文章主体
gitee 项目地址
| 这个作业属于的课程 | https://edu.cnblogs.com/campus/zswxy/computer-science-class2-2018 |
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/computer-science-class2-2018/homework/11878 |
| 我在这个课程的目标是 | 为以后企业项目做基础 gitee 项目搭建 |
| 学号 | 20188393 |
PSP表格
| PSP | Personal Software Process tages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 20 |
| Estimate | 估计这个任务需要多少时间 | 400 | 450 |
| Development | 开发 | 60 | 80 |
| Analysis | 需求分析(包括学习新技术) | 70 | 60 |
| Design Spec | 生成设计文档 | 50 | 30 |
| Design Review | 设计复审 | 60 | 120 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| Design | 具体设计 | 120 | 120 |
| Coding | 具体编码 | 120 | 120 |
| Code Review | 代码复审 | 60 | 70 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 70 |
| Reporting | 报告 | 120 | 120 |
| Test Repor | 测试报告 | 150 | 150 |
| Size Measurement | 计算工作量 | 600 | 800 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 500 | 600 |
| 合计 | 1915 | 2850 |
首先我遇到的问题就是fork 其实很懵逼,但是经过助教的解释后懂了fork的大概意思,然后fork下了仓库。

后面我进行了远程 本地仓库和我们的ider 进行了一个链接 ,绿色勾勾是表示ider连接码云成功 ,中间卸载了很多次,用了乌龟这个驱动,jdk的配置,这个是去企业做项目的最多操作,这次作业收获比较大的操作。
接下来就是我们的项目进行了。ider 与gitee相关联好了就可以直接在ider 上进行git push。
首先是作业需求
1.统计文件的字符数(对应输出第一行):
只需要统计Ascii码,汉字不需考虑
空格,水平制表符,换行符,均算字符
2.统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
英文字母: A-Z,a-z
字母数字符号:A-Z, a-z,0-9
分割符:空格,非字母数字符号
例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
3.统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
4.统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
频率相同的单词,优先输出字典序靠前的单词。
例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
输出的单词统一为小写格式
解题思路描述
实现字符数只需ascii,我们要统计字符数,然后单词数,统计文章单词出现次数,统计文件的有效行数
可以很明了的看到我们的需求有4个,这就是一个简单的读取统计文章的计数器,
写代码的环境是idea,提交也是在这上面commit push 的上传到码云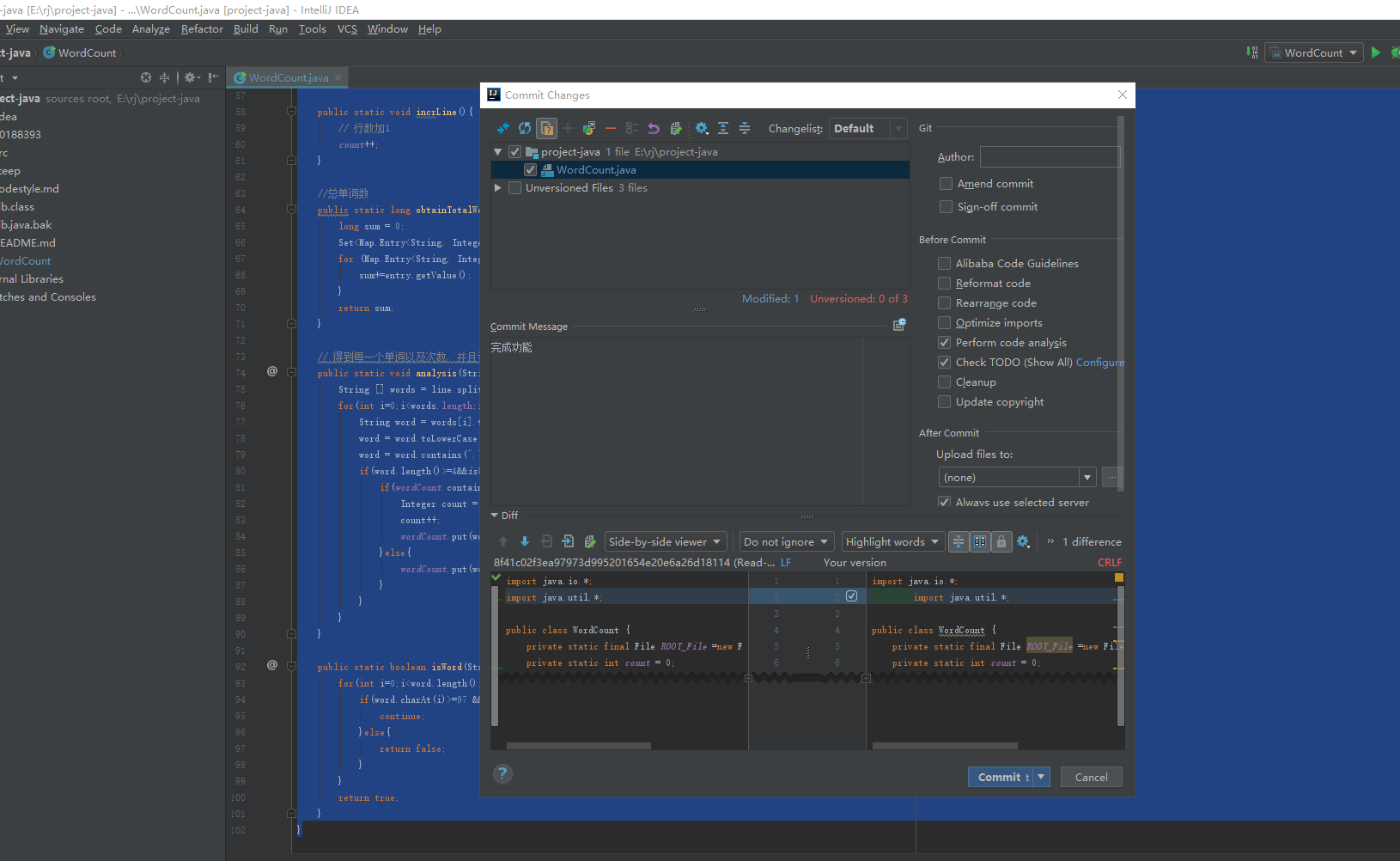
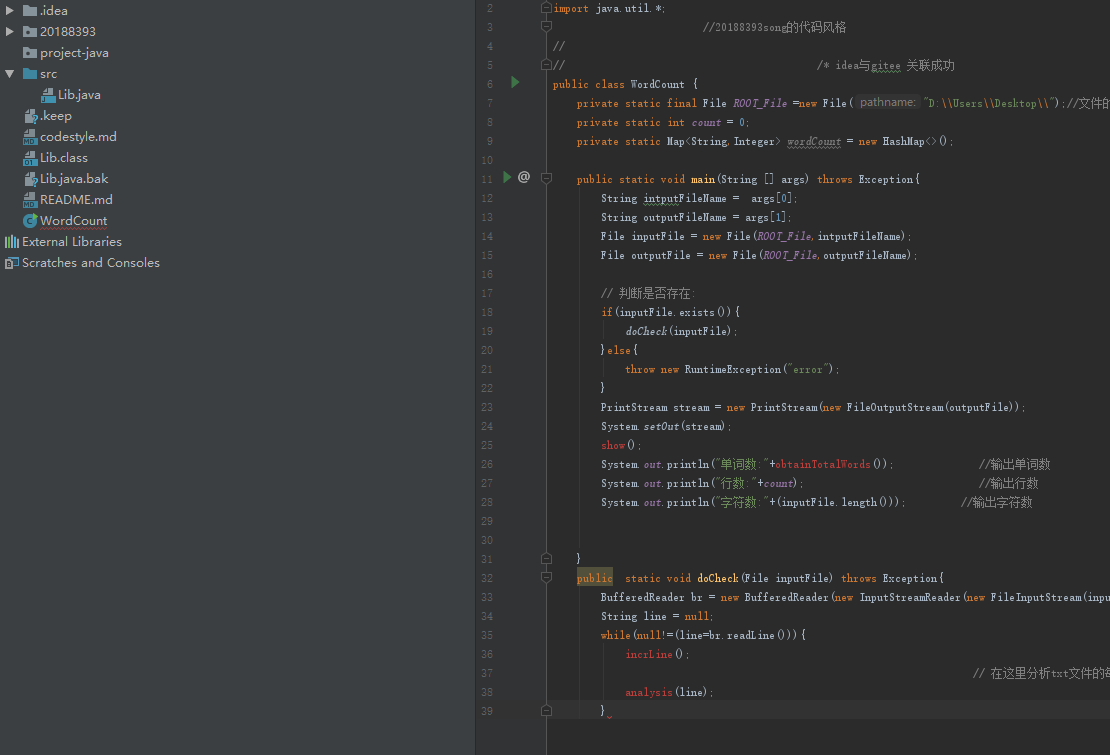
代码如下
import java.io.;
import java.util.;
public class WordCount {
private static final File ROOT_File =new File("D:桌面");
private static int count = 0;
private static Map<String,Integer> wordCount = new HashMap<>();
public static void main(String [] args) throws Exception{
String intputFileName = args[0];
String outputFileName = args[1];
File inputFile = new File(ROOT_File,intputFileName);
File outputFile = new File(ROOT_File,outputFileName);
// 判断是否存在:
if(inputFile.exists()){
doCheck(inputFile);
}else{
throw new RuntimeException("error");
}
PrintStream stream = new PrintStream(new FileOutputStream(outputFile));
System.setOut(stream);
show();
System.out.println("单词数:"+obtainTotalWords());
System.out.println("行数:"+count);
System.out.println("字符数:"+(inputFile.length()));
}
public static void doCheck(File inputFile) throws Exception{
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(inputFile)));
String line = null;
while(null!=(line=br.readLine())){
incrLine();
// 分析每一行。
analysis(line);
}
}
public static void show(){
Set<Map.Entry<String, Integer>> entries = wordCount.entrySet();
// 排序
ArrayList<String> words = new ArrayList<>();
for (Map.Entry<String, Integer> entry : entries) {
words.add(entry.getValue()+"#"+entry.getKey());
}
// 排序
Collections.sort(words);
words.forEach(obj->{
String[] split = obj.split("#");
String str = split[1]+": "+split[0];
System.out.println(str);
});
}
public static void incrLine(){
// 行数加1
count++;
}
//总单词数
public static long obtainTotalWords(){
long sum = 0;
Set<Map.Entry<String, Integer>> entries = wordCount.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
sum+=entry.getValue();
}
return sum;
}
// 得到每一个单词以及次数, 并且记录到Map集合中
public static void analysis(String line){
String [] words = line.split(" ");
for(int i=0;i<words.length;i++){
String word = words[i].trim();
word = word.toLowerCase();
word = word.contains(",")||word.contains(".")?word.substring(0,word.length()-1):word;
if(word.length()>=4&&isWord(word.substring(0,4))){
if(wordCount.containsKey(word)){
Integer count = wordCount.get(word);
count++;
wordCount.put(word,count);
}else{
wordCount.put(word,1);
}
}
}
}
public static boolean isWord(String word){
for(int i=0;i<word.length();i++){
if(word.charAt(i)>=97 && word.charAt(i)<=122){
continue;
}else{
return false;
}
}
return true;
}
}
运行结果
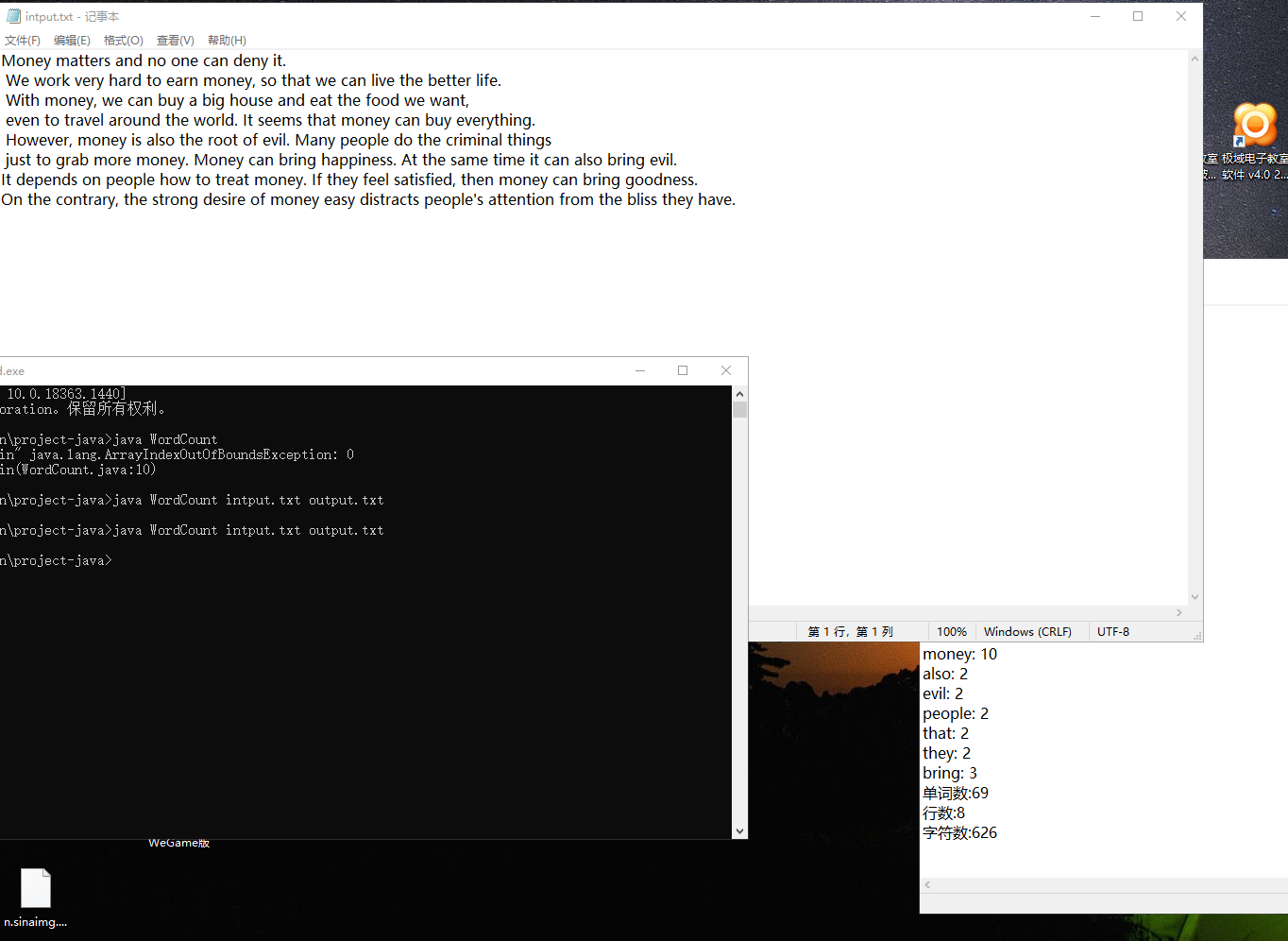
切记 用cmd命令运行,输入 java WordCount input.txt.output.txt才会得到运行结果。
心得体会
其实编程任务不是最苦恼的,主要的还是gitee和idea的联合的问题,eclipse就不要驱动,建议大家用eclipse,我这里用的是idea,要用到驱动,搭建好了,fork 拉好仓库就显得方便
还有题目要求太多,太详细了也可以说是吓到很多同学了,大概我们更希望看到化繁为简的的东西吧,一个作业要求6300字实在是让人苦恼,这次作业需求很明确,这也是这么多字的一个优点吧,对于git的操作,项目搭建,git和ider eclipse的搭建更加的熟悉了,对于题目的审题,需求的分析有了更深的一个学习和了解,希望下次个人作业能有更大的收获,有了这次的作业,下次应该不会如此艰难,最后祝大家假期愉快