请选择一种我们课程中介绍的设计模式,用您熟悉的编程语言提供一个典型的应用范例,并分析其代码结构特性。完成一篇研究报告,具体要求如下:
- 引用关键代码(引用代码是为解释说明服务的,不要贴对解释问题无关的代码)解释该设计模式在该应用场景中的适用性;
- 引入该设计模式后对系统架构和代码结构带来了哪些好处;
- 解释其中用到的多态机制;
- 说明模块抽象封装的方法;
- 分析各个模块的内聚度和模块之间的耦合度;
- 提供该应用范例完整的源代码包括构建部署的操作过程,建议以github版本库URL的方式提供源代码,其中README.md中说明构建部署的操作过程。
如下为图像分辨率增强项目,使用的是行为型迭代器模式;
迭代器(Iterator)模式:提供一种方法来顺序访问聚合对象中的一系列数据,而不暴露聚合对象的内部表示。
生成式对抗网络GAN近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。
SRGAN旨在增强图像分辨率,是在keras框架上的代码实现。

如上目录,首先使用VGG19进行特征提取,使用迁移学习可以节省大量的训练时间,imagenet的初始权重本身在图像类任务上具有十分优秀的效果,用来做特征提取可以有效的获取图片的有效特征信息。
接下来是生成器和判别器的构建,因为GAN的原理就是通过在这两个容器上进行相互博弈缩小损失函数的期望值,最终来产生比较好的输出,下为构建模型。
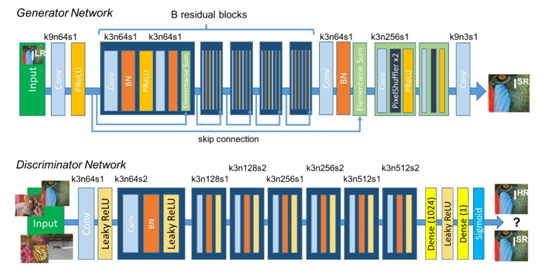

生成器主要用来学习真实图像分布从而让自身生成的图像更加真实,以骗过判别器。

由于生成器的输入为低分辨率图片特征,卷积会使图片信息不断减少,而生产高分辨率的图片则需反其道而行之,利用反卷积放大图像。
判别器需要对接收的图片进行真假判别。在整个过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别出图像的真假

原图为正例,生成图片为负例。训练判别器的目标是使其能正确区分原图与生成的图片。


最终通过不断训练,随着时间迭代次数越多,最终生成的图像分辨率越高。
最终总结与分析:
此代码结构分为几个模块,生成器,判别器,特征提取网络和训练过程,最终完成整个深度学习的过程。
其中各个模块通过函数进行抽象封装。
由于训练器需要不断访问生成器和判别器的内容进行训练验证,因此模块之间具有耦合程度。
但是生成器与判别器没有在训练过程中相互访问较少,只通过最后结果判别拟合程度,因此耦合程度为非直接耦合。
至于内聚程度,生成器与判别器都是为了降低损失函数还进行不断训练, 因此内聚程度为功能内聚,内聚程度较高。
源码链接:https://github.com/OUCMachineLearning/OUCML/blob/master/GAN/srgan_celebA/srgan.py