需求:
支持大文件批量上传(20G)和下载,同时需要保证上传期间用户电脑不出现卡死等体验;
内网百兆网络上传速度为12MB/S
服务器内存占用低
支持文件夹上传,文件夹中的文件数量达到1万个以上,且包含层级结构。
支持PC端全平台操作系统,Windows,Linux,Mac
支持文件和文件夹的批量下载,断点续传。刷新页面后继续传输。关闭浏览器后保留进度信息。
支持文件夹批量上传下载,服务器端保留文件夹层级结构,服务器端文件夹层级结构与本地相同。
支持断点续传,关闭浏览器或刷新浏览器后仍然能够保留进度。
支持文件夹结构管理,支持新建文件夹,支持文件夹目录导航
交互友好,能够及时反馈上传的进度;
服务端的安全性,不因上传文件功能导致JVM内存溢出影响其他功能使用;
最大限度利用网络上行带宽,提高上传速度;
分析:
对于大文件的处理,无论是用户端还是服务端,如果一次性进行读取发送、接收都是不可取,很容易导致内存问题。所以对于大文件上传,采用切块分段上传
从上传的效率来看,利用多线程并发上传能够达到最大效率。
解决方案:
文件上传页面的前端可以选择使用一些比较好用的上传组件,例如百度的开源组件WebUploader,泽优软件的up6,这些组件基本能满足文件上传的一些日常所需功能,如异步上传文件,文件夹,拖拽式上传,黏贴上传,上传进度监控,文件缩略图,甚至是大文件断点续传,大文件秒传。
在web项目中上传文件夹现在已经成为了一个主流的需求。在OA,或者企业ERP系统中都有类似的需求。上传文件夹并且保留层级结构能够对用户行成很好的引导,用户使用起来也更方便。能够提供更高级的应用支撑。
数据库配置类DBConfig.java
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import org.apache.commons.lang.StringUtils;
import down2.biz.DnFile;
import down2.biz.DnFileMySQL;
import down2.biz.DnFileOracle;
import down2.biz.DnFileSQL;
/**
* 数据库配置类
* @author jmzy
*/
public class DBConfig {
public String m_db="oracle";//sql,oracle,mysql
String driver = "";
String url = "";
String name = "";
String pass = "";
//sql
String sql_driver= "com.microsoft.sqlserver.jdbc.SQLServerDriver";
String sql_url = "jdbc:sqlserver://127.0.0.1:1433;DatabaseName=up6";
String sql_name = "sa";
String sql_pass = "123456";
//mysql
String mysql_driver = "com.mysql.jdbc.Driver";
String mysql_url = "jdbc:mysql://127.0.0.1:3306/up6?user=root&password=123456&characterEncoding=UTF-8";
//oracle数据库配置
String oracle_driver = "oracle.jdbc.driver.OracleDriver";
String oracle_url = "jdbc:oracle:thin:@localhost:1521:orcl";
String oracle_name = "system";
String oracle_pass = "123456";
public DBConfig() {
if( StringUtils.equals(this.m_db, "sql") )
{
this.driver = this.sql_driver;
this.url = this.sql_url;
this.name = this.sql_name;
this.pass = this.sql_pass;
}
else if( StringUtils.equals(this.m_db, "mysql") )
{
this.driver = this.mysql_driver;
this.url = this.mysql_url;
}
else if( StringUtils.equals(this.m_db, "oracle") )
{
this.driver = this.oracle_driver;
this.url = this.oracle_url;
this.name = this.oracle_name;
this.pass = this.oracle_pass;
}
}
public DBFile db() {
if( StringUtils.equals(this.m_db, "sql") ) return new DBFileSQL();
else if( StringUtils.equals(this.m_db, "mysql") ) return new DBFileMySQL();
else if( StringUtils.equals(this.m_db, "oracle") ) return new DBFileOracle();
else return new DBFile();
}
public DnFile down() {
if( StringUtils.equals(this.m_db, "sql") ) return new DnFileSQL();
else if( StringUtils.equals(this.m_db, "mysql") ) return new DnFileMySQL();
else if( StringUtils.equals(this.m_db, "oracle") ) return new DnFileOracle();
else return new DnFile();
}
public Connection getCon()
{
Connection con = null;
try
{
Class.forName(this.driver).newInstance();//加载驱动。
if (StringUtils.equals(this.m_db, "mysql")) con = DriverManager.getConnection(this.url);
else con = DriverManager.getConnection(this.url,this.name,this.pass);
}
catch (SQLException e)
{
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InstantiationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return con;
}
}
该项目核心就是文件分块上传。前后端要高度配合,需要双方约定好一些数据,才能完成大文件分块,我们在项目中要重点解决的以下问题。
* 如何分片;
* 如何合成一个文件;
* 中断了从哪个分片开始。
如何分,利用强大的js库,来减轻我们的工作,市场上已经能有关于大文件分块的轮子,虽然程序员的天性曾迫使我重新造轮子。但是因为时间的关系还有工作的关系,我只能罢休了。最后我选择了百度的WebUploader来实现前端所需。
如何合,在合之前,我们还得先解决一个问题,我们如何区分分块所属那个文件的。刚开始的时候,我是采用了前端生成了唯一uuid来做文件的标志,在每个分片请求上带上。不过后来在做秒传的时候我放弃了,采用了Md5来维护分块和文件关系。
在服务端合并文件,和记录分块的问题,在这方面其实行业已经给了很好的解决方案了。参考迅雷,你会发现,每次下载中的时候,都会有两个文件,一个文件主体,另外一个就是文件临时文件,临时文件存储着每个分块对应字节位的状态。
这些都是需要前后端密切联系才能做好,前端需要根据固定大小对文件进行分片,并且请求中要带上分片序号和大小。前端发送请求顺利到达后台后,服务器只需要按照请求数据中给的分片序号和每片分块大小(分片大小是固定且一样的)算出开始位置,与读取到的文件片段数据,写入文件即可。
为了便于开发,我 将服务端的业务逻辑进行了如下划分,分成初始化,块处理,文件上传完毕等。
服务端的业务逻辑模块如下
功能分析:
文件夹生成模块
文件夹上传完毕后由服务端进行扫描代码如下
分块上传,分块处理逻辑应该是最简单的逻辑了,up6已经将文件进行了分块,并且对每个分块数据进行了标识,这些标识包括文件块的索引,大小,偏移,文件MD5,文件块MD5(需要开启)等信息,服务端在接收这些信息后便可以非常方便的进行处理了。比如将块数据保存到分布式存储系统中
分块上传可以说是我们整个项目的基础,像断点续传、暂停这些都是需要用到分块。
分块这块相对来说比较简单。前端是采用了webuploader,分块等基础功能已经封装起来,使用方便。
借助webUpload提供给我们的文件API,前端就显得异常简单。
前台HTML模板
分则必合。把大文件分片了,但是分片了就没有原本文件功能,所以我们要把分片合成为原本的文件。我们只需要把分片按原本位置写入到文件中去。因为前面原理那一部我们已经讲到了,我们知道分块大小和分块序号,我就可以知道该分块在文件中的起始位置。所以这里使用RandomAccessFile是明智的,RandomAccessFile能在文件里面前后移动。但是在andomAccessFile的绝大多数功能,已经被JDK1.4的NIO的“内存映射文件(memory-mapped files)”取代了。我在该项目中分别写了使用RandomAccessFile与MappedByteBuffer来合成文件。分别对应的方法是uploadFileRandomAccessFile和uploadFileByMappedByteBuffer。两个方法代码如下。
秒传功能
服务端逻辑
秒传功能,相信大家都体现过了,网盘上传的时候,发现上传的文件秒传了。其实原理稍微有研究过的同学应该知道,其实就是检验文件MD5,记录下上传到系统的文件的MD5,在一个文件上传前先获取文件内容MD5值或者部分取值MD5,然后在匹配系统上的数据。
Breakpoint-http实现秒传原理,客户端选择文件之后,点击上传的时候触发获取文件MD5值,获取MD5后调用系统一个接口(/index/checkFileMd5),查询该MD5是否已经存在(我在该项目中用redis来存储数据,用文件MD5值来作key,value是文件存储的地址。)接口返回检查状态,然后再进行下一步的操作。相信大家看代码就能明白了。
嗯,前端的MD5取值也是用了webuploader自带的功能,这还是个不错的工具。
控件计算完文件MD5后会触发md5_complete事件,并传值md5,开发者只需要处理这个事件即可,
断点续传
up6已经自动对断点续传进行了处理,不需要开发都再进行单独的处理。
在f_post.jsp中接收这些参数,并进行处理,开发者只需要关注业务逻辑,不需要关注其它的方面。
断点续传,就是在文件上传的过程中发生了中断,人为因素(暂停)或者不可抗力(断网或者网络差)导致了文件上传到一半失败了。然后在环境恢复的时候,重新上传该文件,而不至于是从新开始上传的。
前面也已经讲过,断点续传的功能是基于分块上传来实现的,把一个大文件分成很多个小块,服务端能够把每个上传成功的分块都落地下来,客户端在上传文件开始时调用接口快速验证,条件选择跳过某个分块。
实现原理,就是在每个文件上传前,就获取到文件MD5取值,在上传文件前调用接口(/index/checkFileMd5,没错也是秒传的检验接口)如果获取的文件状态是未完成,则返回所有的还没上传的分块的编号,然后前端进行条件筛算出哪些没上传的分块,然后进行上传。
当接收到文件块后就可以直接写入到服务器的文件中
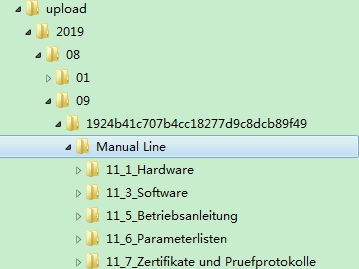
这是文件夹上传完后的效果
这是文件夹上传完后在服务端的存储结构