Hadoop 是 Apache 基金会下的一个开源分布式计算平台,以 HDFS 分布式文件系统 和 MapReduce 分布式计算框架为核心,为用户提供底层细节透明的分布式基础设施。目前,Hadoop 是分析海量数据的首选工具。Hadoop 是一个可以更容易开发和并行处理大规模数据的分布式计算平台,它的主要特点是扩展能力强、成本低、高效率和可靠。目前,Hadoop 的用户已经从传统的互联网公司,扩展到了各个行业,并且得到越来越广泛的应用。它的优势包括:
(1)方便:Hadoop 可以运行在商业机器集群上,或者Amazon EC2 等云计算服务商。
(2)弹性:Hadoop 可以方便增加和减少集群节点。
(3)健壮:Hadoop 可以从容处理常见的硬件失效情况。
(4)简单:Hadoop 允许用户快速高效编写并行分布代码。
0. 关于大数据
1. Hadoop:事实上的大数据标准

3. Hadoop 体系结构
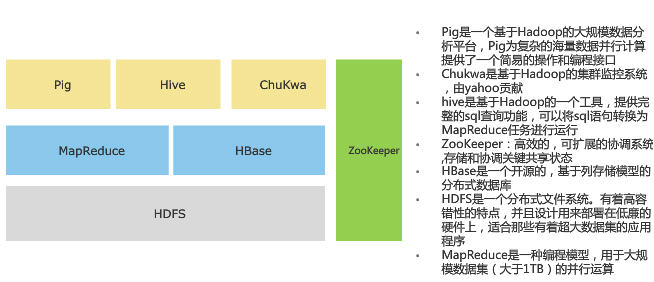
HBase是专门用於Hadoop档案系统上的资料库系统,采用Column-Oriented 资料库设计,不同於传统的关联式资料库,例如没有资料表、Schema资料架构等功能,而是採用Key-Value形式的资料架构,每笔资料都有一个Key值对应到一个Value值,再透过多维度的对应关係来建立类似表格效果的资料架构。如此就能採取分散式储存方式,可以扩充到数千臺服务器,以应付PB等级的资料处理。
Hive: 基于Hadoop的一个可用SQL语法存取Hadoop资料的工具。
Hive是建置在HDFS上的一套分散式资料仓储系统,可让使用者以惯用的SQL语法,来存取Hadoop档案中的大型资料集,例如可以使用Join、Group by、Order by等,而这个语法称为Hive QL。Hive 提供完整的 SQL 查询功能,可以将 SQL 语句转换为 MR 任务进行运行。不过,Hive QL和SQL并非完全相同,例如Hive就不支援Store Procedure、Trigger等功能。
Hive会将使用者输入的Hive QL指令编译成Java程序,再来存取HDFS档案系统上的资料,所以,执行效率依指令复杂度和处理的资料量而异,可能有数秒鐘,甚至是数分鐘的延迟。和HBase相比,Hive容易使用且弹性高,但执行速度较慢。不少资料库系统,都是透过先连结到Hive,才能与Hadoop整合。例如微软就是透过Hive ODBC驱动程序,将SQL指令转换成Hive QL,让Excel可以存取Hadoop上的资料。
在同一个Hadoop丛集中,Hive可以存取HBase上的资料,将HBase上的资料对应成Hive内的一个表格。
Pig:不懂Java开发也能写MapReduce
Pig 是一个机遇 Hadoop 的大规模分析平台,Pig 为复杂的海量数据并行计算提供一个简易的操作和编程接口。它提供了一个Script语言Pig Latin,语法简单,类似可读性高的高阶Basic语言,可用来撰写MapReduce程序。Pig会自动将这些脚本程序转换,成为能在Hadoop中执行的MapReduce Java程序。因此,使用者即使不懂Java也能撰写出MapReduce。不过,一般来说,透过Pig脚本程序转换,会比直接用Java撰写MapReduce的效能降低了25%。
ZooKeeper:让Hadoop内部服务器能协同运作
Zookeeper是一个高效的可扩展的资源协调系统,存储和协调关键共享状态。它监控和协调 Hadoop 分散式运作的集中式服务,可提供各个服务器的配置和运作状态资讯,用於提供不同Hadoop系统角色之间的工作协调。以HBase资料库为例,其中有两种服务器角色:Region服务器角色和Master服务器角色,系统会自动透过ZooKeeper监看Master服务器的状态,一旦Master的运作资讯消失,代表当机或网路断线,HBase就会选出另一台Region服务器成为Mater角色来负责管理工作。
Chukwa: Hadoop 的集群监控系统,由 Yahoo 贡献。
http://www.linuxidc.com/Linux/2014-03/98302.htm
Chukwa是一个开源的监控大型分布式系统的数据收集系统,它构建于HDFS和Map/Reduce框架之上,并继承了Hadoop优秀的扩展性和健壮性。在数据分析方面,Chukwa拥有一套灵活、强大的工具,可用于监控和分析结果来更好的利用所收集的数据结果。

.png)
2. Adaptors : 直接采集数据的接口和工具,一个 Agent 可以管理多个 Adaptor 的数据采集
3. Collectors :负责收集 Agent 收送来的数据,并定时写入集群中
1. 总体而言, chukwa 可以用于监控大规模(2000+ 以上的节点, 每天产生数据量在T级别) hadoop 集群的整体运行情况并对它们的日志进行分析
2. 对于集群的用户而言: chukwa 展示他们的作业已经运行了多久,占用了多少资源,还有多少资源可用,一个作业是为什么失败了,一个读写操作在哪个节点出了问题.
3. 对于集群的运维工程师而言: chukwa 展示了集群中的硬件错误,集群的性能变化,集群的资源瓶颈在哪里.
4. 对于集群的管理者而言: chukwa 展示了集群的资源消耗情况,集群的整体作业执行情况,可以用以辅助预算和集群资源协调.
5. 对于集群的开发者而言: chukwa 展示了集群中主要的性能瓶颈,经常出现的错误,从而可以着力重点解决重要问题.
4. Hadoop 版本演变
4.1 Hadoop 官方版本演变
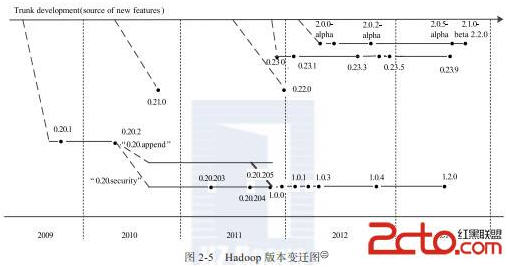
(2)0.21.0/0.22.x系列
这一系列版本将整个Hadoop项目被分割成三个独立的模块,分别是 Common、HDFS和MapReduce。HDFS和MapReduce都对Common模块有依赖,但是MapReduce对HDFS并没有依赖,这样,MapReduce可以更容易运行在其他的分布式文件系统之上,同时,模块间可以独立开发。具体各个模块的改进如下:
- Common模块:最大的新特性是在测试方面添加了Large-Scale Automated Test Framework 和 fault injection framework。
- HDFS模块:主要增加的新特性包括支持追加操作与建立符号连接、Secondary NameNode改进(secondary namenode被剔除,取而代之的是checkpoint node同时添加一个backup node的角色,作为NameNode的冷备)、允许用户自定义block放置算法等。
- MapReduce模块:在作业API方面,开始启动新MapReduce API,但仍然兼容老的API。
(3)0.23.X系列
0.23.X是为了克服 Hadoop 在扩展性和框架通用性方面的不足而提出来的,它包括基础库Common、分布式文件系统HDFS、资源管理框架 YARN 和运行在 YARN 上的MapReduce四部分,其中,新增的可对接入的各种计算框架(如MapReduce、Spark等)进行统一管理,该发行版自带 MapReduce 库,而该库集成了迄今为止所有的MapReduce新特性。最新的 0.23.11 在2014年6月发布。
(4)2.X系列
同0.23.x系统一样,2.X系列属于下一代Hadoop,与0.23.X相比,2.X增加了 NameNode HA 和 Wire-compatibility等新特性。最新的 2.6 版本在 2014年11月发布。

- Hadoop 1.0 由一个分布式文件系统 HDFS 和一个离线计算框架 MapReduce 组成
- Hadoop 2.0 由包含一个支持 NameNode 横向扩展的HDFS,一个资源管理系统 YARN 和一个运行在 YARN 上的离线计算框架 MapReduce。
董的博客有2篇文章也很清晰的解释了,hadoop版本以及各自的版本特性:
http://dongxicheng.org/mapreduce-nextgen/how-to-select-hadoop-versions/
http://dongxicheng.org/mapreduce-nextgen/hadoop-2-0-terms-explained/
4.2 Hadoop 2.0
http://dongxicheng.org/mapreduce-nextgen/hadoop-2-2-0/
Hadoop 2.0 的第一个稳定版本2.2.0于2013年10月15如发布了,这个版本是 继1.0.0版本后,又一个具有里程碑意义的版本,这意味着Hadoop进入2.0时代。Hadoop 2.0的最大变化出现在内核(HDFS、MapReduce和YARN),兼容1.x上运行的MapReduce应用程序。
特性1:引入一个新的资源管理系统YARN
YARN是“Yet Another Resource Negotiator”的简称,它是Hadoop 2.0引入的一个全新的通用资源管理系统,可在其之上运行各种应用程序和框架,比如MapReduce、Tez、Storm等,它的引入使得各种应用运行在一个集群中成为可能。YARN是在MRv1基础上衍化而来的,是MapReduce发展到一定程度的必然产物,它的出现使得Hadoop计算类应用进入平台化时代,该博客中包含大量介绍YARN的文章,有兴趣的读者可阅读:http://dongxicheng.org/category/mapreduce-nextgen/
特性2:HDFS单点故障得以解决
Hadoop 2.2.0同时解决了NameNode单点故障问题和内存受限问题,其中,单点故障是通过主备NameNode切换实现的,这是一种古老的解决服务单点故障的方案,主备NameNode之间通过一个共享存储同步元数据信息,因此共享存储系统的选择称为关键,而Hadoop则提供了NFS、QJM和Bookeeper三种可选的共享存储系统,具体可阅读这篇文章:Hadoop 2.0单点故障问题方案总结。
特性3:HDFS Federation
前面提到HDFS 的NameNode存在内存受限问题,该问题也在2.2.0版本中得到了解决。这是通过HDFS Federation实现的,它允许一个HDFS集群中存在多个NameNode,每个NameNode分管一部分目录,而不同NameNode之间彼此独立,共享所有DataNode的存储资源,注意,NameNode Federation中的每个NameNode仍存在单点问题,需为每个NameNode提供一个backup以解决单点故障问题。
5. Hadoop 衍化版
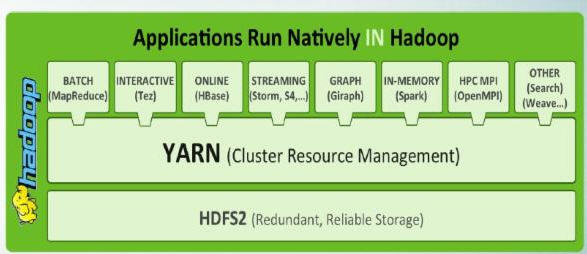
除了离线计算框架 MapReduce 外,还有从Hadoop衍生出的适合特定应用场景的别的框架:
(2)流式计算框架:Storm
(3)内存计算框架:Spark
(4)图计算框架:Giraph,Graphlib
6 Hadoop 商业发行版

- Cloudera: 2008 年成立的 Cloudera 是最早将 Hadoop 商用的公司,目前它是规模最大、知名度最高的Hadoop公司。Cloudera产品主要为CDH(Cloudera的Hadoop发行版),Cloudera Manager (集群的软件分发及管理监控平台),Cloudera Support。目前最新的 CDH 5.0除了包含Hadoop 2版本(MapReduce v2 over YARN)外,也可以让使用者启动并兼容MapReduce v1模式,但新旧模式并不能够同时执行于同一集群节点上。
- Hortonworks: 2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建的公司。Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,HDP除了常见的项目外还包含了Ambari,一款开源的安装和管理系统。HCatalog,一个元数据管理系统。
- MapR: 2009年成立的MapR公司在Hadoop领域显得有点特立独行,它提供了一款独特的发行版 。用新架构重写HDFS,同时在API级别,和目前的Hadoop 发行版保持兼容。
- EMC: EMC的Greenplum HD是基于mapR版本二次开发改造而成,特点同mapR。
- IBM:在2011/5月推出了InfoSphere BigInsights软件。该软件包括Apache Hadoop发行版、面向MapReduce编程的Pig编程语言、针对IBM的DB2数据库的连接件以及IBM BigSheets.IBM在平台管理,安全认证,作业调度算法,与DB2及netezza的集成上做了增强。
- Intel: 2014年3月英特尔放弃发行Hadoop版本,转而支持Cloudera,并成为Cloudera的最大战略股东以及成为Cloudera董事会的成员之一
各发行版的特点:

各发行版的介绍:http://www.cnblogs.com/sammyliu/articles/4395545.html
注:以上信息皆来自于互联网。