from https://zhuanlan.zhihu.com/p/90187724
TTS(Text-to-speech)入门
https://www.zhihu.com/question/269258229/answer/429919536
来源:知乎
为什么tacotron生成语音时需要先生成Mel频谱,再重建语音?Mel频谱在其中起到什么用?
不知道这个问题合不合适,诚惶诚恐,还望各位不吝赐教。
Mel谱就是短时傅里叶变换(STFT)对每一帧的频谱(能量/幅度谱),从线性的频率刻度映射到对数的mel刻度,再用40个滤带(filterbank),双向就是80个,得到80维度的特征向量,这些特征值大致上可以表示为信号能量在mel刻度频率上的分布。
这里有几个关键步骤:分帧、预加重、加窗、STFT、mel刻度,都是拟合人耳对信号分析的手段,最终得到的特征向量是拟合人耳信号分析机理的。
有人会问为啥不用MFCC,其实也是可以的,MFCC就是在频谱上对能量进行对数缩放,再做一次离散余弦变换(DCT),得到倒谱(cepstrum),取前13个系数所谓特征向量。MFCC主要为了提取频谱的包络(倒谱低频)以及频谱细节(倒谱高频)作为语音特征。
Tacotron之所以只用mel频谱而不用MFCC,我猜测是因为MFCC的频谱包络主要用于识别特征,是给机器辨识的,而TTS更加偏向于人耳感知,着重提取人耳敏感特征。相比之下,整个频谱的包络不是十分有必要,我们只需要关注人耳敏感的几个特定频率范围及其能量分布,故而语音合成只需要从mel频谱提取80维度特征向量即可。
另外就像
一般认为语音的频域信号(频谱)相对于时域信号(波形振幅)具备更强的一致性(可理解为对波形的一种归纳抽象,相同的发音频谱上表现一致但波形差别很大),经过加窗等处理后相邻帧的频谱具备连贯性,相比于波形数据具备更好的可预测性;另外就是频谱一般处理到帧级别,而波形处理采样点,数量多很多,计算量也自然更大,所以一般会先预测频谱,然后经由vocoder重建波形。当然如果预测器性能够好,肯定是直接预测波形效果更精细。tacotron后端使用wavenet作为vocoder,更大的作用其实是对预测的频谱做一个音质上的提升,不仅仅是重建,而是一定程度上的找补。可参考wavenet sampleRnn waveRnn。
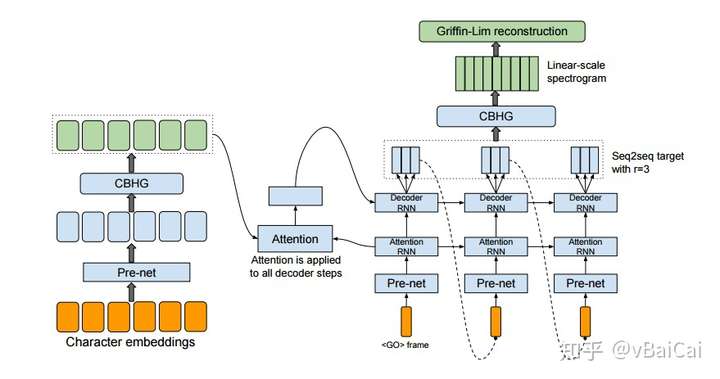
首先,语音重建算法 Griffin-Lim 的输入是线性谱。解码器中 RNN 输出的才是梅尔谱,从梅尔谱到线性谱中间还有一个 CBHG 结构起到后处理的作用。整个神经网络的输出就是线性谱,最后的重建算法并不是神经网络的一部分。 训练模型时的损失函数包括了:梅尔谱的MSE + 线性谱的MSE。
至于为什么要将梅尔谱加入到损失函数的计算中。可能是因为梅尔谱更接近人类的听感,这样设计的损失函数能让合成的语音听起来更自然?
2019年8月13更新
blizzard challenge 2019结果出炉,MOS分4.3分有点出乎意料了。罗正宇的数据音质比较差,口头禅比较多。对于非定制TTS语料库,前期的洗数据是非常重要的,包括拼音校对以及文本增删。合成文本上有英文字母,没有使用base+x难以在英文字母上正常发音,特别是一些x和s这样的无法和中文共享音素的。
近来搜狗的变声功能已经上线,这种any to one的方式,偏娱乐性多一点,我测试过多种方言,有音素识别的sense但不明显,语音拉长唱歌无法迁移,音色也不是很像,按娱乐性定位已经很不错了。
—————————————————————————
2019年2月5日更新
基于tacotron + world的语音合成框架上线。由于数据集的音色不一致和韵律不稳定,端到端的学习是比较困难的。补充输入信息可以弥补端到端模型韵律预测不准和音色波动的问题。另外,通过tacotron自适应的方法,base+x,base可以使用标贝科技开放的女生数据(大约10h),x的数据量可以做到一小时以内,合成效果可以媲美base数据合成效果。(试过x的数据只用了100条,合成效果比较一般,能听得清楚,但是仔细听部分音会有点糊)
语音合成的发展趋势,应该朝着base+x,保证x合成效果的前提下,不断减少x的数据量,实现低成本合成,引爆行业。
—————————————————————————
2018年
端到端的网络,目前应该还是demo阶段为主。我研究tacotron1,tacotron2和deepvoice3比较多,以下的回答也是基于我跑过的相关实验来谈的。
端到端的语音合成存在着以下问题。
1.韵律结构不稳定。一般使用端到端的网络,可能使用的是十几个小时的数据集,大概5000到8000条数据左右,这样的数据量跟专门做韵律分析的模型样本比较,实在太少了。所以想直接从这几千条想得到一个比较稳定的韵律预测,其实是一个很困难的事情。在实验中也可以发现,从合成的自然度来看,端到端的语音合成在部分样本上可以真人达到无法分辨的效果,有一些样本合成出来韵律比较随机,根本放到业务上正常使用。例如明天气温19度。用端到端的网络,合成出来的可能会变成,明_天气_温19度,只要训练集里天气是一个比较高频的词。如果加上各种附加条件,例如韵律信息,时长信息,那这个也不算是严格意义上的端到端网络了。
2.性能方面。真正要放到业务上使用,非常看重可以同时跑多少路的问题。目前,用传统的,拼接或者参数法,合成的一部20万字的长篇小说,成本大约是五块钱以下。如果大规模的使用神经网络,在这方面,成本会大大增加。
3.稳定性隐患。端到端的网络,有一个很明显的缺点在于不好调试。太依赖神经网络的自我学习能力,一旦出了错误,不好定位。如果真的要投到业务中使用没有,需要经过几万几十万的,大规模测试,发错音错字,跳字,或者停顿混乱这样的风险系数非常大。以tacotron为例,从Bahdanau arrention到location attention再到现在的forward attention,错漏字的情况明显好转了,但是仍然有缺陷。
对于跨域种和多特征人少样本这种应用场景下,端到端的网络仍然有明显优势
就拿你所说的四个方案(tacotron、deepvoice、char2wav、wavenet)来说,实际上基本合并为两个——谷记的tacotron(2代合并了wavenet),以及百度的deepvoice。至于char2wav,很久没听说过后续的消息,就没再关注了……
个人以为,基于深度学习的TTS已经过了“热炒期”,它已经不是一个概念,而是真正落地了的产品。且不论谷歌已经开放了基于Tacotron2的平台,就是知乎安卓手机端,随便进入一篇专栏文章,你都可以在左上角发现“为你朗读”四个字,然后你就可以检验deepvoice的合成效果了——没错,知乎安卓端的TTS用的就是百度的服务。
Tacotron2开放平台:https://cloud.google.com/text-to-speech/
deepvoice的开放平台:语音合成-百度AI
不过说起TTS,怎么能忽略科大讯飞呢?只不过讯飞方案不是“端到端”而已,但就全球TTS评测而言,讯飞是冠军,这是有真凭实据的。放一个效果(amazing):李易生前配音和语音合成对比,经典的“时代之音”终于重现啦!
(不完全回答,待补充)
最近公司想做TTS,声纹的坑先暂时搁置。。
Text-to-speech顾名思义,输入一段文本,输出一段语音(物理上也可以看作波)。
主要方法有:拼接法,参数法,混合法和神经网络学习
1.拼接法
顾名思义,把每个字(词)拆分成更小的单元,拼接到一起。方法过于粗暴不细讲了。
2.参数法(传统机器学习)
流程:
训练:统计模型学习语音特征和声学特征的关系
生成(预测):用模型预测出声学特征(比如基频、共振峰频率等),将声学特征还原成波形
模块:
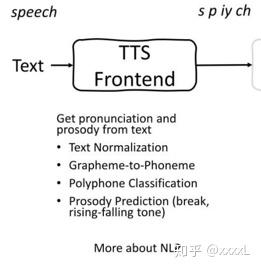 前端
前端
前端:将任意文本转为语言学特征,通常包括文本正则化,分词,词性预测,字音转字形(Grapheme-to-Phoneme),多音字(Polyphone)消歧、韵律估计等子模块。文本正则化可以将一些书面表达转为口语表达,如1%转为“百分之一”,1kg转为“一千克”等。分词和词性预测是韵律估计(Prosody Prediction)的基础。字形转音形将speech转化成音素s p iy ch。韵律词和韵律短语会在分词和词性信息的基础上生成。
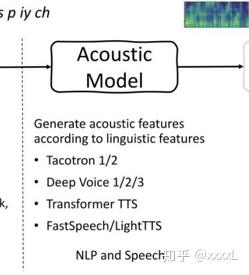 声学模型
声学模型
模型:基于前端的发音或语言学信息提取特征,常用的是Mel频谱图。常用模型例如:Tacotron 1/2,Deep Voice 1/2/3, Transformer TTS,FastSpeech, LightTTS
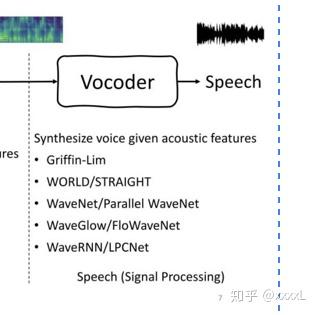 声码器
声码器
声码器:将声学特征转为语音波形,有相位恢复算法Griffin Lim,传统声码器WORLD和STRAIGHT,神经声码器WAVENET,WAVERNN,SAMPLERNN和WAVEGLOW
3. 混合法
拼接法+参数法混合
4. 神经网络
也常称为端到端(end2end),原因是省去了语言学标注文本+模型声码器二合一
Tacotron:只省去了语言学标注,还需要声码器
Wavenet:只省去声码器,还需要语言学标注
5. 声道模拟法
声道-激励源模型。建立声道的物理模型,通过这个物理模型产生波形。可以看作是参数法的一种,物理建模太复杂,理论优美使用门槛高
ref
【技术专题】端到端语音合成-从入门到放弃(1)语言学分析微软亚洲研究院谭旭:低资源场景下的 TTS 文本到语音的合成mp.weixin.qq.com