1 概述
1.1 决策树是如何工作的
决策树(Decision Tree)是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。决策树算法容易理解,适用各种数据,在解决各种问题时都有良好表现,尤其是以树模型为核心的各种集成算法,在各个行业和领域都有广泛的应用。
我们来简单了解一下决策树是如何工作的。决策树算法的本质是一种图结构,我们只需要问一系列问题就可以对数据进行分类了。比如说,来看看下面这组数据集,这是一系列已知物种以及所属类别的数据:
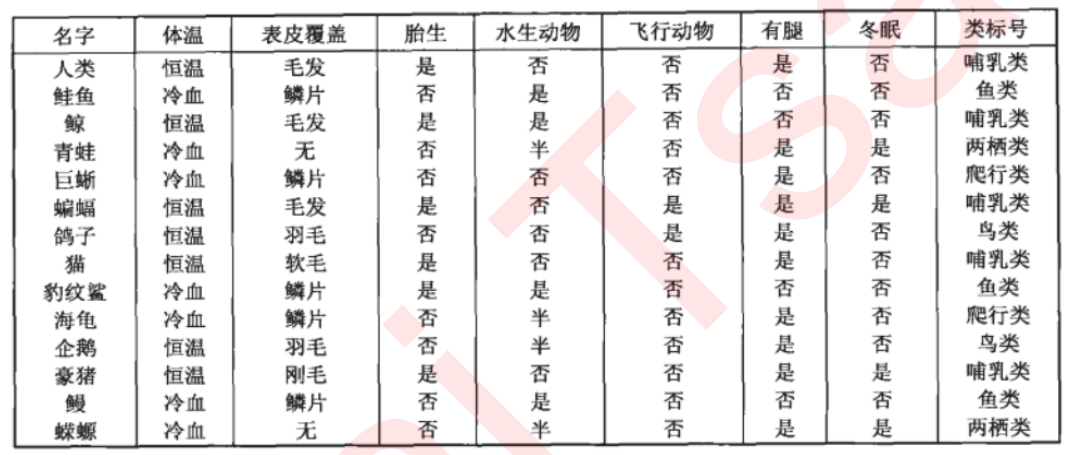
我们现在的目标是,将动物们分为哺乳类和非哺乳类。那根据已经收集到的数据,决策树算法为我们算出了下面的
这棵决策树:
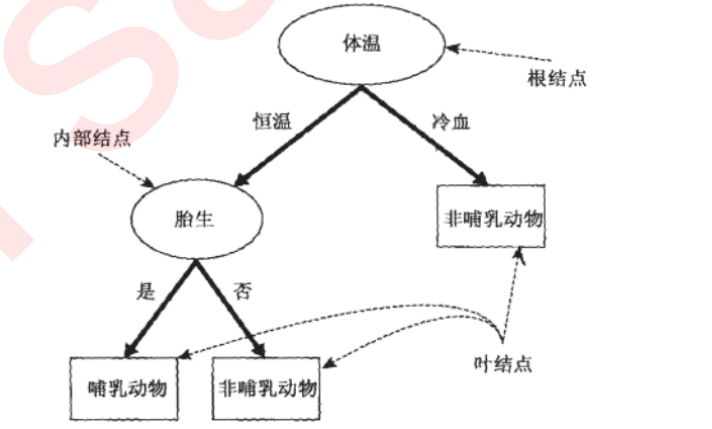
假如我们现在发现了一种新物种Python,它是冷血动物,体表带鳞片,并且不是胎生,我们就可以通过这棵决策树来判断它的所属类别。
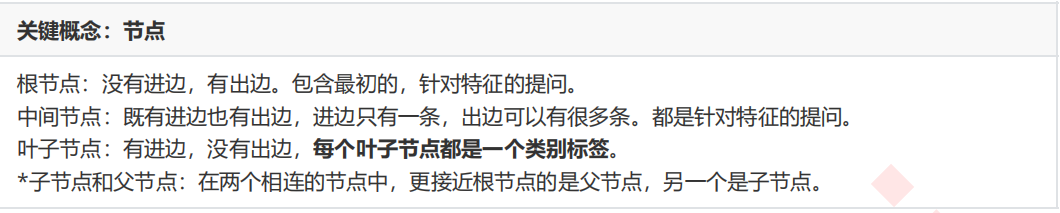
可以看出,在这个决策过程中,我们一直在对记录的特征进行提问。最初的问题所在的地方叫做根节点,在得到结论前的每一个问题都是中间节点,而得到的每一个结论(动物的类别)都叫做叶子节点。
决策树算法的核心是要解决两个问题:
1)如何从数据表中找出最佳节点和最佳分枝?
2)如何让决策树停止生长,防止过拟合?
几乎所有决策树有关的模型调整方法,都围绕这两个问题展开。这两个问题背后的原理十分复杂,我们会在讲解模型参数和属性的时候为大家简单解释涉及到的部分。在这门课中,我会尽量避免让大家太过深入到决策树复杂的原理和数学公式中(尽管决策树的原理相比其他高级的算法来说是非常简单了),这门课会专注于实践和应用。如果大家希望理解更深入的细节,建议大家在听这门课之前还是先去阅读和学习一下决策树的原理。
1.2 sklearn中的决策树
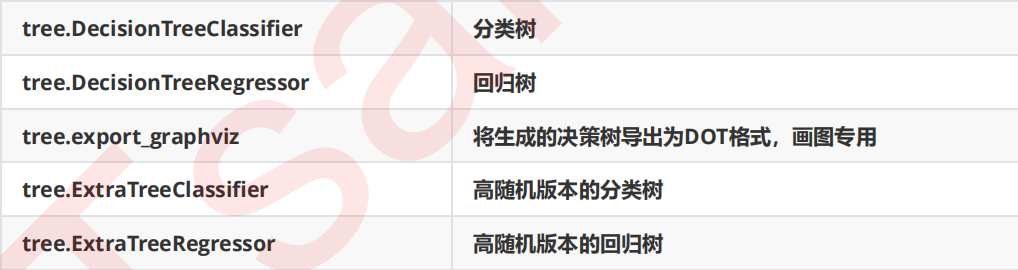
模块sklearn.tree
sklearn中决策树的类都在”tree“这个模块之下。这个模块总共包含五个类:
sklearn的基本建模流程
在那之前,我们先来了解一下sklearn建模的基本流程。

在这个流程下,分类树对应的代码是:
from sklearn import tree #导入需要的模块 clf = tree.DecisionTreeClassifier() #实例化 clf = clf.fit(X_train,y_train) #用训练集数据训练模型 result = clf.score(X_test,y_test) #导入测试集,从接口中调用需要的信息