简介
- Apache Kylin(Extreme OLAP Engine for Big Data)是一个开源的分布式 分析引擎,为Hadoop等大型分布式数据平台之上的超大规模数据集通过标准 SQL查询及多维分析(OLAP)功能,提供亚秒级的交互式分析能力。
- Apache Kylin是一个开源的分布式分析引擎,最初由eBay开发贡献至开源社区。
- 它提供Hadoop之上的SQL查询接口及 多维分析(OLAP)能力以支持大规模数据,能够处理TB乃至PB级别的分析任务,能够在 亚秒级查询巨大的Hive表,并支持高并发。
- 于2014年10月在github开源,并很快在2014年11月加入Apache孵化器,于 2015年11月正式毕业成为Apache顶级项目,也成为首个完全由中国团队设计开发的 Apache顶级项目。
- 于2016年3月,Apache Kylin核心开发成员创建了Kyligence公司,力求 更好地推动项目和社区的快速发展。
使用它的原因
- 在大数据的背景下,Hadoop的出现解决了数据存储问题,但如何对海量数据进行 OLAP查询,却一直令人十分头疼。企业中大数据查询大致分为两种:即席查询和定制查询。
- 即席查询
- Hive、SparkSQL等OLAP引擎,虽然在很大程度上降低了数据分析的难度,但它们都只适用于即席查询的场景。
- 它们的优点是查询灵活,但是随着数据量和计算复杂度的增长,响应时间不能得到保证。
- 定制查询
- 多数情况下是对用户的操作做出实时反应,Hive等查询引擎很难满足实时查询,一般只能对数据仓库中的数据进行提前计算,然后将结果存入Mysql等关系型数据库,最后提供给用户进行查询。
- 即席查询
- 在上述背景下,Apache Kylin应运而生。
- 不同于"大规模并行处理"Hive等架构,Apache Kylin采用" 预计算"的模式。
- 用户只需要提前定义好查询维度,Kylin将帮助我们进行计算,并将结果存储到HBase 中,为海量数据的查询和分析提供亚秒级返回,是一种典型的"空间换时间"的解决方案。
- Apache Kylin的出现不仅很好地解决了海量数据快速查询的问题,也避免了手动开发和维护提前计算程 序带来的一系列麻烦。
工作原理
- 对数据模型做Cube预计算就是Kylin的工作原理,典型的空间换时间的例子。
- 利用cube计算的结构加速我们的查询。具体过程如下:
- 指定数据模型, 定义维度和度量。
- 预计算Cube, 计算所有Cuboid并保存为物化视图。
- 执行查询时, 读取 Cuboid, 运算, 产生查询结果。
- Kylin的查询过程不会扫描原始记录,而是通过预计算预先完成表的关联、聚合等复杂运算,并利用预计算的结果来执行查询。
- 因此相比非预计算的查询技术,其速度一般要快一到两个数量级,并且这点在超 大的数据集上优势更明显。
- 当数据集达到千亿乃至万亿级别时,Kylin的 速度甚至可以超越其他非预计算技术1000倍以上。
- 总结:
- Kylin的核心思想是Cube预计算,理论基础是空间换时间,把高复杂度的聚合运算、多表连接等操作转换成对预计算结果的查询。
技术架构
-
官网架构图(2.x版)
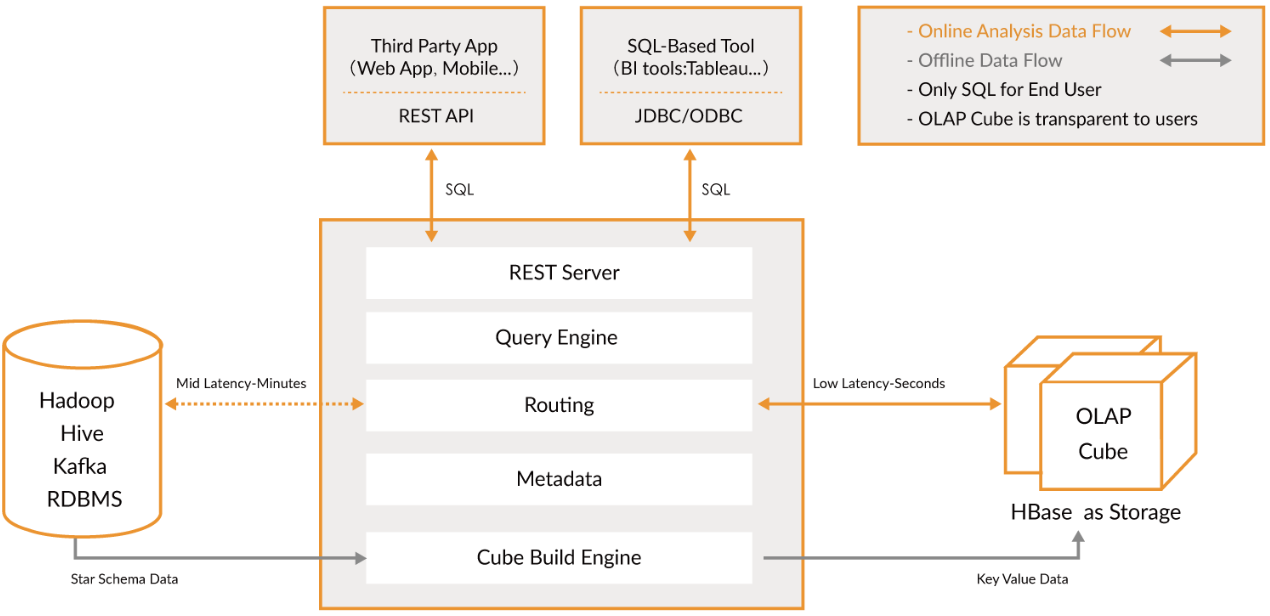
-
1.5版中文架构图
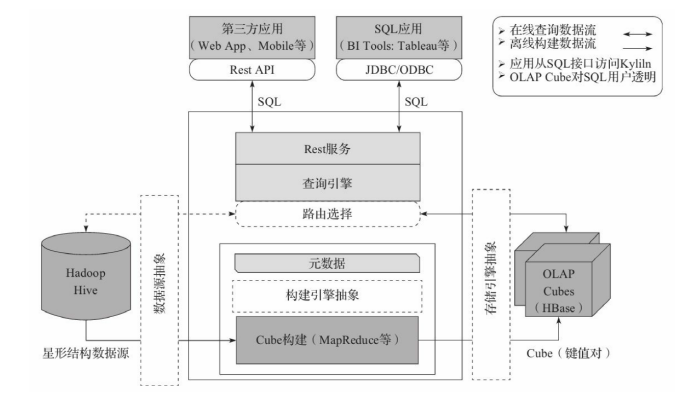
-
Kylin系统主要分为在线查询和离线构建两个部分,橙色线代表在线,灰色线代表离线。
-
Kylin是一个开源的分布式分析引擎,提供一个标准的sql接口,给我们多维分析(OLAP)提供帮助。
-
可以把kylin理解为一个数据仓库。对比之前的hive,想要一些计算结果我们可能会写一些脚本实现将结果集算好。
-
但是对应业务复杂,维度变化更多的情况,你用shell脚本就不好控制了。Kylin就是按照你想要的维度给你全部构建好。
-
用户可以从上方查询系统发送SQL进行查询分析。Kylin提供了各种Rest API、JDBC/ODBC接口。
-
无论从哪个接口进入,SQL最终都会来到Rest服务层,再转交给查询引擎进行处理。
-
这里需要注意的是,SQL语句是基于数据源的关系模型书写的,而不是Cube。
-
Kylin在设计时刻意对查询用户屏蔽了Cube的概念,分析师只需要理解简单的关系模型就可以使用Kylin,没有额外的学习门槛,传统的SQL应用也很容易迁移。
-
查询引擎解析SQL,生成基于关系表的逻辑执行计划,然后将其转译为基于Cube的物理执行计划,最后查询预计算生成的Cube并产生结果。整个过程不会访问原始数据源。
-
注意点:
- 对于查询引擎下方的路由选择,在设计者曾考虑过将Kylin不能执行的查询引导去Hive中继续执行,但在实践后发现Hive与Kylin的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。
- 最后这个路由功能在发行版中默认关闭,因此在图中是用虚线表示的。
- 架构图分析
- 左侧为数据来源,消息队列、hive等拿到数据之后,通过kylin处理,将hbase作为存储介质,满足一定的实时性要求(Hbase中的每行记录的Rowkey由dimension组成,measure会保存在column family中。
- 为了减小存储代价,这里会对dimension和measure进行编码。
- 查询阶段,利用HBase列存储的特性就可以保证Kylin有良好的快速响应和高并发。
- Kylin在中间作为媒介,提供rest api使用以及jdbc接口供BI软件做报表的支撑(拓展软件:tableau,superset)。
-
总结:
- hive查询时间随着数据量的增长而线性增长,kylin使用预计算技术打破了这一点。
- kylin在数据集规模上的局限性主要取决于维度的个数和基数,而不是数据集的大小,所以Kylin能更好地支持海量数据集的查询。
- 而也正是预计算技术,kylin的查询速度非常快,亚秒级响应。
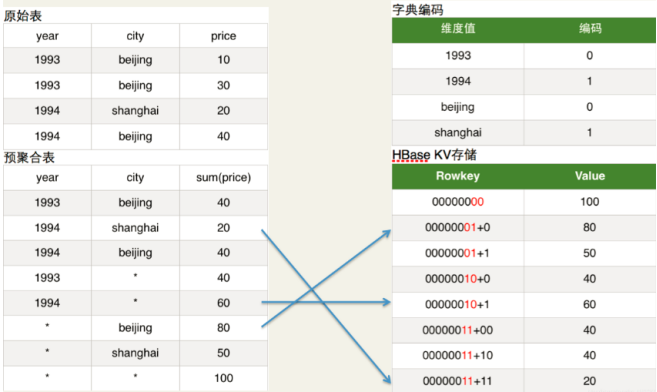
Kylin 主要特点:
-
支持SQL接口
- Apache Kylin以标准SQL作为对外服务的主要接口
- Kylin使用的查询模型是数据源中的关系模型表,一般而言,也就是指Hive表。
- 终端用户只需要像原来查询Hive表一样编写SQL,就可以无缝地切换到Kylin,几乎不需要额外的学习。
- 甚至原本的Hive查询也因为与SQL同源,大多都无须修改就能直接在Kylin上运行。
-
支持超大数据集
- Apache Kylin对大数据的支撑能力可能是目前所有技术中最为领先的。
- 早在2015年eBay的生产环境中Kylin就能支持百亿记录的秒级查询,之后在移动的应用场景下又有了千亿记录秒级查询的案例。
- 因为使用了Cube预计算技术,在理论上,Kylin可以支撑的数据集大小没有上限,仅受限于存储系统和分布式计算系统的承载能力,并且查询速度不会随数据集的增大而减慢。
- Kylin在数据集规模上的局限性主要在于维度的个数和基数。它们一般由数据模型来决定,不会随着数据规模的增长而线性增长,这也意味着Kylin对未来数据的增长有着更强的适应能力。
-
压秒级响应
- Apache Kylin拥有优异的查询响应速度,这点得益于预计算。
- 很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需要的计算量,提高了响应速度。
- 根据可查询到的公开资料可以得知,Apache Kylin在某生产环境中90%的查询可以在3s内返回结果。
- 这并不是说一小部分SQL相当快,而是在数万种不同SQL的真实生产系统中,绝大部分的查询都非常迅速。
- 在另外一个真实的案例中,对1000多亿条数据构建了立方体,90%的查询性能都在1.18s以内,可见Kylin在超大规模数据集上表现优异。
-
可伸缩性
-
高吞吐率
-
BI 工具集成
- 提供了丰富的API,以与现有的BI工具集成,具体包括如下内容:
- ODBC接口,与Tableau、Excel、Power BI等工具集成。
- JDBC接口,与Saiku、BIRT等Java工具集成。
- Rest API,与JavaScript、Web网页集成。
- 分析师可以沿用他们最熟悉的BI工具与Kylin一同工作,或者在开放的API上做二次开发和深度定制。
- 提供了丰富的API,以与现有的BI工具集成,具体包括如下内容:
-
总结:
- 传统技术,如大规模并行计算和列式存储的查询速度都在O(N)级别,与数据规模增线性关系。
- 如果数据规模增长10倍,那么O(N)的查询速度就会下降到十分之一,无法满足日益增长的数据需求。
- Apache Kylin,我们不用再担心查询速度会随着数据量的增长而减慢。
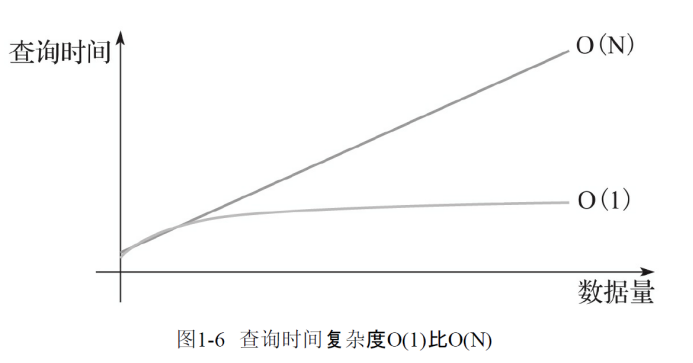
增量 Cube
-
Cube划分为多个Segment,每个Segment用起始时间和结束时 间来标志。
-
Segment代表一段时间内源数据的预计算结果。
-
在大部分情况下一个Segment的起始时间等于它之前那个Segment的结束时间,同理,它的结束时间等于它后面那个Segment的起始时间。
-
同一个Cube下不同的Segment除了背后的源数据不同之外,其他如结构定义、构建过程、优化方法、存储方式等都完全相同。
-
全量构建可以看作增量构建的一种特例:在全量构建中,Cube中只存 在唯一的一个Segment,该Segment没有分割时间的概念,因此也就没有起始时间和结束时间。
-
全量构建和增量构建各有其适用的场景,用户可以根据自己的业务场景灵活地进行切换。全量构建和增量构建的详细对比如下图:

-
对于全量构建来说,每当需要更新Cube数据的时候,它不会区分历史数据和新加入的数据,也就是说,在构建的时候会导入并处理所有的 原始数据。
-
而增量构建只会导入新Segment指定的时间区间内的原始数 据,并只对这部分原始数据进行预计算。
-
增量构建的前提:
- 并非所有的Cube都适用于增量构建,Cube的定义必须包含一个时间 维度,用来分割不同的Segment,我们将这样的维度称为分割时间列 (Partition Date Column)。
- 分割时间列既可以是Hive中的Date类型、也可以是Timestamp类型或 String类型。
- 无论是哪种类型,Kylin都要求用户显式地指定分割时间列的 数据格式,例如精确到年月日的Date类型(或者String类型)的数据格式可能是yyyyMMdd或yyyy-MM-dd,如果是精确到时分秒的Timestamp类型(或者String类型),那么数据格式可能是YYYY-MM-DD HH:MM:SS。
-
触发增量构建
-
自动合并
-
保留 Segment
Cuboid 以及 cube 优化
-
Cuboid = one combination of dimensions
-
Cube = all combination of dimensions (all cuboids)
-
按照dimension大小顺序排序,从Base Cuboid开始,依次基于上一层Cuboid的结果进行再聚合。每一层的计算都是一个单独 的Map Reduce(Spark)任务。
-
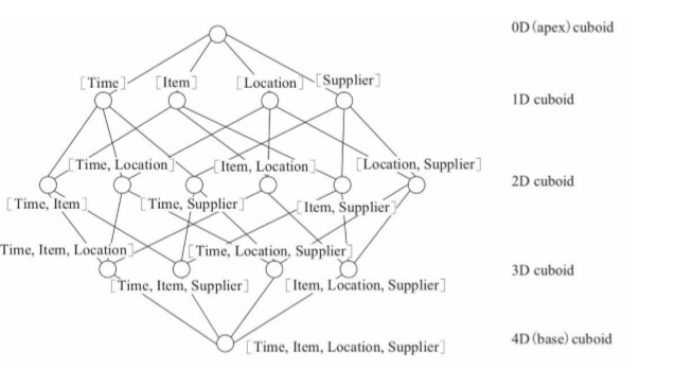
理论上来说,一个N维的Cube,便有2的N次方种维度组合,参考网上的一个例子,一个Cube包含time, item, location, supplier四个维度,那么组合(Cuboid)便有16种。
-
一个Cube中,当维度数量N超过一定数量后,空间以及计算消耗将会非常大,比如说10维那就是1024个cuboid,但我们真正查询的时候可能只会用到其中的100个cuboid,如果不做优化那么会出现以下几个问题:
- 会使得Build出来的Cube Size 很大,从而占用大量的磁盘空间;
- Cube Building的时间会很长;
- 会占用集群的计算资源
-
Cube剪枝优化
-
聚合组Aggravation Group
- Kylin在定义Cube时候,可以将维度拆分成多个聚合组(Aggregation Groups)这也就是我们在web页面创建cube时的第5步可以做。
- 只在组内计算Cube,聚合组内查询效率高,跨组查询效率较差。
- 所以需要根据业务场景,将常用的维度组合定义到一个聚合组中,提高查询性能,这也是Kylin中查询性能优化的一个重要方面。
-
RowKey 编码优化
- Kylin 目前支持的编码优化。
- Date编码:
- 将日期类型的数据使用三个字节进行编码,其支持从 0000-01-01到9999-01-01中的每一个日期。
- Time编码:
- 仅支持表示从1970-01-01 00:00:00到2038-01-19 03:14:07的时间,且Time-stamp类型的维度经过编码和反编码之后,会失去毫秒信息,所以说Time编码仅仅支持到秒。
- 但是Time编码的优势是每个维度 仅仅使用4个字节,这相比普通的长整数编码节约了一半。如果能够接受 秒级的时间精度,请选择Time编码来代表时间的维度。
- Integer编码
- Integer编码需要提供一个额外的参数“Length”来代表需 要多少个字节。
- Length的长度为1~8。如果用来编码int32类型的整数,可以将Length设为4。
- 如果用来编码int64类型的整数,可以将Length设为8。
- 在更多情况下,如果知道一个整数类型维度的可能值都很小,那么就能使用 Length为2甚至是1的int编码来存储,这将能够有效避免存储空间的浪费。
- Dict 编码
- 对于使用该种编码的维度,每个Segment在构建的时候都会为这个维度所有可能的值创建一个字典,然后使用字典中每个值的编 号来编码。
- Dict的优势是产生的编码非常紧凑,尤其在维度值的基数较小且长度较大的情况下,特别节约空间。
- 由于产生的字典是在查询时加载入构建引擎和查询引擎的,所以在维度的基数大、长度也大的情况下,容易造成构建引擎或查询引擎的内存溢出。
- Fixed_length 编码
- 编码需要提供一个额外的参数“Length”来代表需 要多少个字节。该编码可以看作Dict编码的一种补充。
- 对于基数大、长度 也大的维度来说,使用Dict可能不能正常工作,于是可以采用一段固定长度的字节来存储代表维度值的字节数组,该数组为字符串形式的维度值的UTF-8字节。
- 如果维度值的长度大于预设的Length,那么超出的部分将会被截断。
- Fixed_Length_Hex 编码
- 适用于字段值为十六进制字符,比如1A2BFF或者FF00FF,每两个字符需要一个字节。
- 只适用于varchar或nvarchar类型。
- Date编码:
- Kylin 目前支持的编码优化。
-