题目:
提取一段文字中的关键字
思路:
- 先将一段文字分词处理(类似第三方库jieba分词);
- 我们可以发现分词结果里有许多的无用词语,这时候就要剔除形容词,动词等无用词;最后再提炼出来所需要的关键词;
- 这时候去网上找相关代码一大堆,而且提取到的关键词好像也达不到我的要求,还要再接着提炼;
- 到头来想想算了,还不如去调用第三方接口,免费省力还专业,它不香吗;
解决方法:
调用百度AI开放平台的接口,实现关键词的提取
准备工作:
打开百度AI开放平台,点击控制台,注册登录;
选择左菜单栏的自然语言处理;
创建应用,得到API Key和SecretKey

选择自己想要学习的接口:(这里选择文章标签)
在文档中查看如何获取url,以及返回的Json数据格式;
代码实现:
代码分析:

如上图官方文档所示,请求中需要有三个条件
①根据你的API Key和SecretKey得到正确的请求URL
#得到请求url def get_url(): url=0 #通过API Key和Secret Key获取access_token AccessToken_url='https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(APIKey,SecretKey) res = requests.get(AccessToken_url) json_data = json.loads(res.text) #print(json.dumps(json_data, indent=4, ensure_ascii=False)) if not json_data or 'access_token' not in json_data: print("获取AccessToken的json数据失败") else: accessToken=json_data['access_token'] #将得到的access_token加到请求url中 url='https://aip.baidubce.com/rpc/2.0/nlp/v1/keyword?charset=UTF-8&access_token={}'.format(accessToken) print(url) return url
②根据得到的url调用接口获取相关Json数据
#创建请求,获取数据 def get_tag(url,title,content): tag=''#存储得到的关键词 #创建Body请求 body={ "title": title, "content":content } body2 = json.dumps(body)#将字典形式的数据转化为字符串,否则报错 #创建Header请求 header={ 'content-type': 'application/json' } res = requests.post(url,headers=header,data=body2)# 推荐使用post json_data = json.loads(res.text) if not json_data or 'error_code' in json_data: #print(json.dumps(json_data, indent=4, ensure_ascii=False)) print("获取关键词的Json数据失败") else: #print(json.dumps(json_data, indent=4, ensure_ascii=False)) for item in json_data['items']: tag=tag+item['tag']+' ' tags=tag.strip()#去除前后空格 print(tags) return tags
完整代码:


#!/usr/bin/env python # -*- coding: utf-8 -*- # @File : tiqu.py # @Author: 田智凯 # @Date : 2020/3/13 # @Desc :调用百度接口实现关键词的提取 import json import requests APIKey='###' SecretKey='###' #创建请求url def get_url(): url=0 #通过API Key和Secret Key获取access_token AccessToken_url='https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(APIKey,SecretKey) res = requests.post(AccessToken_url)#推荐使用post json_data = json.loads(res.text) #print(json.dumps(json_data, indent=4, ensure_ascii=False)) if not json_data or 'access_token' not in json_data: print("获取AccessToken的json数据失败") else: accessToken=json_data['access_token'] #将得到的access_token加到请求url中 url='https://aip.baidubce.com/rpc/2.0/nlp/v1/keyword?charset=UTF-8&access_token={}'.format(accessToken) return url #创建请求,获取数据 def get_tag(url,title,content): tag=''#存储得到的关键词 #创建Body请求 body={ "title": title, "content":content } body2 = json.dumps(body)#将字典形式的数据转化为字符串,否则报错 #创建Header请求 header={ 'content-type': 'application/json' } res = requests.post(url,headers=header,data=body2)# 推荐使用post json_data = json.loads(res.text) if not json_data or 'error_code' in json_data: #print(json.dumps(json_data, indent=4, ensure_ascii=False)) print("获取关键词的Json数据失败") else: #print(json.dumps(json_data, indent=4, ensure_ascii=False)) for item in json_data['items']: tag=tag+item['tag']+' ' tags=tag.strip()#去除前后空格 print(tags) return tags if __name__ == '__main__': title='iphone手机出现“白苹果”原因及解决办法,用苹果手机的可以看下' content='如果下面的方法还是没有解决你的问题建议来我们门店看下成都市锦江区红星路三段99号银石广场24层01室。在通电的情况下掉进清水,这种情况一不需要拆机处理。尽快断电。用力甩干,但别把机器甩掉,主意要把屏幕内的水甩出来。如果屏幕残留有水滴,干后会有痕迹。^H3 放在台灯,射灯等轻微热源下让水分慢慢散去。' url=get_url() get_tag(url, title,content)
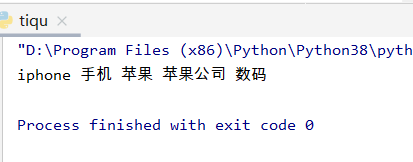
运行截图: