一、什么是NumPy
(一)工作环境的安装
使用的是Anaconda环境,它是一个集成的工作环境,方便管理各种包,这里提供一个版本的链接: https://pan.baidu.com/s/1pHqRTy_uwKMArtt8SvY6Tw 提取码: 3922 。在下载后按照指示进行安装即可。
注意安装完毕后需要进行环境变量的配置,在电脑的系统环境变量中进行配置,将Anaconda的安装路径以及scripts路径导入系统path中。
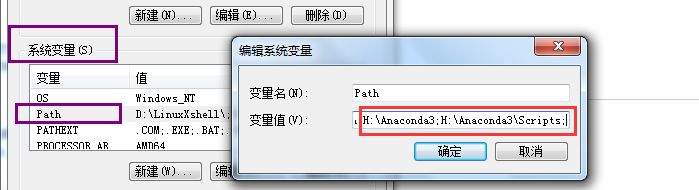
此时可以在左下角开始处打开Anaconda Prompt终端:
1、检查是否安装成功
(base) C:UsersAdministrator>conda --version
conda 4.5.4
2、管理虚拟环境
-
查看所有的虚拟环境
(base) C:UsersAdministrator>conda info --envs # conda environments: # base * H:Anaconda3 python35 H:Anaconda3envspython35
-
创建新的虚拟环境
(base) C:UsersAdministrator>conda create -n python37 python=3.7
-
切换环境
(base) C:UsersAdministrator>activate python35
(python35) C:UsersAdministrator>
-
安装包
(python35) C:UsersAdministrator>conda install requests ##或者 (python35) C:UsersAdministrator>pip install requests
-
卸载包
(python35) C:UsersAdministrator>conda remove requests ##或者 (python35) C:UsersAdministrator>pip uninstall requests
-
查看包的信息
(python35) C:UsersAdministrator>conda list
-
导入导出环境
#导出环境 (python35) C:UsersAdministrator>conda env export > environment.yaml #导入新的虚拟环境 (python34) C:UsersAdministrator>conda env create -f environment.yaml
-
卸载虚拟环境
(python35) C:UsersAdministrator>conda remove --name python34 --all
(二)什么是NumPy
NumPy是使用Python进行科学计算的基础软件包。是一个运行速度非常快的科学计算库,因为它的底层逻辑是使用C语言实现的,NumPy的功能非常多,其主要功能包括:
- 功能强大的N维数组对象。
- 精密广播功能函数。
- 集成 C/C+和Fortran 代码的工具。
- 强大的线性代数、傅立叶变换和随机数功能。
在使用NumPy之前需要先进行它的环境搭建,在虚拟环境中只需要安装对应的包即可:
(python35) C:UsersAdministrator>conda install numpy
安装完毕后进行测试:
(python35) C:UsersAdministrator>python Python 3.5.2 |Continuum Analytics, Inc.| (default, Jul 5 2016, 11:41:13) [MSC v .1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import numpy as np >>>
二、NumPy的使用
(一)数组对象
1、属性
NumPy 最重要的一个特点是其 N 维数组对象(矩阵) ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。其特点如下:
- 所有元素必须是相同类型
- ndim属性,维度个数
- shape属性,各维度大小
- dtype属性,数据类型
- axis属性,轴参数
- size属性,数组元素的个数
举例说明:
import numpy as np #随机生成3行4列的数据 data = np.random.rand(3,4) print(data) ###########输出########## [[0.77006414 0.40472558 0.07331437 0.55188175] [0.80664964 0.84844352 0.08464626 0.67016604] [0.14836505 0.82259737 0.45900147 0.60369758]]
上述生成的是一个3行4列的矩阵:
print('维度个数',data.ndim) #维度个数 2 print('各维度大小',data.shape) #各维度大小 (3, 4) print('数据类型',data.dtype) #数据类型 float64
需要着重强调一下axios参数,对于维度的转换或者,对某一个维度的操作都需要用到此参数:

>>> data = np.arange(10).reshape(2,5) >>> data array([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]) #在横轴方向进行操作 >>> data.sum(axis=1) array([10, 35]) #在纵轴方向进行操作 >>> data.sum(axis=0) array([ 5, 7, 9, 11, 13]) >>>
2、创建数组
-
np.zeros, np.ones,np.empty
指定大小的全0或全1数组,值得注意的是:
(1)第一个参数是元组,用来指定大小,如(4,5)
(2)empty不是总是返回全0,有时返回的是未初始的随机值
#创建一维数组 >>> import numpy as np >>> np.zeros(5,dtype=float) array([0., 0., 0., 0., 0.]) #创建浮点型全为0的数组 >>> np.zeros(5,dtype=int) array([0, 0, 0, 0, 0]) #创建整型全为0的数组 >>> np.ones(5) array([1., 1., 1., 1., 1.]) #创建值全为1的数组 #创建一个空数组,然后将空数组使用fill方法进行填充 >>> a = np.empty(4) >>> a array([7.33483560e-315, 7.33405037e-315, 2.49174182e-316, 2.07211804e-316]) >>> a.fill(6) >>> a array([6., 6., 6., 6.]) >>> #创建多维数组 >>> np.zeros((4,5)) array([[0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.]]) >>> np.ones((4,5)) array([[1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.]]) >>> np.empty((3,4)) array([[1.186e-321, 0.000e+000, 0.000e+000, 0.000e+000], [0.000e+000, 0.000e+000, 0.000e+000, 0.000e+000], [0.000e+000, 0.000e+000, 0.000e+000, 0.000e+000]]) >>> np.empty((3,4),int) #指定数据类型 array([[1484587258, 0, 1484587600, 0], [1484428320, 0, 13996488, 0], [ 7077996, 4784128, 84, 5006336]])
-
np.random 创建随机数的数组
np.random模块半酣许多可用于创建随机数组的函数,例如生成一个服从标准正态分布(均值为0、方差为1)的随机样本数组:
#一维数组 >>> np.random.randn(5) array([ 0.80726684, -0.47856828, -1.01387413, -1.81198436, -0.30367494]) #多维数组 >>> np.random.randn(5,4) array([[ 0.44795214, 0.58889219, 0.6557998 , -0.98750982], [ 0.96874065, -0.83364282, 0.40935755, 0.17958365], [-0.3830435 , -0.13996465, 0.65810287, -1.09443092], [-1.67776307, 0.00275889, -1.32662109, 1.25585212], [-0.66629589, -1.09667777, 1.08017396, 1.04579035]])
其它用法:
(1)numpy.random.rand(d0, d1, ..., dn)
生成一个(d0, d1, ..., dn)维的数组,数组的元素取自[0, 1)上的均分布,若没有参数输入,则生成一个数
#一个数 >>> np.random.rand() 0.5602091565863412 #多维数组 >>> np.random.rand(2,3) array([[0.21425158, 0.55603564, 0.71230788], [0.91407327, 0.12856442, 0.31680005]]) >>> np.random.rand(2,2,3) array([[[0.66192283, 0.06463257, 0.49716463], [0.90722766, 0.02891533, 0.97793578]], [[0.30110233, 0.61075461, 0.85996915], [0.62196878, 0.82921807, 0.12312781]]])
(2)numpy.random.randint(low, high=None, size=None, dtype='I')
生成size个整数,取值区间为[low, high),若没有输入参数high则取值区间为[0, low)
>>> np.random.randint(6) 4 >>> np.random.randint(6,size=2) array([1, 5]) >>> np.random.randint(6,size=2,dtype='int64') array([5, 0], dtype=int64)
(3)numpy.random.random(size=None)
产生[0.0, 1.0)之间的浮点数
>>> np.random.random() 0.45467454915616023 >>> >>> np.random.random(6) array([0.30329601, 0.59093303, 0.37975647, 0.23568354, 0.01647539, 0.46731369]) >>> np.random.random((6,3)) array([[8.65067985e-01, 6.32889091e-02, 8.97145125e-01], [2.41960732e-01, 7.63990918e-01, 3.28925883e-01], [7.77391602e-01, 2.94343398e-01, 2.47273732e-02], [6.80504494e-01, 7.56751159e-01, 4.94071081e-04], [5.18076628e-01, 1.17604372e-01, 3.18197217e-01], [5.13292960e-01, 5.19054712e-01, 6.87742571e-01]])
-
np.arange
#创建一维数组 >>> np.arange(10) array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) #创建多维数组 >>> np.arange(10).reshape(2,5) array([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]])
-
np.array
np.array(collection),collection为序列型对象(list),嵌套序列(list of list)
#创建一维数组 >>> np.array([1,2,3]) array([1, 2, 3]) >>> np.array(np.arange(1,4)) array([1, 2, 3]) #创建一个二维数组 >>> np.array([[1,2,3],[4,5,6]]) array([[1, 2, 3], [4, 5, 6]]) >>> np.array([np.arange(1,4),np.arange(4,7)]) array([[1, 2, 3], [4, 5, 6]]) #创建多维混合类型数组 >>> np.array([['a','b',1],[1,2,3]]) array([['a', 'b', '1'], ['1', '2', '3']], dtype='<U1')
3、数据类型
常用 NumPy 基本类型:
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
数组类型使用dtype属性查看:
dtype,:类型名+位数,如float64、int32
>>> a = np.array([1,2,3]) >>> a.dtype dtype('int32')
使用astype可转换数据类型:
>>> a = np.array([1,2,3]) >>> a.dtype dtype('int32') >>> b = a.astype(np.float64) >>> b array([1., 2., 3.]) >>> b.dtype dtype('float64')
4、索引和切片
-
一维数组的索引和切片
一维数组的索引与Python的列表索引功能相似
>>> arr1 = np.array(np.arange(5)) >>> arr1 array([0, 1, 2, 3, 4]) >>> arr1[0] 0 >>> arr1[0:] array([0, 1, 2, 3, 4]) >>> arr1[0:2] array([0, 1]) >>> arr1[2:-1] array([2, 3])
-
多维数组的索引与切片
使用多维数组,仍然可以像一维数组一样使用切片,并且多维数组可以在不同的维度中混合匹配切片和耽搁索引。
以下面多维数组为例:
>>> arr2 = np.array([np.arange(1,4),np.arange(4,7),np.arange(7,10)]) >>> arr2 array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
其中每个元素所处位置:
| 0,0 | 0,1 | 0,2 |
| 1,0 | 1,1 | 1,2 |
| 2,0 | 2,1 | 2,2 |
索引切片规则:
- arr[r1:r2, c1:c2]
- arr[1,1] 等价 arr[1][1]
- [:] 代表某个维度的数据
#取一个范围的数据 >>> arr2[1:3,1:3] array([[5, 6], [8, 9]]) #取某一个值 >>> arr2[1,1] 5 >>> arr2[1][1] 5 >>> #取某一个维度的值 >>> arr2[:] array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) >>> arr2[1:] array([[4, 5, 6], [7, 8, 9]]) >>> arr2[:,1] array([2, 5, 8]) >>>
另外在多维数组中还有条件索引,一般用于筛选多维数组:
#条件索引 # 找出 data_arr 中年龄大于等于5的数据 >>> data_array = np.random.rand(3,3) >>> data_array array([[0.41418315, 0.12959096, 0.53636403], [0.23272318, 0.4801341 , 0.64412843], [0.05275439, 0.01490136, 0.52569593]]) #过滤条件 >>> age_array = np.arange(1,10).reshape(3,3) >>> age_array array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) #过滤得到的数据 >>> filter_array = data_array[age_array >= 5] >>> filter_array array([0.4801341 , 0.64412843, 0.05275439, 0.01490136, 0.52569593]) #多个过滤条件要使用 & | >>> filter_array = data_array[(age_array >= 5) & (age_array %2 == 0)] >>> filter_array array([0.64412843, 0.01490136])
5、数组的运算
数组的运算是将相同大小的数组间的运算应用在元素上,注意这与线性代数中矢量运算是不同的。
##矢量与矢量的运算 >>> arr1 = np.arange(10).reshape(2,5) >>> arr1 array([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]) >>> arr2 = np.arange(10,20).reshape(2,5) >>> arr2 array([[10, 11, 12, 13, 14], [15, 16, 17, 18, 19]]) #数组相加 >>> arr1+arr2 array([[10, 12, 14, 16, 18], [20, 22, 24, 26, 28]]) >> #数组相乘 >>> arr1*arr2 array([[ 0, 11, 24, 39, 56], [ 75, 96, 119, 144, 171]]) >>> ##矢量与标量的运算 >>> 1/arr2 array([[0.1 , 0.09090909, 0.08333333, 0.07692308, 0.07142857], [0.06666667, 0.0625 , 0.05882353, 0.05555556, 0.05263158]]) >>> 2*arr2 array([[20, 22, 24, 26, 28], [30, 32, 34, 36, 38]]) >>>
数组间的运算包含矢量与矢量、矢量与标量,其运算的规则就是:
- 矢量运算,相同大小的数组键间的运算应用在元素上
- 矢量和标量运算,“广播”— 将标量“广播”到各个元素
(二)常用函数
1、元素级函数
- ceil, 向上最接近的整数
- floor, 向下最接近的整数
- rint, 四舍五入
- isnan, 判断元素是否为 NaN(Not a Number)
- multiply,元素相乘
- divide, 元素相除
>>> arr = np.random.randn(2,3) >>> arr array([[ 0.13900355, 1.0035698 , -1.18212763], [ 0.61880961, 0.55586212, 0.56438219]]) #向上最接近的整数 >>> np.ceil(arr) array([[ 1., 2., -1.], [ 1., 1., 1.]]) #向下最接近的整数 >>> np.floor(arr) array([[ 0., 1., -2.], [ 0., 0., 0.]]) #四舍五入 >>> np.rint(arr) array([[ 0., 1., -1.], [ 1., 1., 1.]]) #判断元素是否为 NaN(Not a Number) >>> np.isnan(arr) array([[False, False, False], [False, False, False]]) >>> #数组相乘 >>> arr1 = np.random.randn(2,3) >>> arr1 array([[-0.04220886, 0.86937388, -2.46986511], [ 1.33986535, -0.70081799, 0.571598 ]]) >>> arr2 = np.multiply(arr,arr1) >>> arr2 array([[-0.00586718, 0.87247737, 2.91969579], [ 0.82912156, -0.38955817, 0.32259973]]) #数组相除 >>> arr3 = np.divide(arr,arr1) >>> arr3 array([[-3.29323126, 1.15435928, 0.47862032], [ 0.46184462, -0.79316188, 0.98737608]]) >>>
2、统计函数
- np.mean(x [, axis]): 所有元素的平均值,参数是 number 或 ndarray
- np.sum(x [, axis]): 所有元素的和,参数是 number 或 ndarray
- np.max(x [, axis]): 所有元素的最大值,参数是 number 或 ndarray
- np.min(x [, axis]): 所有元素的最小值,参数是 number 或 ndarray
- np.std(x [, axis]): 所有元素的标准差,参数是 number 或 ndarray
- np.var(x [, axis]): 所有元素的方差,参数是 number 或 ndarray
- np.argmax(x [, axis]): 最大值的下标索引值,参数是 number 或 ndarray
- np.argmin(x [, axis]): 最小值的下标索引值,参数是 number 或 ndarray
- np.cumsum(x [, axis]): 返回一个同纬度数组,每个元素都是之前所有元素的 累加和,参数是 number 或 ndarray
- np.cumprod(x [, axis]): 返回一个同纬度数组,每个元素都是之前所有元素的 累乘积,参数是 number 或 ndarray
注意多维的数组要指定统计的维度,否则默认是全部维度上统计。
>>> arr = np.arange(12).reshape(4,3) >>> arr array([[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8], [ 9, 10, 11]]) >>> np.sum(arr) 66 >>> np.sum(arr,axis=1) array([ 3, 12, 21, 30]) >>>
3、条件函数
- all(iterables):如果可迭代对象iterables中所有元素为True则返回True。
- any(iterables):如果可迭代对象iterables中任意存在每一个元素为True则返回True。
- unique(iterables):从可迭代对象iterables中找到唯一值(去重)并返回排序结果
>>> arr =np.array([[1,2],[2,4]]) >>> arr array([[1, 2], [2, 4]]) >>> np.all(arr) True >>> np.any(arr) True >>> np.unique(arr) array([1, 2, 4]) >>>
4、文件存储函数
当进行数组操作后需要将数组的内容进行保存,此时需要用到文件存储的函数。
- savetxt
- loadtxt
import numpy as np array = np.arange(20) #将数组array以整数形式保存到a.txt文件中 np.savetxt("a.txt",array,fmt='%d') #将数组array以浮点数形式保存到b.txt文件中 np.savetxt("b.txt",array,fmt='%.2f') #从a.txt文件中以整数形式读取文本数据,并返回NumPy数组 array1 = np.loadtxt("a.txt",dtype='int') print(array1) #从b.txt文件中以浮点数形式读取文本数据,并返回NumPy数组 array2 = np.loadtxt("b.txt",dtype='float') print(array2)
savetxt和loadtxt函数也是可以读写CSV文件,CSV文件是用分隔符分隔的文本文件,通常的分隔符包括空格、逗号、分号等;通过loadtxt函数可以读取CSV文件,通过savetxt函数可以将数组保存为CSV文件。
savetxt和loadtxt函数默认都是使用空白符(空格、制表符等)作为分隔符,但可以通过delimiter关键字参数指定分隔符,还可以通过usecols关键字参数将读取的数据拆分成多列返回,列索引从0开始。
import numpy as np array = np.arange(12).reshape(3,4) print(array) #将二维数组保存到c.txt文件中,并用逗号分隔 np.savetxt("c.txt",array,fmt="%d",delimiter=',') #从c.txt文件以整数类型读取文本,并且获取第1,3列的数据 array3 = np.loadtxt("c.txt",dtype=int,delimiter=",",usecols=(0,2)) print(array3) #将上述获取的第1,3列数据赋值给x,y变量,必须将unpack=True x,y = np.loadtxt("c.txt",dtype=int,delimiter=",",usecols=(0,2),unpack=True) print(x,y)
参考: