一、HDFS的相关基本概念
1.数据块
1、在HDFS中,文件诶切分成固定大小的数据块,默认大小为64MB(hadoop2.x以后是128M),也可以自己配置。
2、为何数据块如此大,因为数据传输时间超过寻到时间(高吞吐率)。
3、文件的存储方式,按大小被切分成若干个block,存储在不同的节点上,默认情况下每个block有三个副本。
2.复制因子
就是一个block分为多少个副本,默认情况下是3个
3.fsimage文件作用:
fsimage是元数据镜像文件(保存文件系统的目录树)。
4.edits文件作用
fsedits 是元数据操作日志(记录每次保存fsimage之后到下次保存之间的所有hdfs操作)。
5.安全模式
当开启安全模式后,对文件的修改和删除都会有错误提示
enter 进入安全模式
leave 离开安全模式
get 返回安全模式是否开启的信息
6.NameNode
(HA集群启动时,可以同时启动2个NameNode。这些NameNode只有一个是active的,另一个属于standby状态)
作用是一个文件系统树,文件树中的文件和文件夹中的元数据。
namenode负责管理文件目录,文件和block的对应关系以及block和datanode的对应关系。
由两部分组成:
1.fsimage;
2.fsedits:
7.DataNode
作为NameNode的工作节点,根据客户端或者NameNode的调度存储和检索数据,
当客户端请求读或写时,NameNode会告知客户端去哪些DataNode进行读写,
然后客户端直接与相应的DataNode进行通信
8.SecondaryNameNode
由于Edit log不断增长,在NameNode重启时,会造成长时间NameNode处于安全模式,不可用状态,是非常不符合Hadoop的设计初衷。
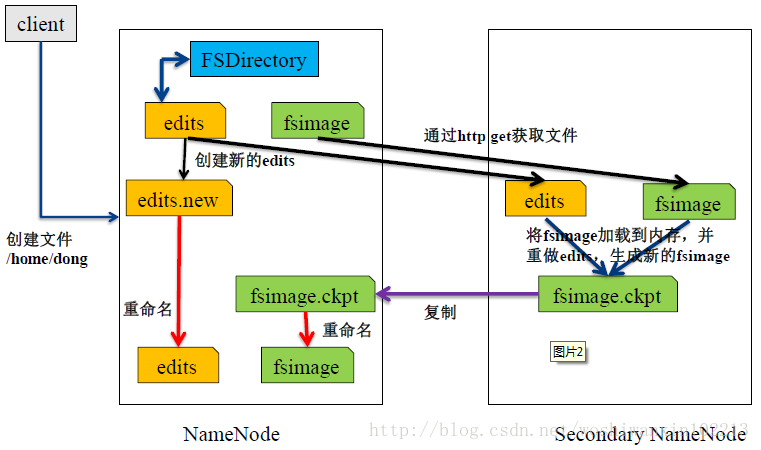
所以要周期性合并Edit log,但是这个工作由NameNode来完成,会占用大量资源,这样就出现了Secondary NameNode,它可以进行image检查点的处理工作。步骤如下:
(1)Secondary NameNode请求NameNode进行edit log的滚动(即创建一个新的edit log),将新的编辑操作记录到新生成的edit log文件;
(2)通过http get方式,读取NameNode上的fsimage和edits文件,到Secondary NameNode上;
(3)读取fsimage到内存中,即加载fsimage到内存,然后执行edits中所有操作(类似OracleDG,应用redo log),并生成一个新的fsimage文件,即这个检查点被创建;
(4)通过http post方式,将新的fsimage文件传送到NameNode;
(5)NameNode使用新的fsimage替换原来的fsimage文件,让(1)创建的edits替代原来的edits文件;并且更新fsimage文件的检查点时间。
关系图如下:
二、分布式集群的搭建
1.环境说明
在学习一中,已经配置好了伪分布式集群,即一个节点的集群测试。要搭的是在此基础上搭建的三个节点的集群
即master作为NameNode节点,slaver1 slaver2 作为DataNode节点
2.分布式集群搭建
1.创建三个虚拟机(通过vmware的克隆功能,直接克隆之前创建的qjx主机,然后修改主机名和IP地址,根据自己内存大小分配虚拟机内存)主机名和IP分别为
| master | 192.168.32.10 |
| slaver1 | 192.168.32.11 |
| slaver2 | 192.168.32.12 |
2.三个主机都关闭防火墙(root)
/etc/init.d/iptables stop
3.修改hosts文件,将IP和主机名添加到最后一行
vim /etc/hosts 192.168.32.10 master 192.168.32.11 slaver1 192.168.32.12 slaver2
4.添加三个主机的互信操作
ssh-keygen ssh-copyid master ssh-copyid slaver1 ssh-copyid slaver2
5.修改配置文件 hadoop-2.6.0/etc/hadoop/slaves.xml 添加子节点的主机名
vim hadoop-2.6.0/etc/hadoop/slavers slaver1 slaver2
6.修改配置文件 hadoop-2.6.0/etc/hadoop/core-site.xml(tmp.dir配置中,目录可以根据自己主机更改)
<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/qjx/hadoop/hadoop-2.6.0/dataSoft/tmp</value> <description>Abasefor other temporary directories.</description> </property>
7.修改配置文件 hadoop-2.6.0/etc/hadoop/hdfs-site.xml(目录配置为自己新建的一个临时目录,为了存储每次进入的临时文件,若没有指定,即为/tmp/下,每次进入主机都要改变)
<property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/qjx/dataSoft/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/qjx/dataSoft/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property>
8.修改配置文件 hadoop-2.6.0/etc/hadoop/mapred-site.xml(本来不存在,由hadoop-2.6.0/etc/hadoop/mapred-site.xml.temp文件复制来)
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property>
9.修改配置文件 hadoop-2.6.0/etc/hadoop/yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property>
10.将配置好的master的配置文件拷贝到slaver1,slaver2的配置文件中
scp -r hadoop-2.6.0/ etc/hadoop/*@slave1:~/hadoop/hadoop-2.6.0/etc/hadoop/ scp -r hadoop-2.6.0/ etc/hadoop/*@slave2:~/hadoop/hadoop-2.6.0/etc/hadoop/
11.格式化HDFS,在hadoop-2.6.0目录下执行
bin/hdfs namenode -format
注意:格式化只能操作一次,如果因为某种原因,集群不能用, 需要再次格式化,需要把上一次格式化的信息删除,在三个节点用户根目录里执行 rm -rf /home/qjx/hadoop/hadoop-2.6.0/dfs/*
12.在master节点执行sbin/start-all.sh 输入jps后,master节点显示4条,slaver1,slaver2节点各显示3条为配置正确
三、HDFS基本命令的使用
HDFS文件系统与Linux文件系统类似,都是从/根目录开始
1.上传
bin/hadoop fs -put 本地文件 hdfs文件路径 示例:bin/hadoop fs -put ~/put/test.txt /
2.下载
bin/hadoop fs -get hdfs文件 本地文件路径 示例:bin/hadoop fs -get /test ~/get/
3.查看文件列表
bin/hadoop fs -ls 文件路径 示例:bin/hadoop fs -ls /
4.查看文件内容
bin/hadoop fs -cat hdfs文件 示例:bin/hadoop fs -cat /test.txt
5.创建目录
创建一级目录 bin/hadoop fs -mkdir /aaa 创建多级目录 bin/hadoop fs -mkdir -p /a/b/c/
6.删除目录
bin/hadoop fs -rmdir /aaa
7.删除文件
删除文件
bin/hadoop fs -rm /test.txt
删除目录(非空)
bin/hadoop fs -rm -r /a//b/c