面向对象设计与构造2019 第一单元总结博客作业
一、度量分析程序结构
1.数据度量分析
在这里,以第三次作业为例。前两次作业的架构较为简单,分析价值较低。
| Type Name | NOF | NOPF | NOM | NOPM | LOC | WMC | NC | DIT | LCOM | FANIN | FANOUT |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BasicFactor | 0 | 0 | 4 | 4 | 41 | 11 | 0 | 1 | -1 | 0 | 1 |
| Expression | 1 | 0 | 11 | 11 | 124 | 31 | 0 | 0 | 0 | 4 | 3 |
| Factor | 3 | 0 | 9 | 9 | 108 | 27 | 1 | 0 | 0 | 2 | 2 |
| Main | 6 | 0 | 5 | 2 | 184 | 32 | 0 | 0 | 0 | 1 | 2 |
| Term | 1 | 0 | 13 | 13 | 206 | 49 | 0 | 0 | 0 | 4 | 3 |
可以看到,我的程序中,类很少,也只用了一个简单的继承。相对的,每个类的代码量较大,最大的类Term,代码长度甚至到达了206行。每个类中的方法数也相对较少,导致每个方法的代码长度也较长。说明程序在处理复杂问题的时候,依然依赖于面向过程的设计思路。
在内聚和耦合程度方面,程序没有太大问题,但是,如此少的类能够达到这种内聚耦合指标,是因为我采用了循环依赖结构。这种结构对于OO设计来说是非常不好的。但是,由于本次多项式求导需要用到递归思路,所以我这样写了。在下次作业中,我会尽量避免这种调用方式。
2.UML类图分析
在这里,贴上我三次作业的UML类图。
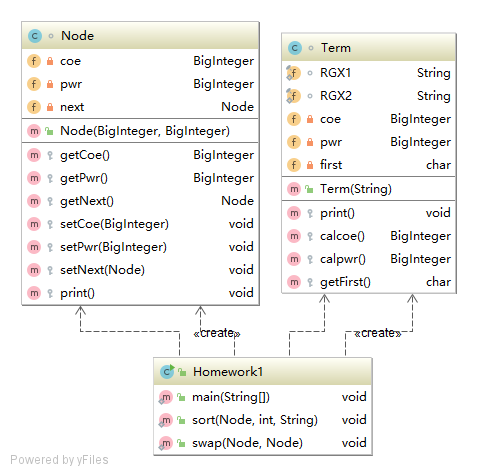
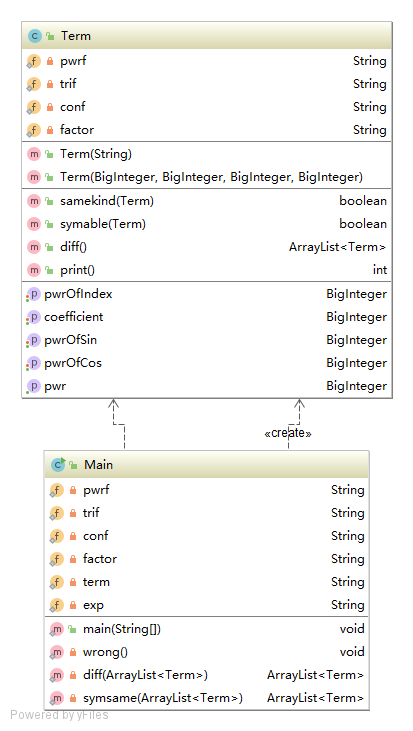
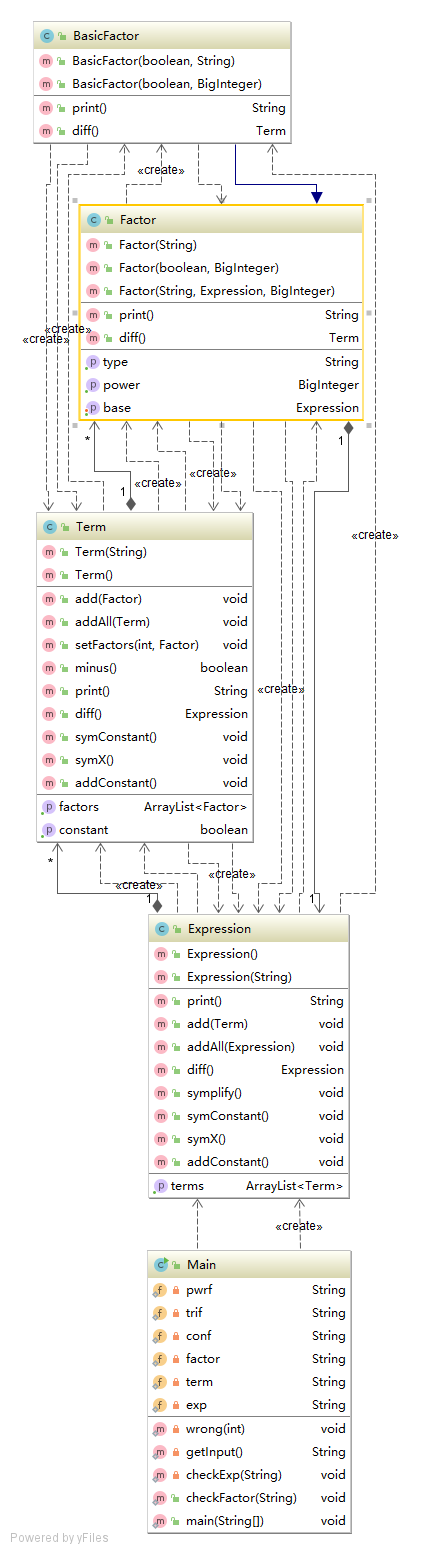
可以看到,三次作业中,我的设计一次比一次偏向线性化,而且类和方法的数量偏少。总的来说,还是没有跳出面向过程的设计思路。可以说,这个程序使用面向过程的涉及来写,并不需改动太多的东西。我在使用Java语言的过程中,没能很好地发挥语言的特点和长处,在面对困难问题的时候,首先采用的是我最熟悉的处理思路。
希望我能够在接下来的学习过程中,将自己程序中存在的问题逐一改正,写出优秀OO风格的程序。
二、程序BUG分析
三次作业的强测,正确性评分我都是满分。第一次作业中,互测bug被人检测出来,问题也出在正则表达式上。
总的来说,程序在读入正确数据后,分割、求导、输出的整个过程中,没有出现bug,但是这只是上交的公测最终版本的情况。在截止日期之前,从初版程序到最终版程序,中间bug出现了很多很多次,而我在处理这些bug的时候,有时也会采用特判法。造成这种后果的原因在于,我在最开始设计程序的时候,少考虑了很多东西,导致在程序模块全部搭建完成的时候出现问题,没有简单的办法去解决。
我认为,自己程序的模块化依然不够。程序的类与类之间耦合度偏高,导致出现bug后,修复常常会改掉多个类。这种现象的一个原因,可能是我在设计程序的时候是从顶层向下编写代码,导致许多问题没有丢给模块解决。下次我会尝试从底层开始向上构建程序。
三、发现别人bug的策略
我采用的测试方法,是使用黑箱测试的方法,编写数据自动生成器和对拍器,来对别人的程序进行检测。这种方法在数量上取得优势,也降低了我的思考难度。
贴一段bat代码:
@echo off
set /a count=1
:loop
echo -------
echo %count%
echo -------
set /a count+=1
echo generating...
python generate.py>data.in
echo -------
echo running...
java -cp saber Main<data.in>./result/saberx.out
java -cp archer Main<data.in>./result/archerx.out
java -cp lancer Main<data.in>./result/lancerx.out
java -cp rider Main<data.in>./result/riderx.out
java -cp caster Polyomial<data.in>./result/casterx.out
java -cp assassin MainInput<data.in>./result/assassinx.out
java -cp berserker Poly<data.in>./result/berserkerx.out
echo -------
echo checking...
java Valuable<./result/saberx.out>./result/saberz.out
java Valuable<./result/archerx.out>./result/archerz.out
java Valuable<./result/lancerx.out>./result/lancerz.out
java Valuable<./result/riderx.out>./result/riderz.out
java Valuable<./result/casterx.out>./result/casterz.out
java Valuable<./result/assassinx.out>./result/assassinz.out
java Valuable<./result/berserkerx.out>./result/berserkerz.out
echo -------
echo calculating...
python test.py<./result/saberz.out>./result/saber.out
python test.py<./result/archerz.out>./result/archer.out
python test.py<./result/lancerz.out>./result/lancer.out
python test.py<./result/riderz.out>./result/rider.out
python test.py<./result/casterz.out>./result/caster.out
python test.py<./result/assassinz.out>./result/assassin.out
python test.py<./result/berserkerz.out>./result/berserker.out
echo -------
echo comparing...
python compare.py
TIMEOUT /T 1
goto loop
无论是测试自己的程序还是别人的程序,我都采用了生成→运行→合法性检验→对拍的计算过程。这样做的优点,是可以用时间堆积去精准寻找程序中的bug。但是缺点是,这样会让我懈怠思考,不去思考程序中可能存在的bug,在将来遇到无法用自动评测去检测的程序时,我会无从下手。
从下次作业开始,我会尝试着去自己构造数据集来寻找别人的bug,以求开拓自己的思维。
四、设计模式重构思路
我认为,在自己编写这三次作业的过程中,我的思路依然局限在面向过程之中,没能很好地发挥面向对象的特性。继承、多态、接口等功能没有被我很好地运用。我在编写程序的过程中,是先写main函数,然后写main类里的方法,最后再去写其他类,这种构造顺序像极了面向过程的思路。
如果我要重构自己的程序,我会选择从底层开始搭建模块,一层一层向上设计,使用工厂模式。或者,采用助教推荐的方式,编写顶层模块功能,并将一些方法内容留空,采用填空的方式去编写程序,本质上还是从底端开始构建。先写接口,然后写父类,再写子类,最后在main函数中补全。