序言
这算是hibernate的最后一篇文章了,下一系列会讲解Struts2的东西,然后说完Struts2,在到Spring,然后在写一个SSH如何整合的案例。之后就会在去讲SSM,在之后我自己的个人博客应该也差不多可以做出来了。基本上先这样定下来,开始完成hibernate的东西把。这章结束后,我会将我一些hibernate的资料奉上,供大家一起学习。
---WH
一、概述
这章总的分两大块来讲解,
第一大块,hibernate的事务管理。,对于hibernate的事务管理来说,如果之前学过数据库的事务管理,那么在这里就顺风顺水了。如果没学过,第一次遇到,那也没关系,我会详细解释其中的内容。
第二大块,hibernate的二级缓存机制。这个看起来好高大上啊,如果从来没了解过二级缓存的人肯定觉得他很难,但是学过会发现,真的是so easy。最起码会知道什么是二级缓存,作用是什么。
二、hibernate的事务管理
2.1、回顾数据库的事务的特性和隔离级别
2.1.1、什么是事务?
事务是一组业务逻辑,比如A去银行给B转钱,A转了100块给B(update语句更新A的钱减少一百),B收到钱(update语句更新B的钱增加一百),这转钱整个过程称为事务,注意,不要觉得A转钱给B,A做完了操作,就是事务了,要记住事务是一组业务逻辑,两个在一起才是事务。在比如有一个数字5,现在有一个事务A,事务A做的事情就是将5变为4,该事务要做的事情有,拿到5,然后5-1,然后数据库中的5变为了4,这才算这个事务A真正的成功了,可以那么说,业务逻辑太抽象了,事务就是一组操作,只有整个操作在一起才算是一个事务。就向上面说的,转钱也是一个事务,它做的操作就只有两个,A减少钱,B增加钱。
2.1.2、事务的特性ACID
A(atomicity):原子性:事务不可被划分,是一个整体,要么一起成功,要么一起失败
C(consistence):一致性,A转100给B,A减少了100,那么B就要增加100,增加减少100就是一致的意思
I(isolation):隔离性,多个事务对同一内容的并发操作。
D(durability):持久性,已经提交的事务,就已经保存到数据库中,不能在改变了。
2.1.3、事务隔离性产生的问题
跟线程安全差不多,多个事务对同一内容同时进行操作,那么就会出现一系列的并发问题。一定要注意,这个是两个或者多个事务同时对一个内容进行操作,是同时,而不是先事务A操作完,然后事务B在操作,这个要理解清楚。
2.1.3.1、脏读:一个事务 读到 另一个事务 没有提交的数据。
A给B转100块钱(事务A),A在ATM机上转,将100块钱放到ATM机里了,然后ATM机会最后询问A,确定转账100给B吗,A还没点确定这个时候,B在另外一个ATM机上就发现账户上多了100块钱,然后高兴的取走了这100块钱,B取钱(事务B)但是此时A觉得不行,觉得还是拿现金给B比较好,然后就点了取消,把放到ATM机中的100块钱给拿了回来。这其中,A转钱给B(事务A)、B取钱(事务B),也就发生了事务B读到了事务A没有提交的数据,也就是脏读。注意:要明白事务是什么,才能理解这些东西。还有,刚开始接触可能会觉得这是不可能发生的呀,怎么会读到还没有提交的数据呢?这里只是说明这个是一个问题,现实生活中肯定没有呀,银行也不会出现这种问题,因为已经全部解决掉了,但是这种问题肯定是存在的,该如何解决呢?这就是我们后面需要讨论的东西。现在只需要知道事务隔离会产生这种问题就行了。
2.1.3.2、不可重复读:一个事务 读到 另一个事务 已经提交的数据(update更新语句)
解释:有时候不可重复读是一个问题,有时候却不是。这要看业务需求是怎么样的,就好比银行转钱的事情,事务A(A给B转钱),事务B(B取钱),A在ATM机上插卡转钱给B,同时B也将银行卡插入ATM机中准备查看A是否转了钱给B,当A事务结束后,也就是A转账成功后,B就查到了自己账户上多了100块钱,这就是事务B读到了事务A已经提交的数据。这个例子不可重复读就不是个问题。此业务逻辑中,就不需要解决这个问题。在别的业务中,可能这个就是个问题了。比如,一个公司,每个月15号给员工结算工资,工资数是从上个月15号到这个月15号根据每个人提交的工作量来结算的,但是会计师A在这个月15号从数据库中拿每个员工的工作记录量的数据做工资的统计的同时,员工B在次提交了一次工作量(将数据库中B的工作量增加了),此时会计师A在结算员工B的工资时,就会把前面30天的工作量和他今天提交的工作量一起算工资,到了下个月15号,又会把员工B这次提交的工作量算在它当前月的总工作量中,这样一来,就相当于给B多算了一次工作量的工资。这样就不合理了。
2.1.3.4、虚度(幻读):一个事务 读到 另一个事务 已经提交的数据(insert插入语句)
这个跟不可重复读描述的问题是一样的,但是其针对的事务不一样,不可重复读针对的是做更新的事务,比如转钱呀等,都是做更新的事务,而这个虚读针对的是做插入的事务,比如,在工地有很多人做事,工地有规定,做了事的中午才包饭,到了中午的时候,工地负责人要去给做事的工人买盒饭,就要统计人数,现在工地也会用电脑了,负责人就到电脑上查有多少人做事,来决定买多少盒饭,就在查人数的时候,另一个专门招工人的负责人招到一个工人,就把该工人的信息输入到数据库里面,然后买盒饭的负责人在电脑上一查数据库,发现有N个人,刚招进来的工人也在其中,然后就也给那个没做事的,刚招进来的员工买了盒饭,这是不符合规定的。这只是举一个这样的例子,帮助大家理解,一个盒饭也不贵,觉得无所谓,但是如果是涉及很重要的东西时,就不能出现这种问题。
2.1.4、事务隔离级别,用于解决隔离问题
2.1.4.1、read uncommitted :读未提交,一个事务 读到 另一个事务 没有提交的数据,存在问题3个,解决0个问题
2.1.4.2、read committed:读已提交,一个事务 读到 另一个事务 已经提交的数据,存在问题2个,解决1个问题(脏读问题)
2.1.4.3、repeatable read:可重复读,一个事务 读到重复的数据,即使另一个事务已经提交。存在问题1个,解决2个问题(脏读、不可重复读)
2.1.4.4、serializable:单事务,同时只有一个事务可以操作,另一个事务挂起(暂停),存在问题0个,解决3个问题(脏读、不可重复读、虚读)
注意:一定要搞清楚上面三个问题(脏读、不可重复读、幻读)是什么样的情况,你才能知道这四种隔离级别为什么能够解决这些问题。切记,如果看我的话还是觉得这几个问题模糊不清,就请留言告诉我你的疑问,因为如果不明白这三个问题,那么后面你将一直会混淆。
2.1.5、使用MySQL来进行隔离级别的演示
这里就不写代码了,直接上文字,让你们熟悉一下事务隔离级别的使用。
顺便说一句,MySQL默认的隔离级别:repeatable read Oracle默认的隔离级别:read committed
MySQL默认事务提交的,也就是在cmd中每执行一条sql语句就是一个事务,所以如果你要进行实验就必须先关闭MySQL的自动事务提交,并改为手动,set autocommit=0
2.1.5.1、read uncommitted
A隔离级别:读未提交,会发生脏读问题
AB同时开始事务,
A先查询 --正常数据
B更新,但未提交
A在查询 --读到B没有提交的数据
B回滚 --B没有提交数据,回滚的话,就相当于刚才的更新语句并没有执行
A再查询 --读到回滚后的数据,也就是原来的正常数据。
2.1.5.2、read committed
A隔离级别:读已提交
AB同时开启事务
A 先查询 --正常
B 更新,但未提交
A再查询 --得到的还是之前的数据,并没有拿到B没有提交的数据, 解决问题:脏读
B 提交
A 再查询 -- 已经提交的数据。问题:不可重复读(到这里就不要在纠结为什么不可重复读是个问题了,上面已经解释清楚了,根据不同的业务,可能是问题,也可能不是)
2.1.5.3、repeatable read
A隔离界别:可重复读,保证当前事务中读到的是重复的数据
AB 同时开启事务
A 先查询 --正常
B 更新,但未提交
A 再查询 -- 之前数据,解决:脏读
B 提交
A 再查询 -- 之前数据,解决:不可重复读
A 回滚|提交
A 再查询 -- 更新后数据,新事务获得最新数据
2.1.5.3、serializable
A隔离级别:串行化,单事务
AB 同时开启事务
A 先查询 --正常
B 更新 -- 等待 (对方事务A结束或者超时B才能进行。)
2.1.6、丢失更新问题 lost update
这个丢失更新问题也是属于事物隔离性产生的问题之一,但是不同上面所说的三个,上面所说的脏读、不可重复读、虚读,都是一个事务 拿到了 另一个事务所提交或者未提交的数据而产生的问题,而丢失更新并不拿对方事务所提交的数据,那丢失更新描述的是一个什么样的问题呢?
A 查询数据,username = 'jack' ,password = '1234'
B 查询数据,username="jack", password="1234'
A更新密码,用户名不变 username='jack',password='456' //A将密码更新完后,将其保存到数据库中了
B更新用户名,username='rose',password='1234' //B更新之后,数据库中的数据就为 username='rose',password='1234'
丢失更新:最后更新数据,将前面更新的数据给覆盖了。那A之后就发现自己刚设置的密码登录不上了,这就出现了丢失更新问题,解决的方法有两种
解决方法一:
乐观锁
认为丢失更新一定不会发生,非常乐观,在数据库表中添加一个字段,可以说是标识字段把,用于记录操作次数的,比如如果对有人拿到了该行记录做了更新操作,该字段就加1。然后下一个拿到该记录的人要先将拿到的记录的标识和数据库中该记录的标识做对比,如果一样,则可以修改,并且修改后标识(版本)+1,如果不一样,先从数据库中查询,然后在做更新。举个例子
A 查询数据,username = 'jack' ,password = '1234',version=1
B 查询数据,username="jack", password="1234',version=1 //AB同时拿到数据库中数据,且version读为1
A更新密码,用户名不变 username='jack',password='456',version=2 //先和数据库中该行记录的version做对比,拿到的version是1,跟数据库中一样,所以能做更新,A将密码更新,version+1,然后将其保存到数据库中(注意,这里写的是A更新之后的的数据。 不要搞混了。)
B更新用户名,username='rose',password='1234',version=1 //B想要更新时,先和数据库中该条记录的版本号做对比,发现不一样,然后查询
B重新查询数据, 用户名不变 username='jack',password='456',version=2 //然后在进行对比,这次version一样了,B就可以实现更新操作了。
B更新用户名,username='rose',password='456',version=3 //更新后,version+1
解决方法二:
悲观锁
认为丢失更新一定会发生,此时采用数据库锁机制,也就是相当于谁操作了该记录行,就会在上面加把锁,别人进不去,只有等你操作完之后,该锁就释放,别人就可以操作了。跟那个隔离级别单事务差不多。但是锁也分很多种。
读锁:共享锁,大家可以一起读数据,但是不能一起操作(更新,删除,插入等)
写锁:排他锁,只能一个进行写,也就是上面我们说的原理。
2.2、hibernate中对事务产生的隔离性问题以及解决方案
上面通过很大的篇幅讲解数据库的事务相关问题,就是为了讲解hibernate中的事务做铺垫,懂了上面这些,那么这里就顺风顺水了。
2.2.1、hibernate中设置事务隔离级别,隔离级别是为了解决事务隔离性产生的问题的。
在hiberante.cfg.xml文件中配置 hibernate.connection.isolation 隔离级别
有四种隔离级别可选择,后面的数字表示在设置隔离级别的时候,直接写数字也是可以代表对应的隔离级别的,比如 hibernate.connection.isolation 4 跟hibernate.connection.isolation Repeatable read 是一样的。
Read uncommoitted isolation 1
Read committed isolation 2
Repeatable read isolation 4
Serializable isolation 8

2.2.2、hibernate中丢失更新问题的解决
悲观锁: 就是认为一定会发生丢失更新问题,采取锁机制
User user = (User) session.load(User.class,1,LockMode.UPGRADE);
乐观锁:
hibernate 为Customer表 添加版本字段
1) 在User类 添加 private Integer version; 版本字段
2) 在User.hbm.xml 定义版本字段
<!-- 定义版本字段 -->
<!-- name是属性名 -->
<version name="version"></version>

如果产生了丢失更新就会报异常

总结:
1、如果知道了数据库中事务的知识,那么在hibernate中就非常简单,只是简单的配置一下就OK了。所以在hibernate的事务讲解这里篇幅就比较少,重要的还是需要弄懂前面的知识。很重要。
三、hibernate的二级缓存
说点废话,二级缓存理解起来真的非常非常简单,大家不要觉得怕,就三个内容,知道什么是二级缓存,如何使用它,就没了。
3.1、什么是二级缓存
我们知道一级缓存,并且一级缓存的作用范围就在session中,每个session都有一个自己的一级缓存,而二级缓存也就是比一级缓存的作用范围更广,存储的内容更多,我们知道session是由sesssionFactory创建出来的,一个sessionFactory能够创建很多个session,每个session有自己的缓存,称为一级缓存,而sessionFactory也有自己的缓存,存放的内容供所有session共享,也就是二级缓存。 是不是很简单?还不理解看下面我画的一张图就一目了然了。

一级缓存:保存session中,事务范围的缓存(通俗点讲,就是session关闭后,该缓存就没了,其缓存只能在session的事务开启和结束之间使用)
二级缓存,保存在SessionFactory,进程范围内的缓存(进程包括了多个线程,也就是我们上面说的意思,A线程可能拿到一个session进行操作,B线程也可能拿到一个session进行操作,但是A和B读能访问到SessionFactory中的缓存,也就是二级缓存,这里只是拿A,B说事,可能有一个线程刚创建出来session,也能拿到二级缓存中的数据)
3.2、二级缓存的作用?优点
这个可能要到实际开发工作中才会知道二级缓存有哪些用处,现在给出一些我认为比较好的答案,因为我还没真正到去工作,所以目前也只是理解其内容。
。。。。
3.3、二级缓存的内部结构
类缓存区域
比如:session.get(Customer.class,1); //这就是类缓存区域
集合缓存区域
customer.getOrders(); //就是存放Orders集合的内容的缓存区域就叫集合缓存区域
更新时间戳区域
查询缓存区域
这几个在后面会详细讲到,现在不讲,想直接看的就跳过看后面测试实例。
3.4、二级缓存的并发访问策略配置。
为什么要讲解这个呢?想一下,二级缓存是sessionFactory中的,其sessionFactory创建出来的session都可以共享它,所以其中就会出现并发问题,也就是我们一开始讲的一些事务隔离性问题。为了解决这些问题,hibernate也提供了相应的方法,就是二级缓存的并发访问策略,总共有四种,通过一张表格来看把,通过下面这张图,我们应该就知道了其实跟开始讲的差不多,换了一个名词而已。并且如果要使用二级缓存,就必须配置这个病房访问策略,不然是用不了二级缓存的,就好比你已经有了二级缓存,其中也有内容,但是你没有设置访问方式,就访问不出来。
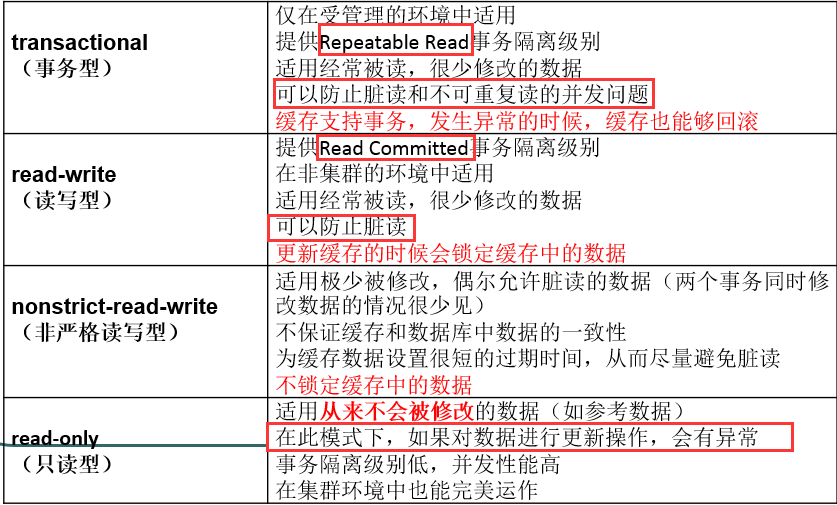
在配置二级缓存之后,就要相应的配上其二级缓存并发访问策略。
3.5、如何配置二级缓存?
分两大步,第一步单纯配置二级缓存,第二步配置二级缓存的并发访问策略。第三步,配置ehcache.xml
3.5.1、配置二级缓存
要使用二级缓存,需要导入其它的组件来帮我们完成,而hibernate本身是有一个默认的二级缓存组件,但是平常我们不用,一般是用EhCacheProvider,来了解一下hibernate所能支持的二级缓存组件提供商

1、我们使用Ehcache,所以导入其jar包

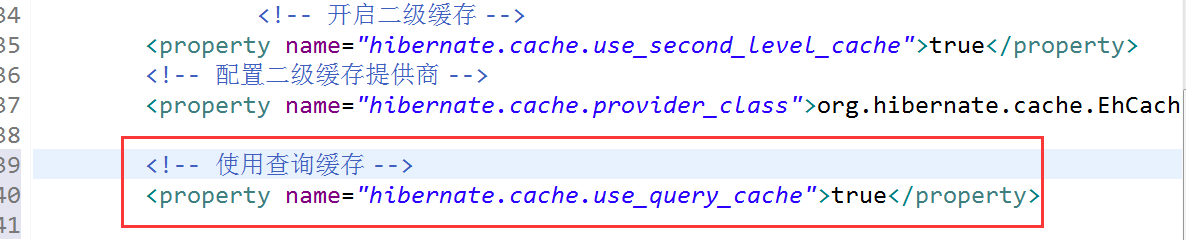
2、在hibernate.cfg.xml文件中配置,开启二级缓存,
![]()
3、在hibernate.cfg.xml文件中配置二级缓存提供商
![]()
开启二级缓存就只需要三步,就上面三步,然后开始配置我们的并发访问策略。
3.5.2、配置二级缓存的并发访问策略
二级缓存组件所能支持的并发访问策略。 为什么
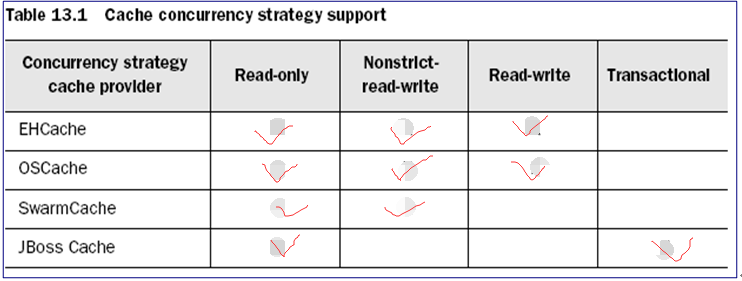
今天我们要用的就是EHCache,它不支持Transactional这种并发访问策略,所以我们使用的是read-write这种并发访问策略,read-write提供的就是read committed事务隔离级别,能够防止脏读,具体的功能就看上面的表格。
配置方案有两种
1、xxx.hbm.xml文件中配置
可以在<class>标签下配置<cache usage=”read-write”> 类级别
可以在<set>标签下配置<cache usage=”read-write”> 集合级别
2、hibernate.cfg.xml文件中配置

3.5.3、配置ehcache.xml文件
将 ehcache-1.5.0 jar包中 ehcache-failsafe.xml 改名 ehcache.xml 放入 src。 这非常简单。如果使用的别的组件缓存,则在相同位置也有类似的文件。
3.6、测试二级缓存的存在
3.6.1、搭建测试环境
并且将上面的步骤自己搭建好,三步走,注意:使用的业务逻辑是Dept-Staff,也就是部门和职工的关系。
1、配置二级缓存,也就是将一些组件缓存提供商弄好

2、配置并发访问策略,这里其实就自由配置了,如果你想在二级缓存中只存取某个类的值,那么就在xxx.hbm.xml中配置一下其访问策略
这里,我先只对dept进行read-write的访问策略,然后等会进行测试

3、添加ehcache.xml
3.6.2、测试二级缓存是否存在

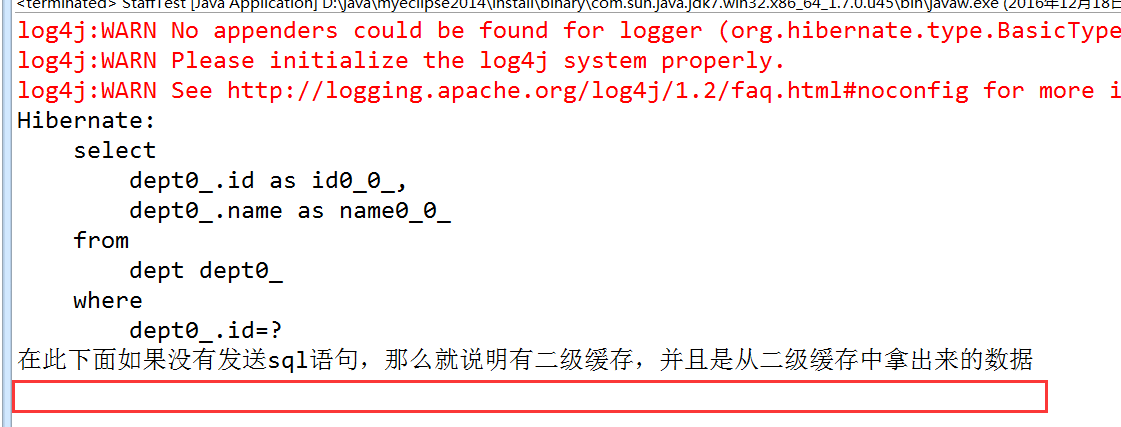
3.6.3、注意get/load可以从二级缓存中获取数据,而query的list不能从二级缓存获取数据,但是其查询结果会存入二级缓存。
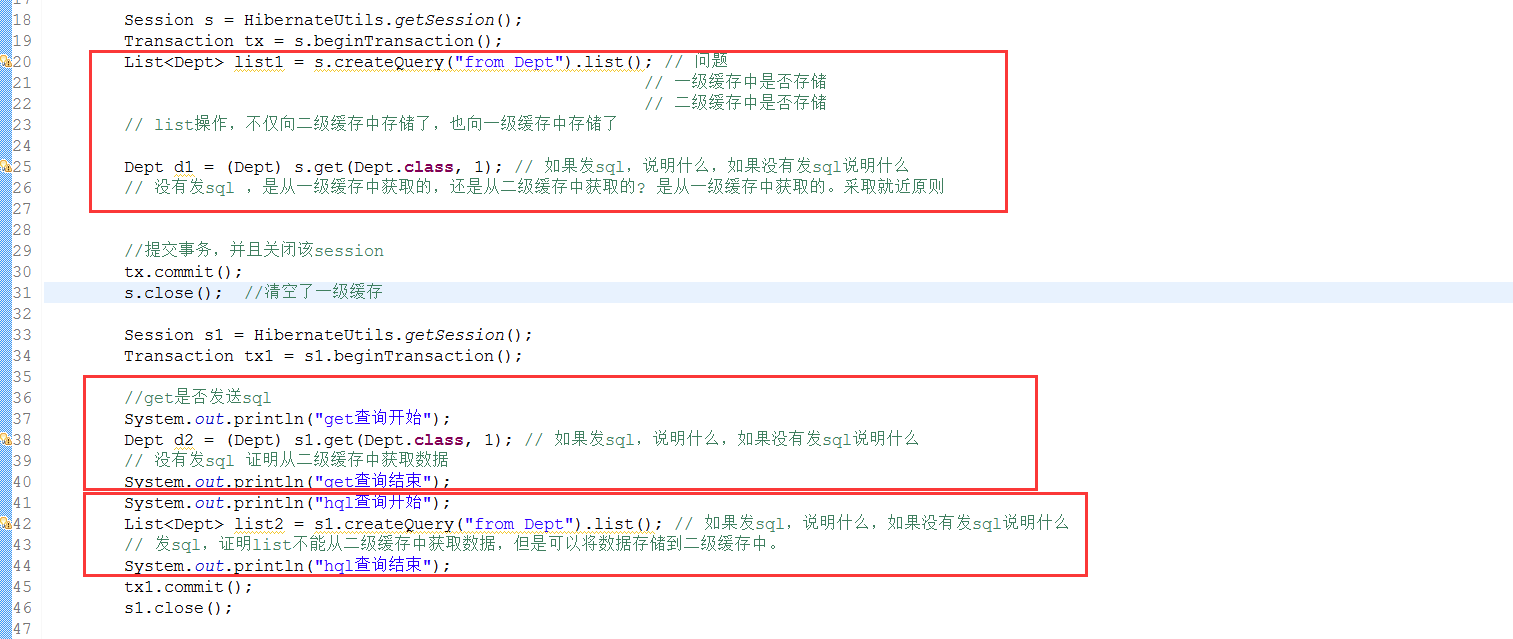

小结:
hql做的查询能够存入一级缓存和二级缓存,但是不能够从二级缓存中拿数据
getload能够将其查询数据插入一级缓存和二级缓存,也能够从一级二级缓存中拿数据。
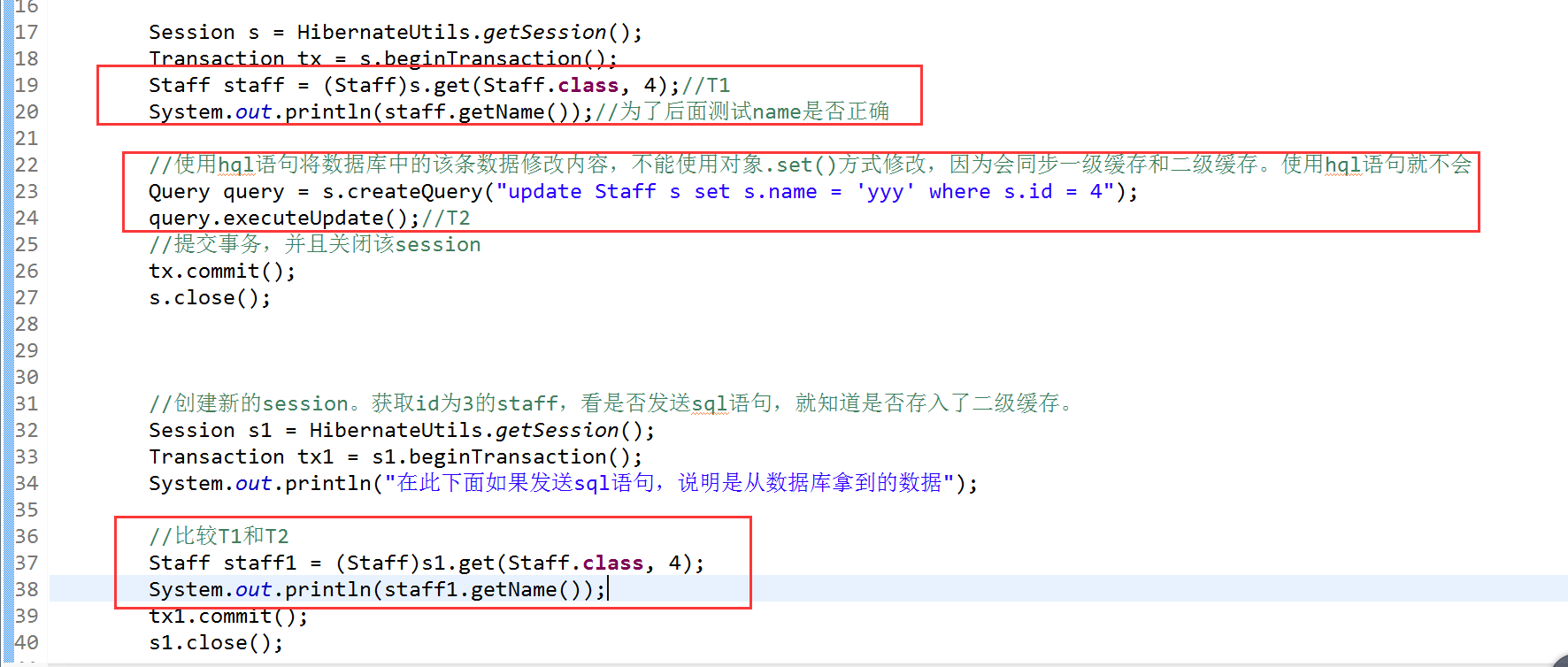
3.6.4、一级缓存数据会同步二级缓存
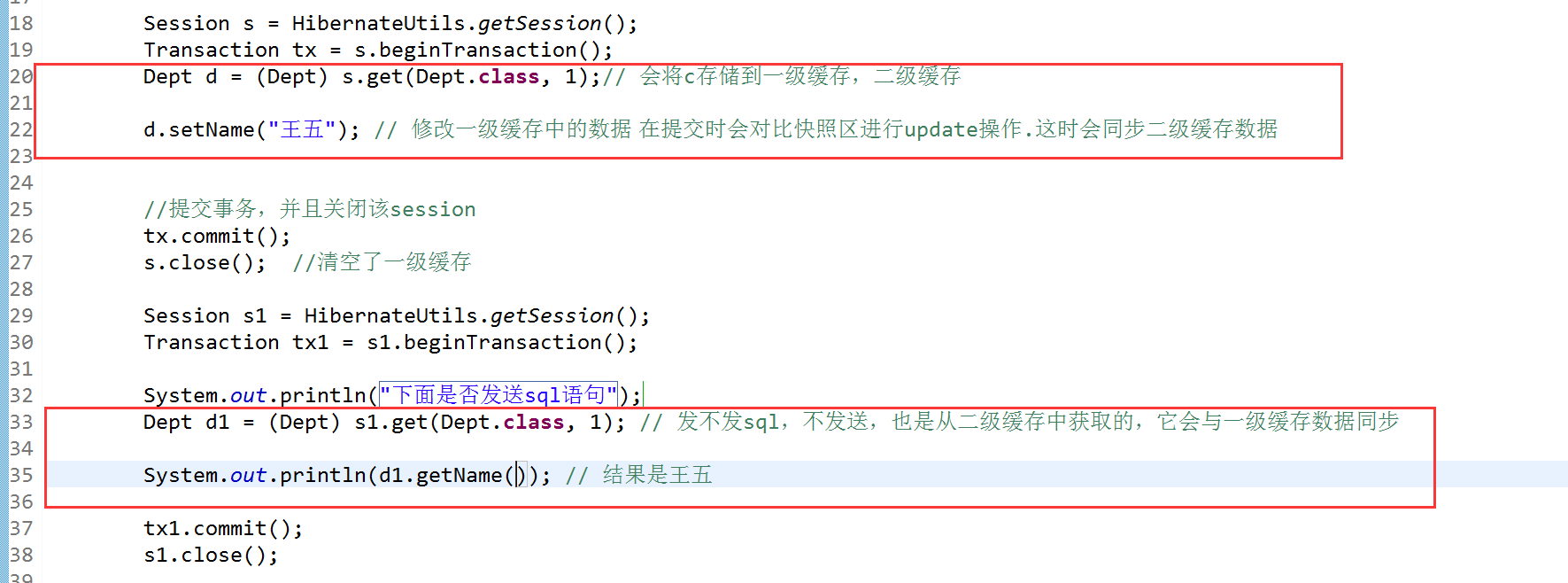

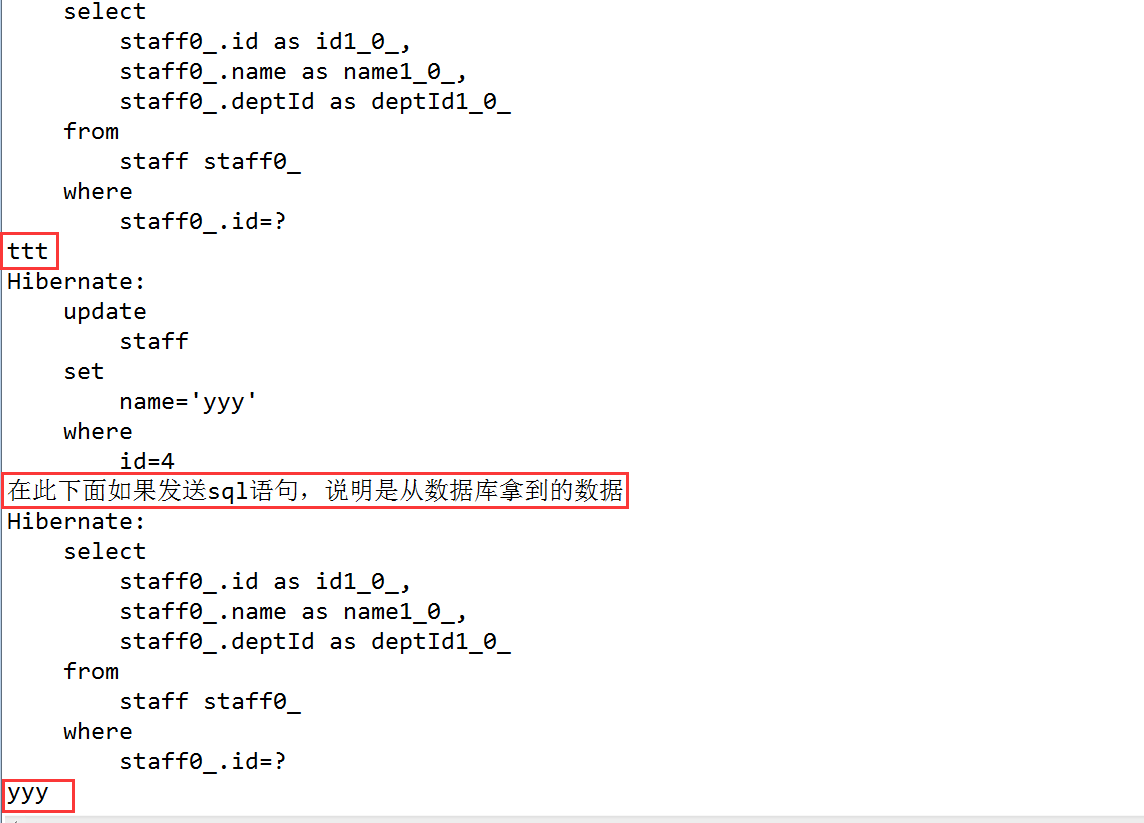
注意:如果是用hql来更新修改name,那么就不会同步二级缓存,连一级缓存中的数据也不会改变,hql是直接针对数据库来进行修改的,而set()方法是通过hibernate中的快照区,而不是直接对数据库进行操作。
3.6.5、测试二级缓存中的四种缓存区域
3.6.5.1、类缓存区域
类缓存区域,通过id查询到的对象,就将其放入类缓存区域,其区域中缓存的都是PO对象,而不是单独的一些属性,值,而是完整的对象,比如上面测试是否有二级缓存,就是将id为2的dept对象存入二级缓存中,而不是就存dept的name,或者是id,如果只存dept的name,或者别的字段属性,那么就会放入查询缓存中,而不是放入类缓存区域。
3.6.5.2、集合缓存区域
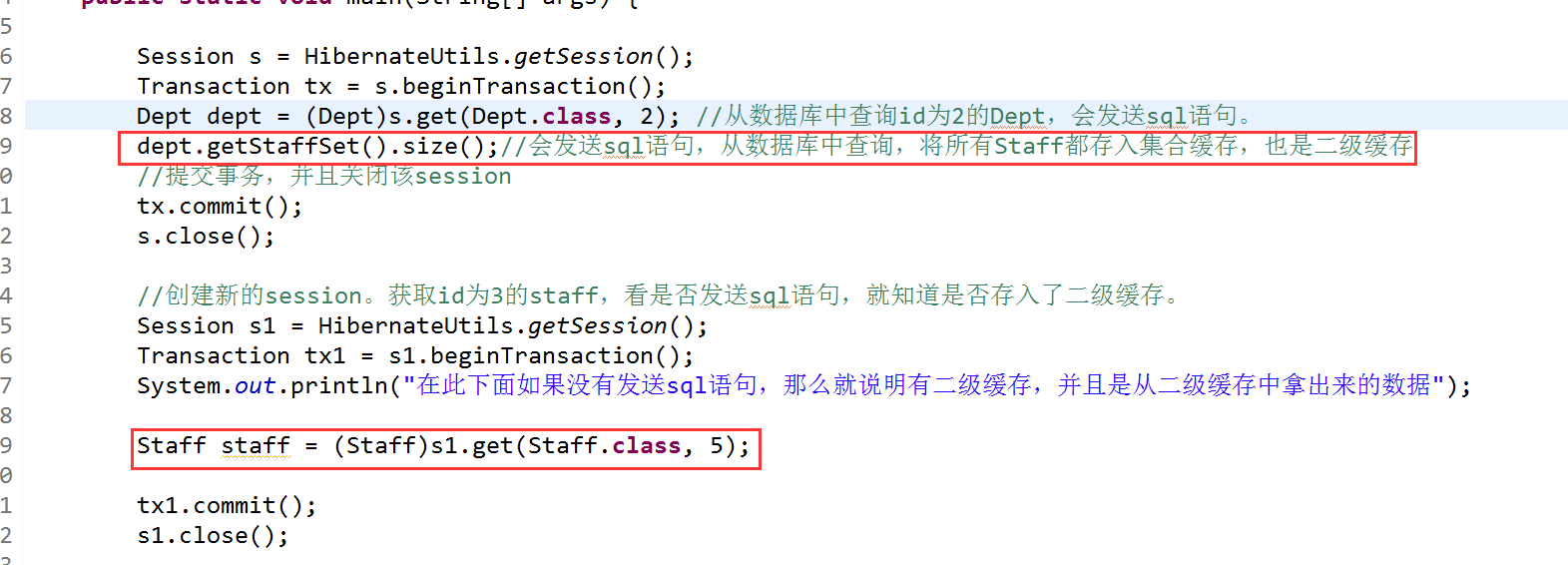
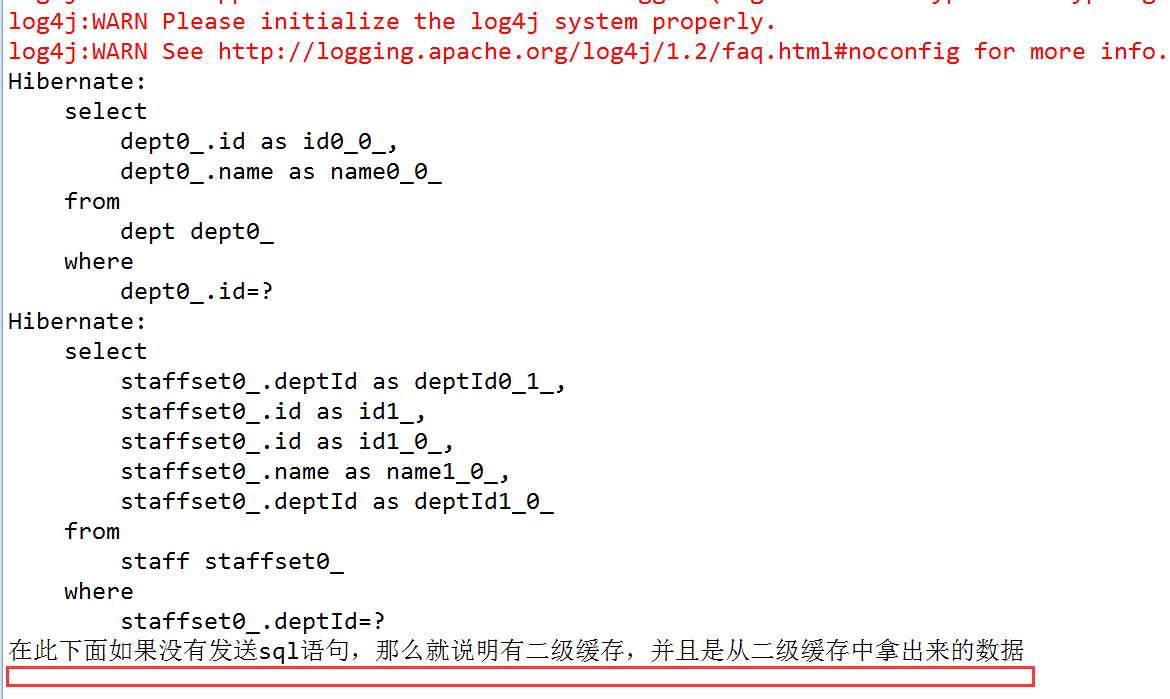
记得以前说的集合级联关系吗,其实这个也一样,比如这个Dept-Staff的例子中,dept.getStaffSet(); 这查询出来的就将其放入集合缓存区域,其区域内也全部是PO对象。
设置二级缓存的访问策略,由于要测试集合缓存,那么其set中就要设置访问策略,并且注意一点,集合级别的缓存依赖于类级别的缓存,也就是说,set中设置cache还不够,因为要缓存staff,所以必须将staff.hbm.xml也设置访问策略。同时我们只是测试集合缓存,那么对查询出来的Dept可以不设置访问策略了,有没有他读没关系,因为我们不需要用。也就是下图中第一个用红框框起来的,

staff.hbm.xml

测试从dept获取到的staff是否能够存入二级缓存中。
3.6.5.3、时间戳缓存区域
存放了对于查询结果相关的表进行插入,更新,删除操作的时间戳,Hibernate通过时间戳缓存区域来判断被缓存的查询结果是否过期,如果过期了则从数据库中拿数据,没过期则直接从缓存中拿数据。通俗点讲,就三步
1、查询结果放到二级缓存中,此时记录一个时间为T1
2、当有操作直接更改了数据库的数据时,比如使用hql语句,就会直接对数据库进行修改,而不会改变缓存中的数据。此时记录时间为T2
3、当下次在查询记录时,会先将T1和T2进行比较,如果T2>T1,则说明缓存中的数据不是最新的,那么就从数据库中拿出正确的数据,如果T2<T1,就说明没有对数据库进行过什么修改操作,那么就可以直接从缓存中获取数据。
解惑:如果没有T1和T2的比较,那么会出现我们查询到的数据不是准确的,因为就像上面第二步所说的,数据库的数据会和缓存中的数据不一样,什么读不做就从缓存中拿数据,就会出现错误。
测试:
3.6.5.4、查询缓存区域
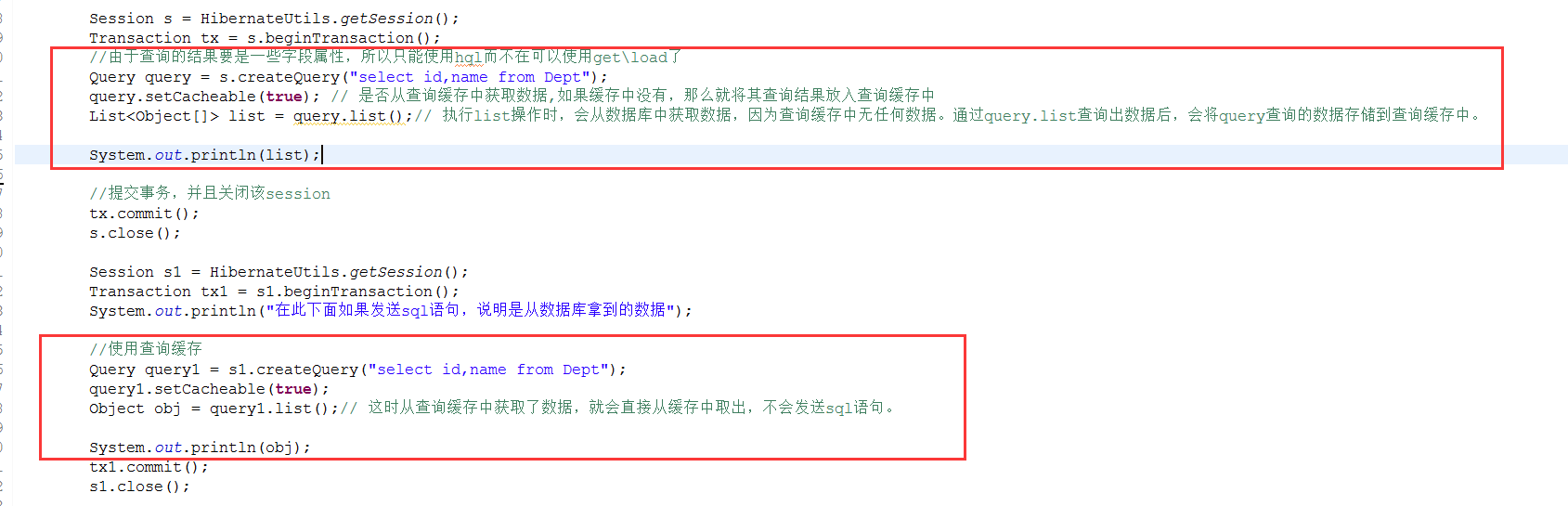
这个在将类缓存区域差不多已经解释过了,就是通过查询的结果不是一个po对象,而是一些零散的字段属性,那么就存入该区域,但是使用它是需要两个东西
1、在hibernate.cfg.xml文件中配置

2、在使用query操作时,需要指定是否从查询缓存中获取数据

测试:

以上写的访问策略全是使用的xxx.hbm.xml来配置,现在我将上面例子的使用hibernate.cfg.xml来配置访问策略的代码写一下。

上图说了两个缓存区域,时间戳缓存区域不用设置,而查询缓存区域就通过别的方式去设置了。 这就是我们所要讲解的四个缓存区域。很简单把。
四、总结
这篇文章本该早写完的,但是中途因为一些事情而耽误了,今天上午终于将它完结了。hiberante我觉得差不多就这些东西了。 希望对大家有所帮助