一、什么是消息中间件
1.概念
2.分类
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
- Redis
- ...
3.作用:为什么使用MQ?
-
-
同步变异步(漏斗作用,保证不堵塞)
-
-
应用解耦
-
提供基于数据的接口层
-
-
流量削峰(主要目的)
-
二、Kafka概念
2.1 概念
- [定义1]Kafka是一种高吞吐量的分布式发布-订阅消息系统,专为超高吞吐量的实时日志采集/实时数据同步/实时数据计算等场景设计
- [定义2]是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等
- 特性
- 高吞吐量、低延迟。单Broker每秒几百MB读取
- 每个topic可以分多个partition, consumer group 对partition进行consume操作。
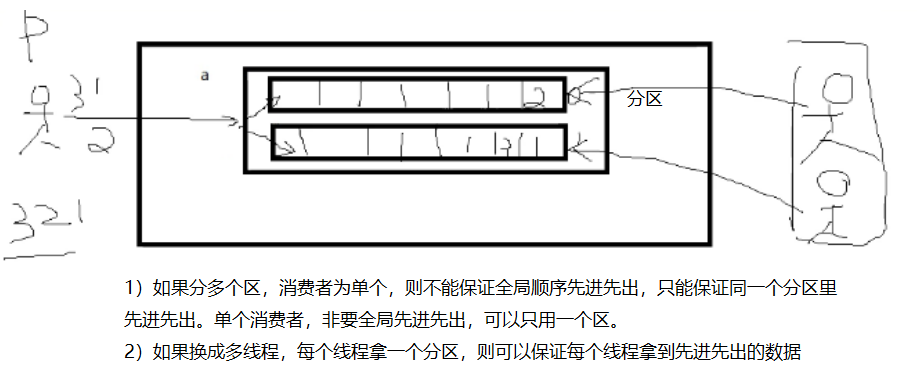
- .不停机拓展集群【热扩展】
- 消息副本冗余【容错性】
- 实时数据管道
- 消息被持久化到本地磁盘【可靠性】
- 支持数千个客户端同时读写【高并发】
- 高吞吐量、低延迟。单Broker每秒几百MB读取
- 使用Scala编写
2.2 使用场景
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统 一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:【埋点】Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka 的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载 到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的 数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
三、Kafka架构设计
3.1 专业术语
-
Broker 消息服务器(类比namenode)
-
Producer
-
Consumer
-
Topic 主题(”管道“的名字)
-
Queue 队列,P2P模式下的消息队列
3.2 详细解释
Kafka中发布订阅的对象是topic。我们可以为每类数据创建一个topic,把向topic发布消息的客户端称作producer,从topic订阅消息的客户端称作consumer。Producers和consumers可以同时从多个topic读写数据。一个kafka集群由一个或多个broker服务器组成,它负责持久化和备份具体的kafka消息。
- Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker 可以组成一个Kafka集群。
- Topic:一类消息,消息存放的目录即主题,例如page view日志、click 日志等都可以以topic的形式存在,Kafka集群能够同时负责多 个topic的分发。
- Partition:topic物理上的分组,一个topic可以分为多个partition, 每个partition是一个有序的队列
- Segment:partition物理上由多个segment组成,每个Segment存 着message信息
- Producer : 生产message发送到topic
- Consumer : 订阅topic消费message, consumer作为一个线程来消费
- Consumer Group:一个Consumer Group包含多个consumer, 这个是预先在配置文件中配置好的。各个consumer(consumer 线程)可以组成一个组(Consumer group ),partition中的每个message只能被组(Consumer group ) 中的一个consumer(consumer 线程 )消费,如果一个message可以被多个consumer(consumer 线程 ) 消费的话,那么这些consumer必须在不同的组。Kafka不支持一个partition中的message由两个或两个以上的consumer thread来处理,即便是来自不同的consumer group的也不行。它不能像AMQ那样可以多个BET作为consumer去处理message,这是因为多个BET去消费一个Queue中的数据的时候,由于要保证不能多个线程拿同一条message,所以就需要行级别悲观所(for update),这就导致了consume的性能下降,吞吐量不够。而kafka为了保证吞吐量,只允许一个consumer线程去访问一个partition。如果觉得效率不高的时候,可以加partition的数量来横向扩展,那么再加新的consumer thread去消费。这样没有锁竞争,充分发挥了横向的扩展性,吞吐量极高。这也就形成了分布式消费的概念。
关于zookeeper的作用:记录状态信息的死活
>>> zkCli.sh ls / ls /brokers/topics/event_attendees/partitions/0/state
旧版本游标offset存在于zk中,不合理,后改成存在_consumer_offset_这个专门的topic中
>>> 真正的数据+游标在kfk中!
四、安装
- 首先前置安装zookeeper(步骤见zookeeper)
- 解压kafka(这里使用的是kafka2.11_2.0.0.tgz)
- 配置config/server.properties
-
3.1 如果是分布式环境则需要修改broker.id的编号不能相同
3.2 log.dir是存储数据的位置需要指定(不是日志)
3.3 Zookeeper.connect=你的zookeeper的IP:2182(多个用逗号隔开)
-
- 启动步骤
- 首先启动zookeeper(集群,如果有)
- 其次编写启动kafka的脚本(例如:kafka.sh)让kafka后台启动
nohup kafka-server-start.sh /opt/bigdata/kafka211/config/server.properties > kafka.log 2>&1 &
五、常用命令
更多命令:https://www.cnblogs.com/itwild/p/12287850.html
基础命令
1)建立topic(消息队列)
kafka-topics.sh --create --zookeeper 192.168.56.111:2181 --replication-factor 1 --partitions 1 --topic mydemo
显示所有topic
kafka-topics.sh --zookeeper 192.168.56.111:2181 --list
2)生产
// 不指定key kafka-console-producer.sh --topic mydemo --broker-list 192.168.56.111:9092 // 指定key kafka-console-producer.sh --broker-list 192.168.56.111:9092 --topic msg01 --property "parse.key=true" --property "key.separator=:"
3)消费
kafka-console-consumer.sh --bootstrap-server 192.168.56.111:9092 --topic mymsg_java // 实时消费 kafka-console-consumer.sh --bootstrap-server 192.168.56.111:9092 --topic mymsg_java --from-beginning // 历史消费
| grep 查找关键字
kafka-console-consumer.sh --bootstrap-server 192.168.56.111:9092 --topic mmm --from-beginning | grep 12

其他命令
1)某个topic某个分区总共有多少消息:
--time -1 指针能移动到的最大值
--time -2 最小值,一般是0
kafka-run-class.sh kafka.tools.GetOffsetShell --topic mydemo --time -1 --broker-list 192.168.56.111:9092 --partitions 0
2)如何删除topic
kafka-topics.sh --zookeeper 192.168.56.111:2181 --delete --topic mydemo // 删不掉topic
因为有开关没开 delete.topic.enable=true => 在kafka112/config/server.properties加一行。
重启后可删topic,若提示没删掉,可能是有延迟。
3)消息在topic中可以呆多久,topic本身不删掉
kafka retention.ms
4)查看topic中的命令(所有partition)
kafka-console-consumer.sh --bootstrap-server 192.168.56.111:9092 --topic msg01 --from-beginning
5) 还原offset
kafka-consumer-groups.sh --bootstrap-server 192.168.56.111:9092 --group cm3 --reset-offsets --topic mymsg_java --to-earliest --execute
六、Java操作Kafka
(一)pom
<!-- 211代表scala的版本。2.0.0才是kafka的版本--> <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> // kafka核心 <version>2.0.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> // 第三方操作kafka <version>2.0.0</version> </dependency>
(二)代码
(1)生产
Properties prop = new Properties(); prop.put("bootstrap.servers","192.168.56.111:9092"); prop.put("acks","all"); prop.put("retries","0"); prop.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer"); prop.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> producer = new KafkaProducer<>(prop);
//String topic,K key,V value ProducerRecord<String,String> msg = new ProducerRecord<String,String,String>("mymsg_java","msg","hello,world"); producer.send(msg); // 一定要关~ producer.close();
(2)消费
Properties prop = new Properties(); prop.put("bootstrap.servers","192.168.56.111:9092"); prop.put("group.id","cm3"); // 如果已经消费过了,还能在消费吗?不能 prop.put("enable.auto.commit",true); //自动提交 prop.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); prop.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer"); prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");// 从头开始拿数据 KafkaConsumer<String,String> consumer = new KafkaConsumer<>(prop); consumer.subscribe(Arrays.asList("mymsg_java")); // 消费topic为x //consumer.assgin(""); # 消费分区为x while(true){ ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(1)); // 消费者每秒拿一批(实时,有多少拿多少) if(!records.isEmpty()){ for(ConsumerRecord<String, String> rec : records){ System.out.println(rec.value()); } } }
实时监控生产者产出的消息,但由于一组group只有一个指针(offset),一旦关闭再次消费的时候,不能从头显示消息
想要从头显示:
1)每次都改组名cm3 => cm4
2)把某组指针还原成0 => kafka-consumer-groups.sh --bootstrap-server 192.168.56.111:9092 --group cm3 --reset-offsets --topic mymsg_java --to-earliest --execute
(3)案例:用多线程(每个线程都是一个同组consumer)如何消费不同分区数据?
建立三个分区的新topic
# 三个分区 kafka-topics.sh --create --zookeeper 192.168.56.111:2181 --replication-factor 1 --partitions 3 --topic msg01
生产数据到不同分区,key用来分区(不同于Java的hash方法!),value是实际的值
for (int i = 0; i <10 ; i++) { ProducerRecord<String,String> rec = new ProducerRecord<>("msg01",""+i,"test"+i); // topic,key,value producer.send(rec); }
多线程,每个线程都是一个消费者
工作中一般手动提交,消费一次同步提交一次 consumer.commitSync();
前提是 ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG = false
package com.njbdqn.mykafka; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.TopicPartition; import java.time.Duration; import java.util.Arrays; public class MyThread implements Runnable { private KafkaConsumer<String,String> consumer; private int partitionId; public MyThread(KafkaConsumer<String,String> con,int part){ this.consumer = con; this.partitionId = part; } @Override public void run() { // 消费者消费第__分区 TopicPartition tp = new TopicPartition("msg01",partitionId); consumer.assign(Arrays.asList(tp)); while (true){ ConsumerRecords<String,String> records = consumer.poll(Duration.ofSeconds(1)); if(!records.isEmpty()){ for(ConsumerRecord rec : records){ System.out.println("Thread"+Thread.currentThread().getName()+",Partition:" +rec.partition()+",value:"+rec.value()); } } consumer.commitSync(); // 手动提交偏移量! } } }
public static void main(String[] args) { Properties prop = new Properties(); prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.56.111:9092"); prop.put(ConsumerConfig.GROUP_ID_CONFIG,"cm4"); // 如果已经消费过了,还能在消费吗?不能 prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false); prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class); prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");//从头开始 //KafkaConsumer<String,String> consumer = new KafkaConsumer<>(prop); ExecutorService es = Executors.newFixedThreadPool(3); for (int i = 0; i <3 ; i++) { // 每个线程都应该是一个new Consumer es.execute(new MyThread(new KafkaConsumer<>(prop),i)); } es.shutdown(); }


(三)控制台接收
实时接收:
kafka-console-consumer.sh --bootstrap-server 192.168.56.111:9092 --topic mymsg_java
>>> AAA
包含历史数据:
kafka-console-consumer.sh --bootstrap-server 192.168.56.111:9092 --topic mymsg_java --from-beginning
>>> hello,world
>>> AAA
七、Scala操作Kafka
1.当不指定key,从flume导入kafka时,默认进partition 0,key为多少?
import java.time.Duration import java.util import java.util.Properties import org.apache.kafka.clients.consumer.{ConsumerConfig, KafkaConsumer} import org.apache.kafka.common.serialization.StringDeserializer object MyDemo { def main(args: Array[String]): Unit = { val prop = new Properties(); prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.56.111:9092") prop.put(ConsumerConfig.GROUP_ID_CONFIG,"wcl5") prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true") prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,classOf[StringDeserializer]) prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,classOf[StringDeserializer]) prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest") val consumer = new KafkaConsumer[String,String](prop) consumer.subscribe(util.Arrays.asList("events")) while (true){ val recodes = consumer.poll(Duration.ofSeconds(1)) if (!recodes.isEmpty){ import scala.collection.JavaConversions._ // for(rec <- recodes){ // println("key:"+rec.key()) // } recodes.iterator().foreach(f=>{ println("key:"+f.key()) }) // consumer.commitAsync() } } } }
