
语句与表达式
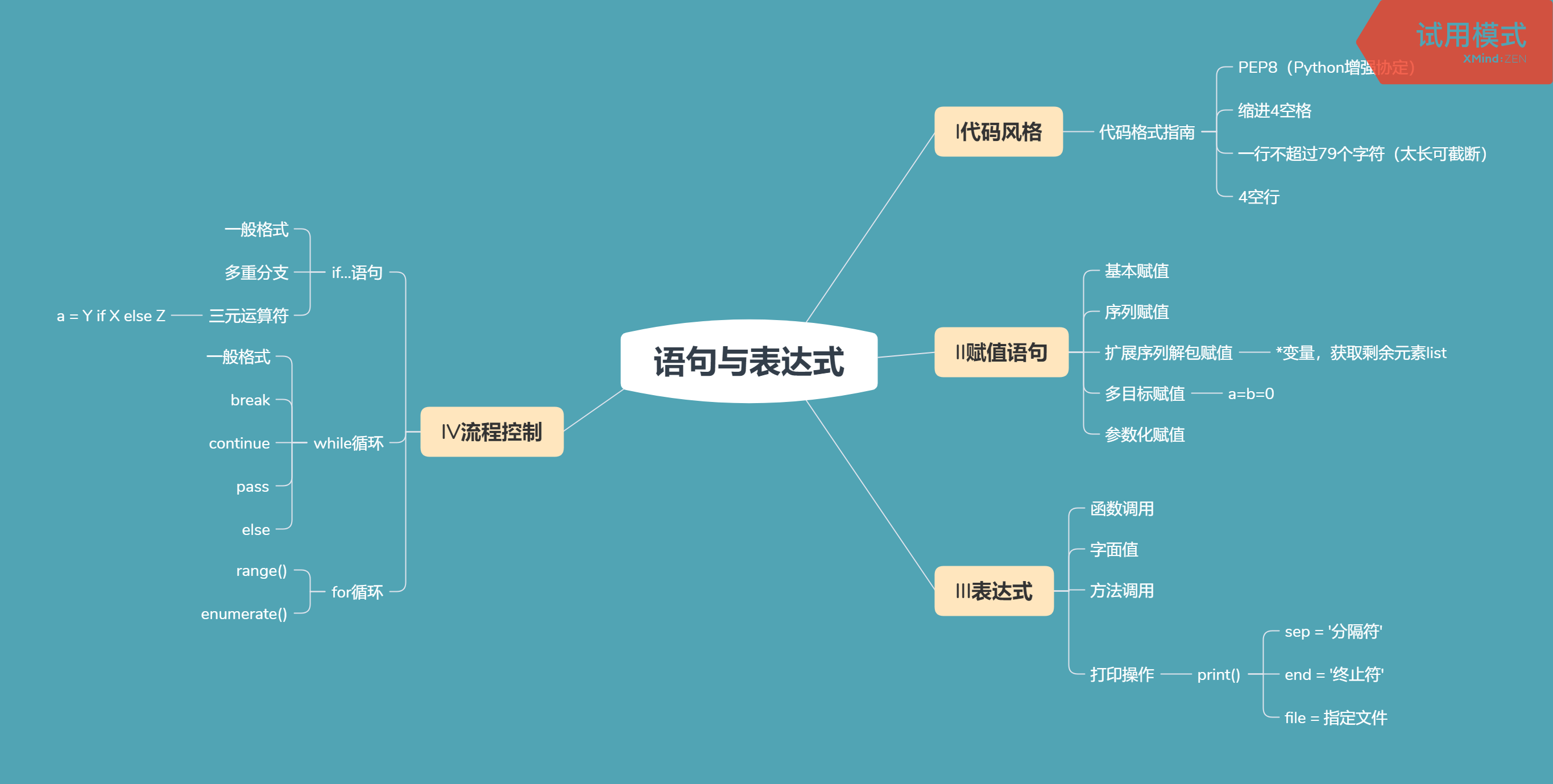
I 代码风格:缩进,空四格
if 5 > 0: print('ok')
II赋值语句:
1基本赋值
In[2]: x = 5 In[3]: (x,y) = (5,10) #元组赋值,5放x,10放y In[4]: x Out[4]: 5 In[5]: y Out[5]: 10 In[6]: x,y = 5,10 #同上 In[7]: x,y Out[7]: (5, 10) In[8]: result = x + 20 In[9]: result Out[9]: 25 In[10]: [x,y,z] = [10,20,30] In[11]: y Out[11]: 20 In[12]: z Out[12]: 30 In[13]: x,y = y,x In[14]: y Out[14]: 10 In[15]: x Out[15]: 20
2序列赋值
In[16]: [a,b,c] = (1,2,3) #列表,赋值放入元组 In[17]: a Out[17]: 1 In[18]: b Out[18]: 2 In[19]: a,b,c = 'uke' #字符串,3个变量,序列赋值对应前面元组,后面字符串 In[20]: a Out[20]: 'u' In[21]: b Out[21]: 'k' In[22]: c Out[22]: 'e' In[23]: a,b,c = 'youpin' #会发现异常 Traceback (most recent call last): File "D:Anaconda3libsite-packagesIPythoncoreinteractiveshell.py", line 3296, in run_code exec(code_obj, self.user_global_ns, self.user_ns) File "<ipython-input-23-54dcac7e48ec>", line 1, in <module> a,b,c = 'youpin' #会发现异常 ValueError: too many values to unpack (expected 3)
数量不一致时可以使用切割方法
n[24]: a,b,c = 'you' #y放a上,o放b上,c放u,其实是想c放所有upin进去 In[25]: s = 'youpin' #放入变量里 In[26]: a,b,c = s[0],s[1],s[2:] #s[2:]表示从第3个以后所有信息交给c In[27]: a Out[27]: 'y' In[28]: b Out[28]: 'o' In[29]: c Out[29]: 'upin'
3扩展序列解包赋值
In[32]: a,b,*c = s In[33]: a Out[33]: 'y' In[34]: b Out[34]: 'o' In[35]: c Out[35]: ['u', 'p', 'i', 'n'] #发现把c放入到一个序列里了 n[36]: a,*b,c=s #把中间的塞给b In[37]: a Out[37]: 'y' In[38]: b Out[38]: ['o', 'u', 'p', 'i'] In[39]: c Out[39]: 'n' In[40]: type(b) Out[40]: list In[41]: b = ''.join(b) #b形成字符串,join连起来列表 In[42]: b Out[42]: 'oupi'
In[44]: a,b,c,*d = 'uke' #可以对少的,不能对多的 In[45]: a Out[45]: 'u' In[46]: b Out[46]: 'k' In[47]: c Out[47]: 'e' In[48]: d #对不上就对个列表,不是对none Out[48]: []
In[49]: a,b,*c = 'uke' #列表装元素 In[50]: c Out[50]: ['e']
4多目标赋值
In[51]: a = 'uke' In[52]: b = 'uke' In[53]: a = = b File "<ipython-input-53-5ef276fc0ad3>", line 1 a = = b ^ SyntaxError: invalid syntax In[54]: a == b Out[54]: True In[55]: a is b #内存指向同一个对象吗 Out[55]: True In[56]: c = 'uke.cc' In[57]: d = 'uke.cc' In[58]: c == d Out[58]: True In[59]: c is d #内存引用不一致,长的不行 Out[59]: False In[60]: x = 'uke.' In[61]: y = 'uke.' In[62]: x is y Out[62]: False
In[2]: a = b = c = 'uke' In[3]: a Out[3]: 'uke' In[4]: b Out[4]: 'uke' In[5]: c Out[5]: 'uke' In[6]: a = 'uke' #同上,此方法啰嗦 In[7]: b = a In[8]: c = b In[9]: b Out[9]: 'uke' In[10]: c Out[10]: 'uke' In[11]: a = b = [] #内存有空列表 In[12]: a Out[12]: [] In[13]: b Out[13]: []

In[11]: a = b = [] #内存有空列表 In[12]: a Out[12]: [] In[13]: b Out[13]: [] In[14]: a.append(3) In[15]: a Out[15]: [3] In[16]: b #看b里有3吗 Out[16]: [3] In[17]: a = [] In[18]: b = [] In[19]: a.append(3) In[20]: a Out[20]: [3] In[21]: b Out[21]: []
In[22]: a,b = [],[] #分开赋值 In[23]: a.append(3) In[24]: b #不受影响 Out[24]: []
5参数化赋值
In[2]: x = 5 In[3]: y = 6 In[4]: x = x + y #把x+y 从新赋给x In[5]: x Out[5]: 11 In[6]: a,b = 1,2 In[8]: a += b #右侧只需计算一次 In[9]: a Out[9]: 3
III表达式
法1.函数调用
In[15]: len('abc') Out[15]: 3
法2.方法调用
Out[14]: [1, 2, 9, 10, 3, 5, 7] In[15]: len('abc') Out[15]: 3 In[16]: l.append(99) In[17]: l Out[17]: [1, 2, 9, 10, 3, 5, 7, 99]
法3.print
In[18]: print('hello') hello In[19]: s = '优品课堂' In[20]: url = 'www.codeclassroom.com' In[22]: print(s,url) #把值挨个打印,中间以空格分隔 优品课堂 www.codeclassroom.com
In[23]: url2 = 'www.uke.cc' In[25]: print(s,url,url2) 优品课堂 www.codeclassroom.com www.uke.cc
In[25]: print(s,url,url2) 优品课堂 www.codeclassroom.com www.uke.cc In[26]: print(s,url,url2,sep='#') #sep分割 优品课堂#www.codeclassroom.com#www.uke.cc
In[27]: print(s,url,url2,end='... ') 优品课堂 www.codeclassroom.com www.uke.cc...
print(s,url,url2,end='... ',file=open('result.txt','w')) #当前目录创造一个result的txt文件,w是表明往里写内容
IV流程控制
1、if语句
score = 75 if score >= 60: print('及格') else: print('不及格')
score = 95 if score >= 90: print('优秀') elif score >= 80: print('良') elif score >= 60: print('及格') else: print('不及格')
多重分支
def add(x): #定义函数接收参数x print(x+10) operation = { 'add':add, #添加操作,不加括号传递引用 'update': lambda x:print(x*2), #更新操作,打印x*2 'delete': lambda x:print(x*3) #删除操作 } def defalut_method(x): print('默认方法,啥都不做') #添加操作 operation.get('add')(10) #传10进来
def add(x): #定义函数接收参数x print(x+10) operation = { 'add':add, #添加操作,不加括号传递引用 'update': lambda x:print(x*2), #更新操作,打印x*2 'delete': lambda x:print(x*3) #删除操作 } def defalut_method(x): print('默认方法,啥都不做') #添加操作 operation.get('update')(10) #传10进来
def add(x): #定义函数接收参数x print(x+10) operation = { 'add':add, #添加操作,不加括号传递引用 'update': lambda x:print(x*2), #更新操作,打印x*2 'delete': lambda x:print(x*3) #删除操作 } def defalut_method(x): print('默认方法,啥都不做') #添加操作 operation.get('delete')(10) #传10进来
如果写错delet 找不到键值可以加一项
def add(x): #定义函数接收参数x print(x+10) operation = { 'add':add, #添加操作,不加括号传递引用 'update': lambda x:print(x*2), #更新操作,打印x*2 'delete': lambda x:print(x*3) #删除操作 } def defalut_method(x): print('默认方法,啥都不做') #添加操作 operation.get('delte',defalut_method)(10) #找不到合适的键值执行method
score = 75 result = '及格' if score >= 60 else '不及格' print(result)
2、while语句(循环)(条件测试满足重复循环)
一般格式
x = 'youpinketang' while x: #x有对象的话 print(x,end=' ') #打印字符串 x = x[1:] #每打印一次,去掉一节,2以后的取出来代替原来字符串
a,b = 0,10 while a < b: print(a) a += 1
break(循环跳出)

while True: name = input('请输入您的姓名:') #全局函数,这个是字符串 if name == 'stop': break #跳出循环,从循环里面跳出 age = input('请输入您的年龄:')#字符串 print('您好:{},您的年龄是:{},欢迎学习'.format(name,age)) #{}占位符,format传入name print('循环结束')
while True: name = input('请输入您的姓名:') #全局函数,这个是字符串 if name == 'stop': break #跳出循环,从循环里面跳出 age = input('请输入您的年龄:')#字符串 print('您好:{},您的年龄是:{},欢迎学习'.format(name,age)) #{}占位符,format传入name else:#条件不满足,跳出上面整个循环,前提是上面不能执行break了,所以此循环把else忽略了。 print('循环结束')
pass占位符(想循环不确定放入啥用占位符)
def add(x,y) #定义一个函数,但是想不清里面放啥用占位符 pass
continue
x = 10 while x: x -= 1 if x %2 != 0: #不等于0证明是奇数,执行continue,等于0的打出来 continue print(x,end=' ')
x = 10 while x: x -= 1 print(x,end=' ')
3、for循环 :range支持迭代遍历
在循环里找信息做标记:前面声明变量,后面判断变量
别扭型:
found = False for x in range(1,5): #做个for循环,range产生一个数字范围,如1-5 if x == 6: found = True print('已经找到了',x) break if not found: print('没找到 ')
正常型:
for x in range(1,5): if x ==6: print('有这个数字',x) break else: print('未找到')
遍历:
for x in 目标序列: #先考虑在什么地方遍历找到放x里
for x in [1,2,3,4]: #先考虑在什么地方遍历找到放x里,列表放到循环里遍历 print(x, end='')
for x in ['uke.cc','youpinketang.com','codeclassroom.com']: #字符串也可以 print(x, end='')
做累加操作
sum = 0 for x in [1,2,3,4,5]: sum += x print(sum)
字典表
emp = { 'name':'Tom', 'department':'technolgy', 'job':'development', 'salary':9000.00 } #想打印他们的信息,用遍历的方式 for key in emp: #用key得到它的键,出来的字典表是乱序,哈希算法的缘故 print(key)
想列出后面的值
emp = { 'name':'Tom', 'department':'technolgy', 'job':'development', 'salary':9000.00 } #想打印他们的信息,用遍历的方式 for key in emp: #用key得到它的键,出来的字典表是乱序 print('{} => {}'.format(key, emp[key]))#前面显示键后面显示值,格式化字符串的占位符,这不是字典表了,emp是找key
如果有些找不到对不上,可以加个get
print('{} => {}'.format(key, emp.get(key,'未找到')))
字典表遍历时可只遍历键或值
emp = { 'name':'Tom', 'department':'technolgy', 'job':'development', 'salary':9000.00 } for value in emp.values(): print(value) #他们值不是列表,是视图 print(type(emp.values()))
找两个序列中重叠的部分
s1 = 'youpinketang.com' s2 = 'codeclassroom.com' result = []#声明列表 for x in s1: if x in s2: #是不是在第二个字符串能找到s1 result.append(x) print(result)
s1 = 'youpinketang.com' s2 = 'codeclassroom.com' l = [x for x in s1 if x in s2] #下返回列表list,先声明,找到第一个字符串里所有的字符放入l #只打印在第二里也存在的 print(l)
rage():函数生成一个序列,不是列表
for x in range(1,100):#生成1-100序列,不包括100 print(x)
隔一个打一个,加进个步长
for x in range(0,101,2):#生成1-100序列,不包括100,各两个打一个 print(x)
enumerate():函数,帮助获取目前帮助循环的第几项目
s = 'youpinketang' #打印索引 for (idx,item) in enumerate(s): #遍历,在每一个里面加个序列,调用函数包住s,idx获取索引,(idx,item)是个元组
print('{}){}'.format(idx + 1,item)) #加1符合阅读习惯