前言
微服务是当下的热门话题,今天来聊下微服务中的一个敏感话题:如何保证微服务的数据一致性。谈到分布式事务,就避免不了CAP理论。
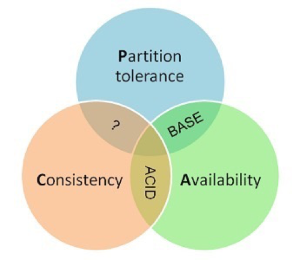
CAP理论是指对于一个分布式计算系统来说,不可能同时满足以下三点:
1. 一致性(Consistence) (等同于所有节点访问同一份最新的数据副本)
2. 可用性(Availability)(对数据更新具备高可用性)
3. 容忍网络分区(Partition tolerance)(以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。)
根据定理,分布式系统只能满足三项中的两项而不可能满足全部三项。以上关于CAP的理论介绍来自维基百科。同理,如何保证微服务间的数据一致性也一直是一个持续的话题,其实就是如何在这三者中做一个权衡。
就之前此公众号已经有一系列的文章来讨论,关于微服务架构下的事务一致性的话题,包括BASE理论,两阶段提交,三阶段提交,可靠事件模式,TCC模式,补偿模式等,想进一步了解的话可以参考这里:微服务架构下的数据一致性保证(一),微服务架构下的数据一致性保证(二),微服务架构下的数据一致性保证(三)。今天只是谈一谈其中的一种场景:使用消息系统进行微服务间通讯,如何来保证微服务间的数据一致性。
1. 问题的引出:
微服务架构之数据一致性问题
这里我们先以下面的一个例子来引出问题:以公有云市场1中的一个部署产品来说,当用户想要部署一个公有云中已有的产品,比如Redis产品,用户会先去公有云市场中找到对应的Redis产品,当用户点击发布时,市场中会进行相应的记录,同时后台有真正负责部署的模块,此处我们叫部署模块。当产品部署成功后,部署模块和市场都会进行最终状态的同步。
1、公有云市场:此处指一个简单的模型,类似阿里云的云镜像市场或亚马逊aws中的镜像市场。在云镜像市场中,用户会选择其中感兴趣的产品比如mysql,然后进行付费,发布,这样省去了用户在自己的云平台环境中手动下载安装包,然后安装,配置,启动等一系列繁琐的过程。在云平台市场中,用户所需要做的只是一些必要的配置,然后点击启动就能完成一个产品的发布。一般都是这样一个先购买镜像后启动实例的过程。
以上都是在理想的情况下进行的,大致流程如下图:
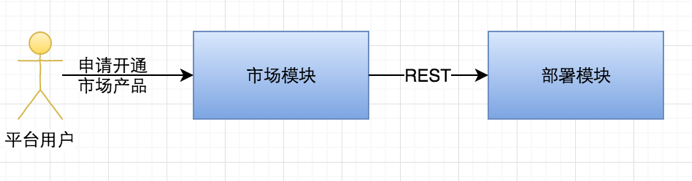
此时,市场和部署模块都是是独立的微服务,当平台用户申请开通产品后,公有云市场会先进行一系列的初始化工作,并向部署模块中发送部署请求,当部署模块部署成功或者失败后,会进行相应的记录,市场也会将状态记录到本地数据库。由于市场和部署都是以微服务形式存在,都有自己的本地事务,此时,我们已经无法通过本地事务的控制来保证操作的原子性了。那么问题就随之而来:
假如市场模块在向部署模块发送完请求之后,市场微服务出现了数据库的连接异常(比如连接数据库的网络异常,数据库漂移等),此时市场会向前端报错,提示部署过程中出错,导致部署失败,但实际上部署模块已经在后台默默的为用户开通了实例。
同样的问题也会出现在,当向部署模块发送完请求后市场微服务出现了宕机等意外情况,市场微服务的数据库中干脆直接没有保存用户的此次开通的请求,但实际上部署模块却已经在这个过程中开通过了产品实例。
如果公有云平台对用户资源的实例限制是5个,即一个用户(比如试用版的用户)最多只能开通5个产品实例,则用户此时在市场中最多只能开4个,因为有一个实例在部署模块成功部署,但是市场模块却并不清楚,此时就出现了数据不一致的严重问题。那么该如何解决此类问题呢?如何解决这类业务前后不一致的问题呢?
2. 引入消息框架,解决数据不一致问题
这里我们采用了消息通信框架Kafka,通过事件机制来完成相应的需求。
在采用Kafka来完成消息的投递的同时,不可避免地也会面对消息的丢失的意外情况。这里我们先来看一下我们实现的主场景,然后在后面我们会接着探讨,如何在业务层面保证消息的绝对投递和消费。
消息发送方的处理
流程处理如下:
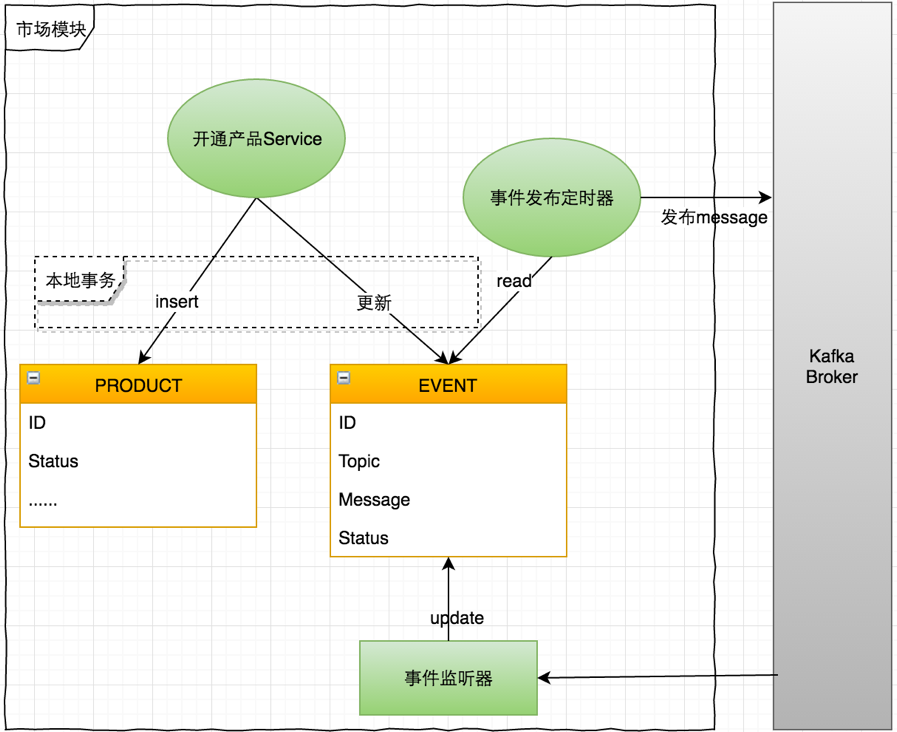
我们来分析一下此种设计如何能够满足我们的需求:
市场模块操作Product和Event是在本地事务进行,保证了本地操作的一致性。
如果开通产品时,市场领域在事件发布之前就发生了异常,宕机或者数据库无法连接,根据设计,事件发布定时器和开通产品的Service是分离操作,此时发生宕机等意外事件,并不会影响数据库中的数据,并在下次服务器正常后事件发布定时器会去Event表中查找尚未发布的数据进行发布并更新消息状态为PUBLISHED.
如果是在更新库中的状态时发生了意外呢?此时消息已经发出到Kafka broker,则下次服务正常时,会将这些消息重新发送,但是因为有了Key的唯一性,部署模块判断这些是重复数据,直接忽略即可。
当产品部署成功后,Market事件监听器收到通知,准备更新数据库时发生了意外宕机等,下次服务正常启动后事件监听器会从上次的消息偏移量处进行监听并更新Event表。
消息接收方的处理
下面我们来看一下消息的接收方部署模块如何处理从Kafka Broker接收到的消息呢?
以下是部署模块对消息处理的流程图,此处部署模块的部署过程使用了简略的示意图。实际的场景中,部署动作以及更新状态是一个复杂的过程,同时可能依赖轮询来完成操作。
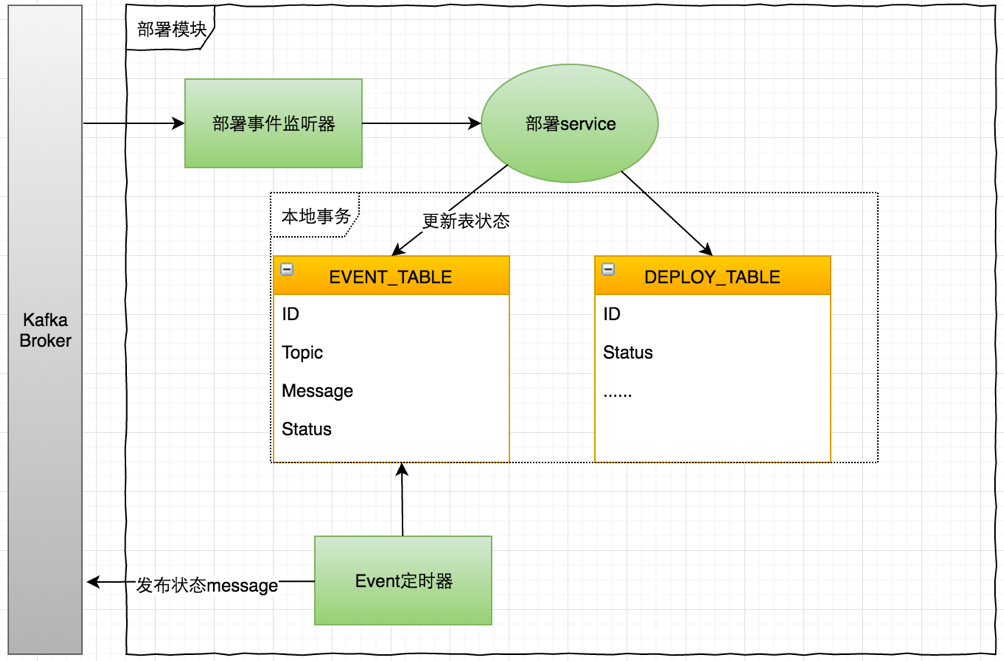
部署模块的事件监听器,在收到通知后,直接调用部署的Service,更新Deploy_table表中的业务逻辑,同时更新Event_Table中的消息状态。另一方面,部署模块的 Event定时器,也会定时从Event_Table中读取信息并将结果发布到Kafka Broker, 市场模块收到通知后进行自己的业务操作。
至于采用这种模式的原理以及原因和市场领域类似,这里不再赘述。
3.引入补偿+幂等机制,
保证消息投递的可靠性
刚才也谈到,Kafka等市面上的大多数消息系统本身是无法保证消息投递的可靠性的。所以,我们也必须要从业务上对消息的意外情况进行保证。下面,我们探讨一下如何从业务上来保证消息投递的绝对可靠呢?
这里,我们就要引入补偿机制+幂等操作,我们在前面的步骤中已经将Event进行了数据库持久化,我们还需要以下几个步骤来从业务上对消息的绝对可靠进行保证:
一、完善事件表字段
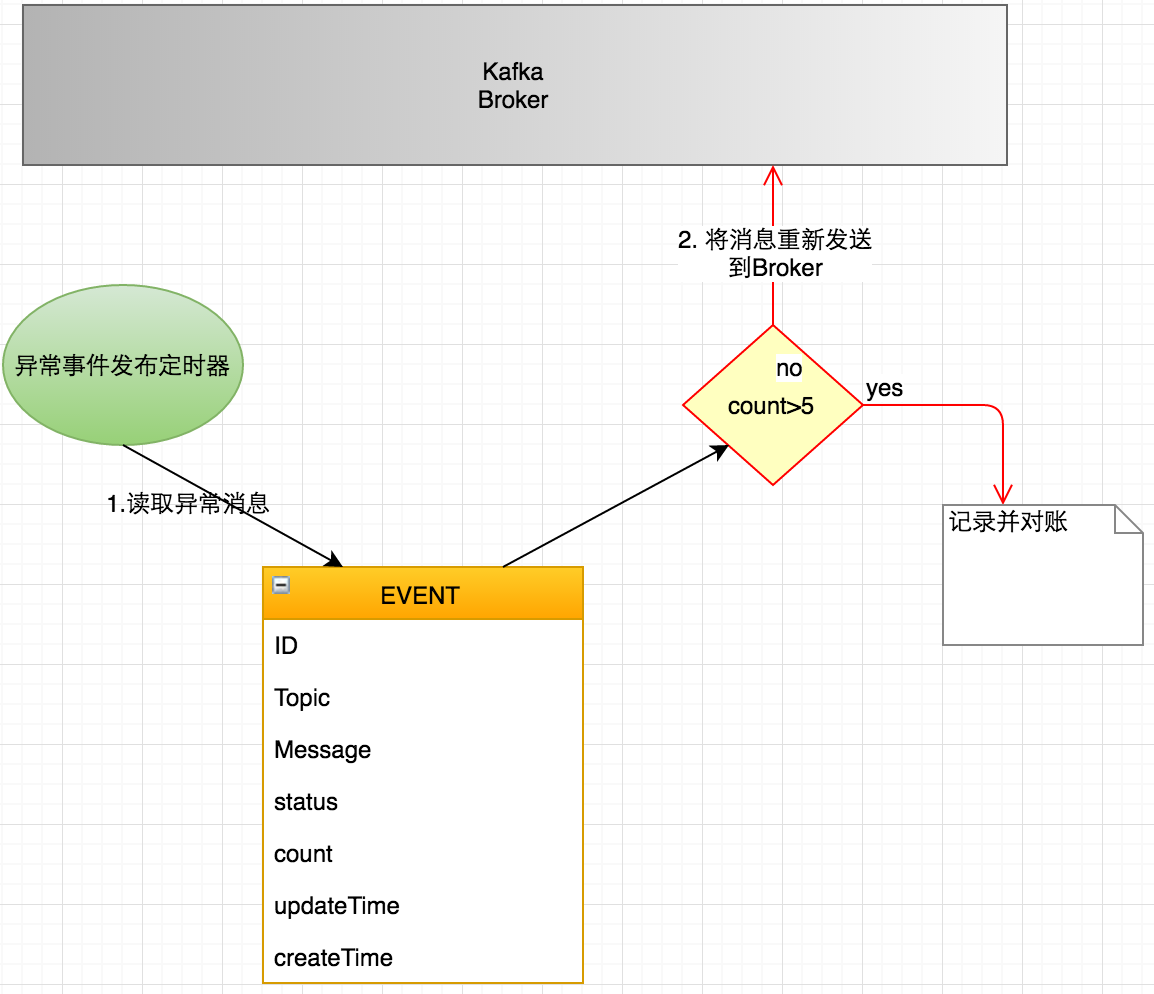
我们在Event表中增加两个新的字段count和updateTime,用来标识此消息发送或者重试的次数。正常情况下,count为1,表示只发送一次。
二、定时补偿加错误重试
同时使用异常事件发布定时器,每隔2分钟(此时间只是一个示例,实际应用中 应大于业务中正常业务处理逻辑的时间)去Event表中查询状态为PUBLISHED的消息,如果对应的消息记录更新时间为两分钟之前的时间,我们就悲观的认为此消息丢失,进行消息的重发,同时更新字段updateTime并将count计数加1。
三、最后一道防线:对账记录,人工干预
如果发现重发次数已经大于5,则认为此时已经无法依靠消息系统来完成此消息的投递,需要最后的一道保障,就是记录下来并在日常进行的人工对账中人工审核。
四、幂等去重
何为幂等呢?因为存在重试和错误补偿机制,不可避免的在系统中存在重复收到消息的场景,接口的幂等性能提高数据的一致性.
在编程中,一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
由于我们的定时补偿机制,消息的消费端也应该保证部署服务的操作是幂等的,即针对同一条消息多次发送的情况,我们应该保证这个消息实际上只会执行一次。
这里如果发现消息是重复发送的,则直接将数据库中的执行结果读出并将结果推送到broker中,从而保证了消息的幂等性。
现在我们来分析一下此种策略如何保证的消息的绝对投递:
每条消息的产生都会在数据库中进行记录,保证消息的不丢失。
异常消息发布定时器会定时去Event表中查看异常消息,发现没有回应的数据则认为消息丢失,进行消息补偿,重新发送,如果连续5次依然失败则认为发生了异常,进行记录并人工干预对账。
对于部署模块(消息的消费端),如果消息丢失,则市场模块就无法收到回应(对应的Event表记录中的状态也不会修改),最终效果也会同#2情况,市场模块进行消息重发,如果重发次数超出了限制则会触发对账记录的业务逻辑。
4. 总结
本文通过采用消息系统进行微服务间的通信,加上一些设计上的变更,既保证了正常情况下(99.9%以上的情况)的逻辑的正确执行,也保证了极端情况下的数据一致性,满足了我们的业务需求,同时依赖市面上消息中间件强大的功能,极大的提高了系统的吞吐量。
针对Kafka等本身不可靠的问题,我们又通过修改业务场景的设计来保证了在极端情况下消息丢失时消息的可靠性,对应的也保证了业务的可靠性。此处只是以Kafka举例,如果是顾虑Kafka的本身消息不可靠的限制,可以考虑使用RabbitMQ或RocketMQ等市面上流行的消息通信框架。
概括来说,此方案主要保证了以下4个维度的一致性:
本地事务保证了业务持久化与消息持久化的一致性。
定时器保证了消息持久与消息投递的一致性。
消息中间件保证了消息的投递和消费的一致性。
业务补偿+幂等保证了消息失败下的一致性。
使用此种方案的弊端就是编码会大幅增加,为不同的微服务间增加不少额外的工作量,同时会产生较多的中间状态。对于业务中时间要求苛刻的场景,此方案不合适。(此处却符合本文中举例的场景,因为产品的开通,需要对容器进行操作,本身就是一个耗时的过程。)
数据一致性是微服务架构设计中唯恐避之不及却又不得不考虑的话题。通过保证最终数据的一致性,也是对CAP理论的一个折衷妥协方案,关于此方案的优劣,也不能简单的一言而概之,而是应该根据场景定夺,适合的才是最好的。
所以,我们在对微服务进行业务划分的时候就尽可能的避免“可能会产生一致性问题”的设计。如果这种设计过多,也许是时候考虑改改设计了。
http://www.primeton.com/read.php?id=2270