自从有娃以后,很久没有时间好好摸一摸编程了,周末的时候正好出门溜娃,就想到了空气质量的问题,虽然有APP啊上海发布啊之类的可以查,但我偏偏就是手贱要爬米帝领事馆的数据。(PM2.5监测网上的监测站点更多,但数据似乎总是低于美国领事馆公布的AQI)
是时候捡起python了!于是回到家,等孩子他妈哄睡了宝宝之后(妈妈真辛苦),我开始研究怎么实现我想要的功能。首先我上了一下数据监测页面http://aqicn.org/city/shanghai/quanshipingjun/cn/

右侧就是我们想要的每个监测点的数据,然而这是个动态网页,让我一个只学过怎么爬静态网页的人一脸懵逼……一番搜刮学习之后我找到了解决之道——一切没解决的问题都可以先用F12解决!
打开浏览器的F12,切换到Network标签,观察下面的JS或者XHR,试着拖动那张地图,看看下方的列表有没有变化,果然,每拖动一次XHR下就会生成1条记录,点进去一看,嘿~嘿~嘿~这不就是我们要的东西吗?

点击左侧的Headers还能看到动态网页的网址:
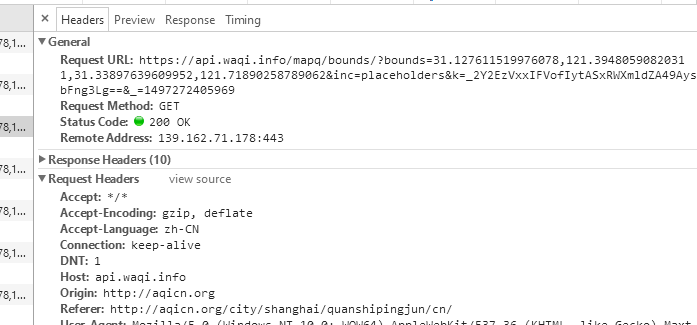
我们把这个网址复制下来,并解析,形如:
https://api.waqi.info/mapq/bounds/?bounds=31.043521630684204,121.19293212890624,31.466153715024294,121.84112548828125&inc=placeholders&k=_2Y2EzVxxIDVsfIydASBRWXmldZA4+LREbFkY3ZQ==&_=1497098578289
好长……是不是有点累觉不爱了?不过仔细看一下的话,bounds=后面的东西像不像坐标?这应该指的就是这张图的边界。多抓几次就会发现,每次不一样的除了坐标就只有最后那串数字,每次都不一样。我猜想这个会不会和时间有关呢?于是我每隔10秒移动一次地图,发现果然,每十秒钟差不多增加10000单位,那就是时间戳没跑了(其实后来发现,及时每次提交的时间戳即使一毛一样数据也会自动刷新……)。知道了这些之后就是写网页解析的代码了,这个就没太大难度了。
1 url ="https://api.waqi.info/mapq/bounds/?bounds=31.064698120353743,121.201171875,31.487235582017444,121.84936523437499&inc=placeholders&k=_2Y2EzVxxIDVsfIydASBRWXmldZA4+LREbFkY3ZQ==&_=1497098578289" #动态网页网址 2 3 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' 4 headers = { 'User-Agent' : user_agent } #头文件 5 6 try: 7 request = urllib.request.Request(url,headers = headers) 8 response = urllib.request.urlopen(request) #获取数据 9 except urllib.error.URLError as e: 10 if hasattr(e,"code"): 11 print(e.code) 12 if hasattr(e,"reason"): 13 print(e.reason) 14 15 aqi_trans=json.load(response) #json数据的解析 16 """ 17 aqi_trans[0]数据结构: 18 {'aqi': '68', 19 'city': 'Yangpu Sipiao, Shanghai (上海杨浦四漂)', 20 'idx': 702, 21 'img': '_c_azCs5IzEvPSMzUfzZ3xbOty57Onv1sTxMA', 22 'lat': 31.2659, 23 'lon': 121.536, 24 'pol': 'pm25', 25 'stamp': 1497160800, 26 'tz': '+0800', 27 'utime': '2017-06-11 14:00:00', 28 'x': '482'} 29 共11个数据点 30 """
这里我们得到的aqi_trans是一个列表,列表中的每个元素都是一个字典,字典的内容就是监测站的名称啦,AQI指数啦,经纬度啦之类的信息。
之后就是简单的数据整理,这就交给pandas了。这里我选择了4个数据,idx应该是监测点的索引(但隔一段时间会换,不过序列情况不变),utime就是监测的时间,city是监测点的名字,用正则表达式去掉括号,AQI就是空气质量指数啦~不过AQI只有数值,没有等级,但这个很简单,一个cut函数就解决了。
1 aqi_table=pd.DataFrame(columns=['Idx','Time','Site','AQI']) 2 3 for i in range(len(aqi_trans)): 4 pos_idx=int(aqi_trans[i]['idx']) 5 record_time=aqi_trans[i]['utime'] 6 site=re.findall(r'上海S*(?=))',aqi_trans[i]['city'])[0] #正则,提取括号里的文字 7 aqi=int(aqi_trans[i]['aqi']) 8 aqi_table=aqi_table.append({'Idx':pos_idx,'Time':record_time,'Site':site,'AQI':aqi},ignore_index=True) 9 aqi_table=aqi_table.sort_values('Idx',ascending=True) 10 aqi_table=aqi_table.set_index(pd.Series(range(0,11))) 11 aqi_table['Level']=pd.cut(aqi_table['AQI'],[0,50,100,150,200,300,10000],labels=[u'优',u'良',u'轻度污染',u'中度污染',u'重度污染',u'严重污染']) #打标签
最后我决定写一个函数,把获取AQI的功能打包一下,然后定时运行一下这个函数(领事馆数据貌似每小时更新一次),监测的数据就放进一个csv文件里,方便后续处理。汇总一下代码如下:
import urllib #python 3中urllib和urllib2合并了,很多语法不同了 import json import re import pandas as pd def Get_AQI(t): url ="https://api.waqi.info/mapq/bounds/?bounds=31.064698120353743,121.201171875,31.487235582017444,121.84936523437499&inc=placeholders&k=_2Y2EzVxxIDVsfIydASBRWXmldZA4+LREbFkY3ZQ==&_=%d"%(t) #这里用的是动态时间戳,但时间戳好像并不影响数据的实时性,那只要隔一段时间提交一次同样的网址就行了 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } try: request = urllib.request.Request(url,headers = headers) response = urllib.request.urlopen(request) except urllib.error.URLError as e: if hasattr(e,"code"): print(e.code) if hasattr(e,"reason"): print(e.reason) aqi_trans=json.load(response) aqi_table=pd.DataFrame(columns=['Idx','Time','Site','AQI']) for i in range(len(aqi_trans)): pos_idx=int(aqi_trans[i]['idx']) record_time=aqi_trans[i]['utime'] site=re.findall(r'上海S*(?=))',aqi_trans[i]['city'])[0] aqi=int(aqi_trans[i]['aqi']) aqi_table=aqi_table.append({'Idx':pos_idx,'Time':record_time,'Site':site,'AQI':aqi},ignore_index=True) aqi_table=aqi_table.sort_values('Idx',ascending=True) aqi_table=aqi_table.set_index(pd.Series(range(0,11))) aqi_table['Level']=pd.cut(aqi_table['AQI'],[0,50,100,150,200,300,10000], labels=[u'优',u'良',u'轻度污染',u'中度污染',u'重度污染',u'严重污染']) #分段打标签 return aqi_table import time sleep_time=1800 #30分钟运行一次 if __name__ == '__main__': while True: now_time=int(time.time()*1000) aqi_database=Get_AQI(now_time) aqi_database.to_csv('D:\AQI\aqi_database.csv',mode='a+') #记录csv文件,a+为追加写入 print(time.ctime()) print(Get_AQI(now_time)) time.sleep(sleep_time)
终于磕磕绊绊地码完了,发现自己果然忘了不少东西,python3和python2也有很多不同点了,还需要学习一个,提高姿势水平啊~心满意足之余,我还YY了一下把这功能放在一个树莓派里,然后定时给微信推送,白日梦真是美妙极了~
啊~白日梦……