概述
相比Hadoop MapReduce来说,Spark计算具有巨大的性能优势,其中很大一部分原因是Spark对于内存的充分利用,以及提供的缓存机制。
RDD持久化(缓存)
持久化在早期被称作缓存(cache),但缓存一般指将内容放在内存中。虽然持久化操作在绝大部分情况下都是将RDD缓存在内存中,但一般都会在内存不够时用磁盘顶上去(比操作系统默认的磁盘交换性能高很多)。当然,也可以选择不使用内存,而是仅仅保存到磁盘中。所以,现在Spark使用持久化(persistence)这一更广泛的名称。
如果一个RDD不止一次被用到,那么就可以持久化它,这样可以大幅提升程序的性能,甚至达10倍以上。
默认情况下,RDD只使用一次,用完即扔,再次使用时需要重新计算得到,而持久化操作避免了这里的重复计算,实际测试也显示持久化对性能提升明显,这也是Spark刚出现时被人称为内存计算框架的原因。
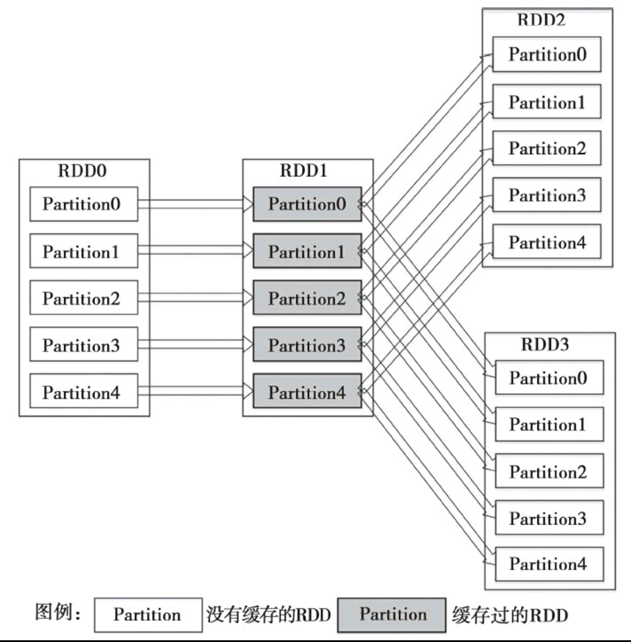
假设首先进行了RDD0→RDD1→RDD2的计算作业,那么计算结束时,RDD1就已经缓存在系统中了。在进行RDD0→RDD1→RDD3的计算作业时,由于RDD1已经缓存在系统中,因此RDD0→RDD1的转换不会重复进行,计算作业只须进行RDD1→RDD3的计算就可以了,因此计算速度可以得到很大提升。
持久化的方法是调用persist()函数,除了持久化至内存中,还可以在persist()中指定storage level参数使用其他的类型,具体如下:
1)MEMORY_ONLY : 将 RDD 以反序列化的 Java 对象的形式存储在 JVM 中. 如果内存空间不够,部分数据分区将不会被缓存,在每次需要用到这些数据时重新进行计算. 这是默认的级别。
cache()方法对应的级别就是MEMORY_ONLY级别
2)MEMORY_AND_DISK:将 RDD 以反序列化的 Java 对象的形式存储在 JVM 中。如果内存空间不够,将未缓存的数据分区存储到磁盘,在需要使用这些分区时从磁盘读取。
3)MEMORY_ONLY_SER :将 RDD 以序列化的 Java 对象的形式进行存储(每个分区为一个 byte 数组)。这种方式会比反序列化对象的方式节省很多空间,尤其是在使用 fast serialize时会节省更多的空间,但是在读取时会使得 CPU 的 read 变得更加密集。如果内存空间不够,部分数据分区将不会被缓存,在每次需要用到这些数据时重新进行计算。
4)MEMORY_AND_DISK_SER :类似于 MEMORY_ONLY_SER ,但是溢出的分区会存储到磁盘,而不是在用到它们时重新计算。如果内存空间不够,将未缓存的数据分区存储到磁盘,在需要使用这些分区时从磁盘读取。
5)DISK_ONLY:只在磁盘上缓存 RDD。
6)MEMORY_ONLY_2,
MEMORY_AND_DISK_2, etc. :与上面的级别功能相同,只不过每个分区在集群中两个节点上建立副本。
7)OFF_HEAP 将数据存储在 off-heap memory 中。使用堆外内存,这是Java虚拟机里面的概念,堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。使用堆外内存的好处:可能会利用到更大的内存存储空间。但是对于数据的垃圾回收会有影响,需要程序员来处理
注意,可能带来一些GC回收问题。
Spark 也会自动持久化一些在 shuffle 操作过程中产生的临时数据(比如 reduceByKey),即便是用户并没有调用持久化的方法。这样做可以避免当 shuffle 阶段时如果一个节点挂掉了就得重新计算整个数据的问题。如果用户打算多次重复使用这些数据,我们仍然建议用户自己调用持久化方法对数据进行持久化。
使用缓存
scala> import org.apache.spark.storage._
scala> val rdd1=sc.makeRDD(1 to 5)
scala> rdd1.cache //cache只有一种默认的缓存级别,即MEMORY_ONLY
scala> rdd1.persist(StorageLevel.MEMORY_ONLY)
缓存数据的清除
Spark 会自动监控每个节点上的缓存数据,然后使用 least-recently-used (LRU) 机制来处理旧的缓存数据。如果你想手动清理这些缓存的 RDD 数据而不是去等待它们被自动清理掉,
可以使用 RDD.unpersist( ) 方法。