构建项目步骤
-
首先要安装好scala、sbt、spark,并且要知道对应的版本
- sbt版本可以在sbt命令行中使用
sbtVersion查看 spark-shell可以知晓机器上spark以及对应的scala的版本
- sbt版本可以在sbt命令行中使用
-
IDEA中plugin安装scala插件
- pass
-
修改配置文件改变IDEA下sbt依赖下载速度慢的问题
参考官网:
 
具体做法:
vi ~/.sbt/repositories <---加入---> [repositories] local oschina: http://maven.aliyun.com/nexus/content/groups/public/ jcenter: http://jcenter.bintray.com/ typesafe-ivy-releases: http://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly maven-central: http://repo1.maven.org/maven2/ <---结束--->并在IDEA中找到sbt下的VM parameters,往其中加入:
-Xmx2048M -XX:MaxPermSize=512m -XX:ReservedCodeCacheSize=256m -Dsbt.log.format=true -Dsbt.global.base=/Users/shayue/.sbt (这里应该替换成.sbt所在地址,下同) -Dsbt.boot.directory=/Users/shayue/.sbt/boot/ -Dsbt.ivy.home=/Users/shayue/.ivy2 (这里应该替换成.ivy2所在地址,下同) -Dsbt.override.build.repos=true -Dsbt.repository.config=/Users/shayue/.sbt/repositories其中倒数第二句是Jetbrain给出的官方做法,参考https://www.scala-sbt.org/1.0/docs/Command-Line-Reference.html#Command+Line+Options 的最后一行
-
通过sbt构建scala项目,选对版本
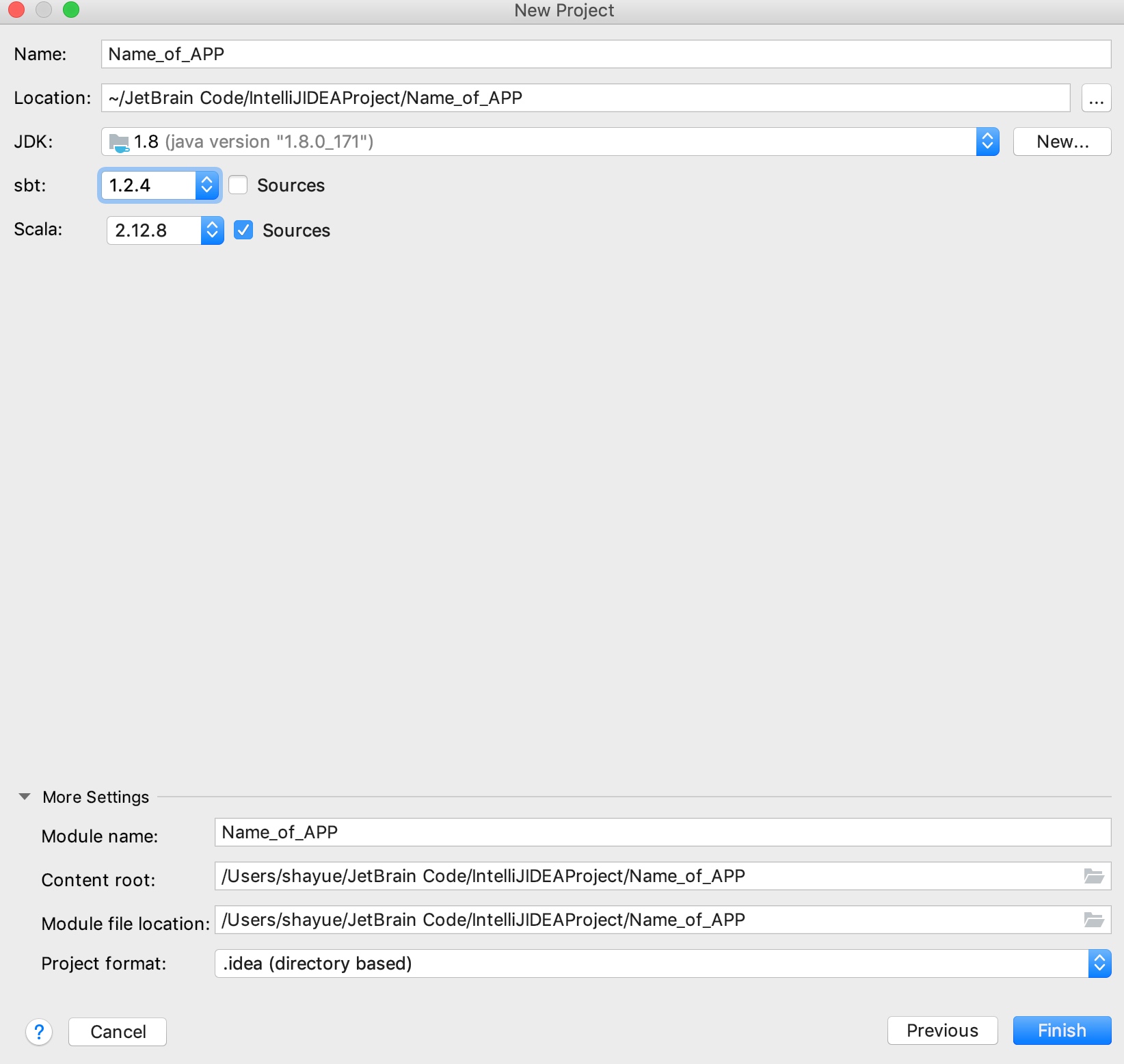 
 -
修改build.sbt和build.properties,在其中加入适合的版本,并引入Spark依赖
# build.sbt name := "Name_of_APP" version := "0.1" scalaVersion := "2.12.8" libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.2" libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.2" # build.properties sbt.version = 1.2.4其中spark的依赖可以通过spark下载页面找到,或者参考http://spark.apache.org/docs/latest/rdd-programming-guide.html 中的Link with Spark
代码
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.log4j.{Level,Logger}
object ScalaApp {
def main(args: Array[String]) {
//屏蔽启动spark等日志
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
// 设置数据路径
val path = "/Users/shayue/Sample_Code/Machine-Learning-with-Spark/Chapter01/scala-spark-app/data/UserPurchaseHistory.csv"
// 初始化SparkContext
val sc = new SparkContext("local[2]", "First Spark App")
// 将 CSV 格式的原始数据转化为(user,product,price)格式的记录集
val data = sc.textFile(path)
.map(line => line.split(","))
.map(purchaseRecord => (purchaseRecord(0), purchaseRecord(1), purchaseRecord(2)))
// 求购买总次数
val numPurchases = data.count()
// 求有多少个不同用户购买过商品
val uniqueUsers = data.map{ case (user, product, price) => user }.distinct().count()
// 求和得出总收入
val totalRevenue = data.map{ case (user, product, price) => price.toDouble }.sum()
// 求最畅销的产品是什么
val productsByPopularity = data
.map{ case (user, product, price) => (product, 1) }
.reduceByKey(_ + _ ).collect()
.sortBy(-_._2)
val mostPopular = productsByPopularity(0)
// 打印
println("Total purchases: " + numPurchases)
println("Unique users: " + uniqueUsers)
println("Total revenue: " + totalRevenue)
println("Most popular product: %s with %d purchases" .format(mostPopular._1, mostPopular._2))
}
}
输出:
Total purchases: 5
Unique users: 4
Total revenue: 39.91
Most popular product: iPhone Cover with 2 purchases
参考
- 第一张VM parameter修改参考https://blog.csdn.net/jameshadoop/article/details/522957109153012.html
- 代码来自《Spark机器学习》第二版