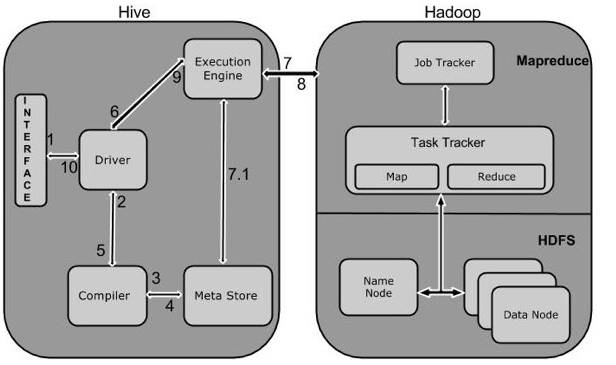
(二)Hive和Hadoop框架的交互方式:
-
Execute Query:Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。
-
Get Plan:在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。
-
Get Metadata:编译器发送元数据请求到Metastore(任何数据库)。
-
Send Metadata:Metastore发送元数据,以编译器的响应。
-
Send Plan:编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。
-
Execute Plan:驱动程序发送的执行计划到执行引擎。
-
Execute Job:在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。(7.1 Metadata Ops:与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。)
-
Fetch Result.:执行引擎接收来自数据节点的结果。
-
Send Results:执行引擎发送这些结果值给驱动程序。
-
Send Results:驱动程序将结果发送给Hive接口。
三:hive工作流程案例讲解(简单理解)
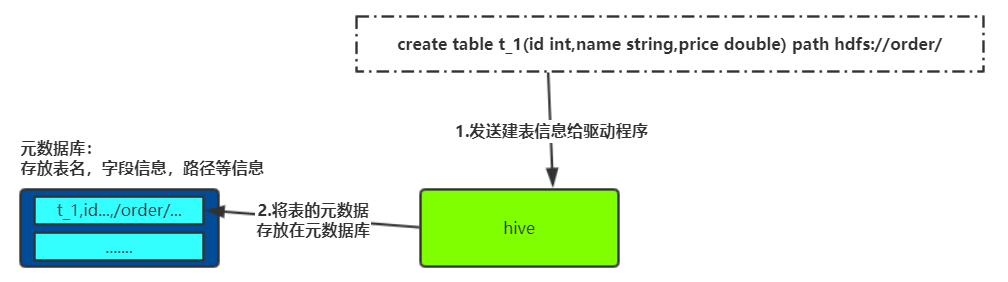
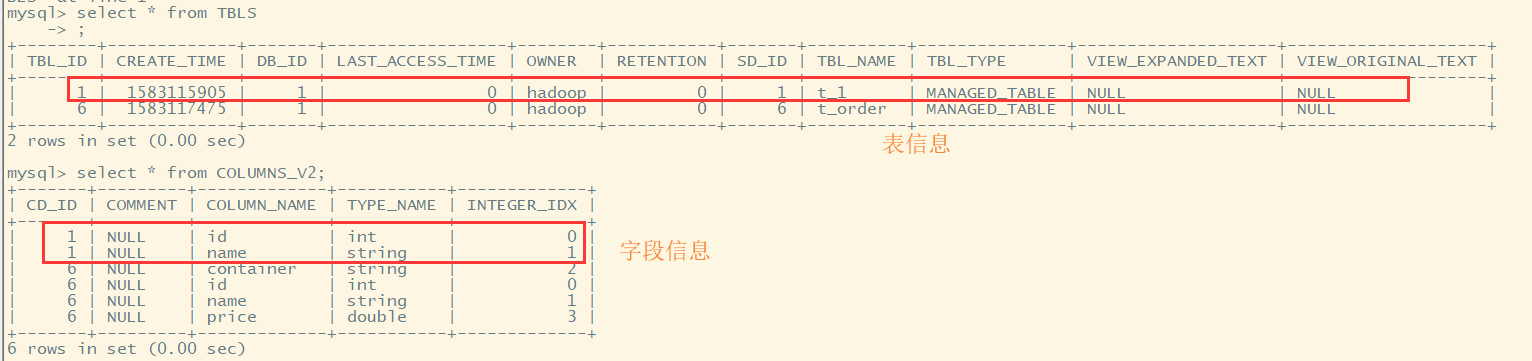
(一)建表---将信息存放入元数据库中
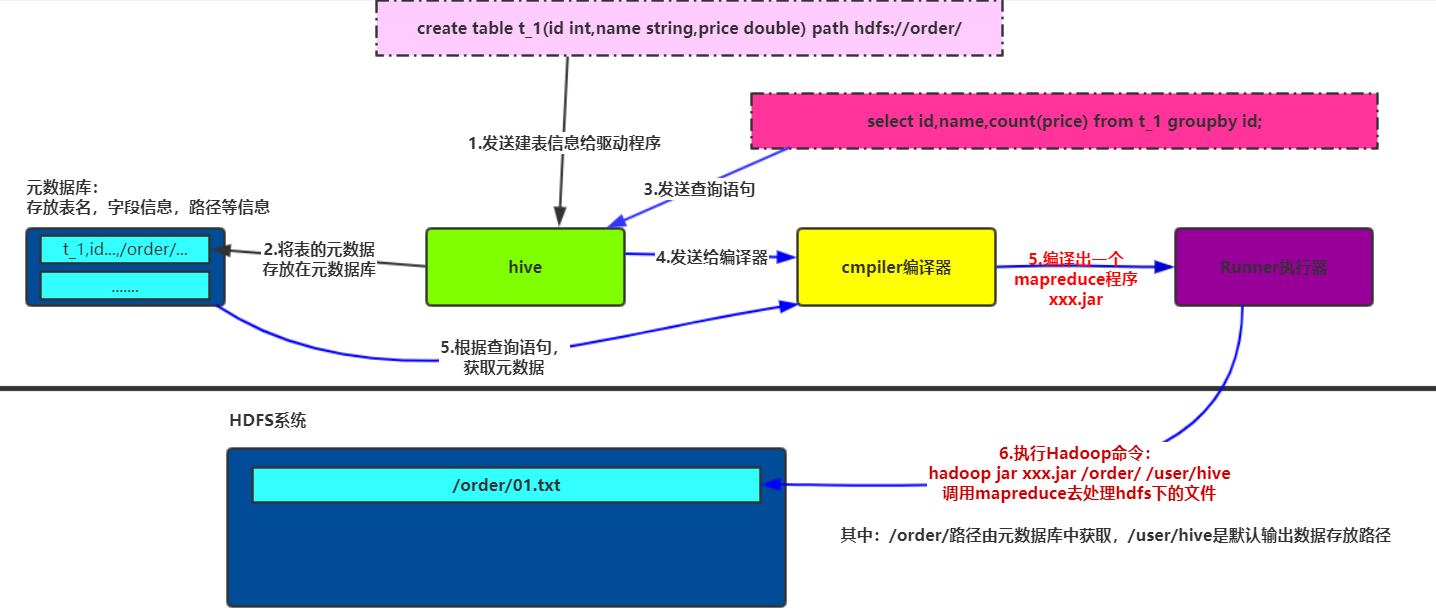
(二)进行数据查询
四:hive的安装
(一)安装mysql数据库
如果不设置hive与mysql关联,则hive使用默认数据库,在不同目录下使用hive命令,则会创建不同数据库文件放入当前目录。而使用mysql则可以对数据进行统一管理


链接:https://pan.baidu.com/s/1CsKlOJZnmHZqJWb_daG3fg 提取码:89om
查询以前安装的mysql相关包 rpm -qa | grep mysql 暴力删除这个包 rpm -e mysql-libs-5.1.66-2.el6_3.i686 --nodeps rpm -ivh MySQL-server-5.1.73-1.glibc23.i386.rpm rpm -ivh MySQL-client-5.1.73-1.glibc23.i386.rpm 执行命令设置mysql /usr/bin/mysql_secure_installation
如果有conflict包冲突错误,可以使用rpm -e进行卸载!!!
测试安装结果:

(二)安装hive
tar -zxvf hive-0.9.0.tar.gz
进入bin目录:执行hive命令

(三)配置hive配置文件
进入conf配置文件夹,配置hive-site.xml文件
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoopH1:3306/hive?createDatabaseIfNotExist=true</value> #连接数据库,并创建hive数据库,如果不存在,则创建 </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> #配置用户名 <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> #配置密码 <value>root</value> </property> </configuration>
(四)拷贝启动文件到hive的lib目录下
mv mysql-connector-java-5.1.28.jar App/hive-0.12.0/lib/
(五)结果测试
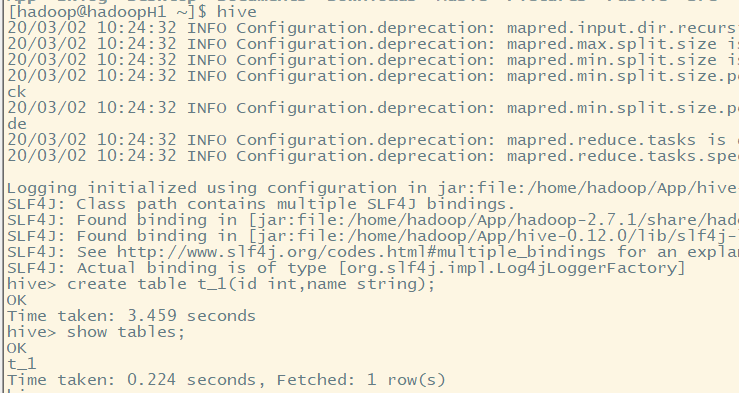
不会再生成元数据库,而是统一将数据存放在MySQL数据库中。
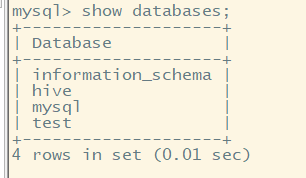

默认数据库文件存放位置 (如果我们不主动指定数据库)
可以在hdfs中查看数据库文件:
