3.特征工程
import time from datetime import datetime from datetime import timedelta import pandas as pd import pickle import os import math import numpy as np
test = pd.read_csv('data/Data_Action_201602.csv') test[['user_id','sku_id','model_id','type','cate','brand']] = test[['user_id','sku_id','model_id','type','cate','brand']].astype('float32') test.dtypes test.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 11485424 entries, 0 to 11485423 Data columns (total 7 columns): user_id float32 sku_id float32 time object model_id float32 type float32 cate float32 brand float32 dtypes: float32(6), object(1) memory usage: 350.5+ MB
test = pd.read_csv('data/Data_Action_201602.csv') test.dtypes test.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 11485424 entries, 0 to 11485423 Data columns (total 7 columns): user_id int64 sku_id int64 time object model_id float64 type int64 cate int64 brand int64 dtypes: float64(1), int64(5), object(1) memory usage: 613.4+ MB
action_1_path = r'data/Data_Action_201602.csv' action_2_path = r'data/Data_Action_201603.csv' action_3_path = r'data/Data_Action_201604.csv' comment_path = r'data/Data_Comment.csv' product_path = r'data/Data_Product.csv' user_path = r'data/Data_User.csv' comment_date = [ "2016-02-01", "2016-02-08", "2016-02-15", "2016-02-22", "2016-02-29", "2016-03-07", "2016-03-14", "2016-03-21", "2016-03-28", "2016-04-04", "2016-04-11", "2016-04-15" ]
def get_actions_0(): action = pd.read_csv(action_1_path) return action def get_actions_1(): action = pd.read_csv(action_1_path) action[['user_id','sku_id','model_id','type','cate','brand']] = action[['user_id','sku_id','model_id','type','cate','brand']].astype('float32') return action def get_actions_2(): action = pd.read_csv(action_1_path) action[['user_id','sku_id','model_id','type','cate','brand']] = action[['user_id','sku_id','model_id','type','cate','brand']].astype('float32') return action def get_actions_3(): action = pd.read_csv(action_1_path) action[['user_id','sku_id','model_id','type','cate','brand']] = action[['user_id','sku_id','model_id','type','cate','brand']].astype('float32') return action def get_actions_10(): reader = pd.read_csv(action_1_path, iterator=True) reader[['user_id','sku_id','model_id','type','cate','brand']] = reader[['user_id','sku_id','model_id','type','cate','brand']].astype('float32') chunks = [] loop = True while loop: try: chunk = reader.get_chunk(50000) chunks.append(chunk) except StopIteration: loop = False print("Iteration is stopped") action = pd.concat(chunks, ignore_index=True) return action def get_actions_20(): reader = pd.read_csv(action_2_path, iterator=True) reader[['user_id','sku_id','model_id','type','cate','brand']] = reader[['user_id','sku_id','model_id','type','cate','brand']].astype('float32') chunks = [] loop = True while loop: try: chunk = reader.get_chunk(50000) chunks.append(chunk) except StopIteration: loop = False print("Iteration is stopped") action = pd.concat(chunks, ignore_index=True) return action def get_actions_30(): reader = pd.read_csv(action_3_path, iterator=True) reader[['user_id','sku_id','model_id','type','cate','brand']] = reader[['user_id','sku_id','model_id','type','cate','brand']].astype('float32') chunks = [] loop = True while loop: try: chunk = reader.get_chunk(50000) chunks.append(chunk) except StopIteration: loop = False print("Iteration is stopped") action = pd.concat(chunks, ignore_index=True) return action # 读取并拼接所有行为记录文件 def get_all_action(): action_1 = get_actions_1() action_2 = get_actions_2() action_3 = get_actions_3() actions = pd.concat([action_1, action_2, action_3]) # type: pd.DataFrame #actions = pd.concat([action_1, action_2]) # actions = pd.read_csv(action_path) return actions # 获取某个时间段的行为记录 def get_actions(start_date, end_date, all_actions): """ :param start_date: :param end_date: :return: actions: pd.Dataframe """ actions = all_actions[(all_actions.time >= start_date) & (all_actions.time < end_date)].copy() return actions
3.1 用户基本特征
- 获取基本的用户特征,基于用户本身属性多为类别特征的特点,对age,sex,usr_lv_cd进行独热编码操作,对于用户注册时间暂时不处理
from sklearn import preprocessing def get_basic_user_feat(): # 针对年龄的中文字符问题处理,首先是读入的时候编码,填充空值,然后将其数值化,最后独热编码,此外对于sex也进行了数值类型转换 user = pd.read_csv(user_path, encoding='gbk') #user['age'].fillna('-1', inplace=True) #user['sex'].fillna(2, inplace=True) user.dropna(axis=0, how='any',inplace=True) user['sex'] = user['sex'].astype(int) user['age'] = user['age'].astype(int) le = preprocessing.LabelEncoder() age_df = le.fit_transform(user['age']) # print list(le.classes_) age_df = pd.get_dummies(age_df, prefix='age') sex_df = pd.get_dummies(user['sex'], prefix='sex') user_lv_df = pd.get_dummies(user['user_lv_cd'], prefix='user_lv_cd') user = pd.concat([user['user_id'], age_df, sex_df, user_lv_df], axis=1) return user
user = pd.read_csv(user_path, encoding='gbk') user.isnull().any()
user_id False age True sex True user_lv_cd False user_reg_tm True dtype: bool
user[user.isnull().values==True]
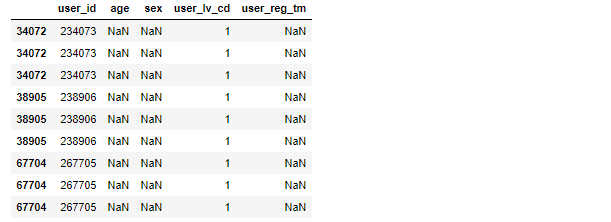
user.dropna(axis=0, how='any',inplace=True) user.isnull().any()
user_id False age False sex False user_lv_cd False user_reg_tm False dtype: bool
3.2 商品基本特征
- 根据商品文件获取基本的特征,针对属性a1,a2,a3进行独热编码,商品类别和品牌直接作为特征
def get_basic_product_feat(): product = pd.read_csv(product_path) attr1_df = pd.get_dummies(product["a1"], prefix="a1") attr2_df = pd.get_dummies(product["a2"], prefix="a2") attr3_df = pd.get_dummies(product["a3"], prefix="a3") product = pd.concat([product[['sku_id', 'cate', 'brand']], attr1_df, attr2_df, attr3_df], axis=1) return product
3.3 评论特征
- 分时间段
- 对评论数进行独热编码
def get_comments_product_feat(end_date): comments = pd.read_csv(comment_path) comment_date_end = end_date comment_date_begin = comment_date[0] for date in reversed(comment_date): if date < comment_date_end: comment_date_begin = date break comments = comments[comments.dt==comment_date_begin] df = pd.get_dummies(comments['comment_num'], prefix='comment_num') # 为了防止某个时间段不具备评论数为0的情况(测试集出现过这种情况) for i in range(0, 5): if 'comment_num_' + str(i) not in df.columns: df['comment_num_' + str(i)] = 0 df = df[['comment_num_0', 'comment_num_1', 'comment_num_2', 'comment_num_3', 'comment_num_4']] comments = pd.concat([comments, df], axis=1) # type: pd.DataFrame #del comments['dt'] #del comments['comment_num'] comments = comments[['sku_id', 'has_bad_comment', 'bad_comment_rate','comment_num_0', 'comment_num_1', 'comment_num_2', 'comment_num_3', 'comment_num_4']] return comments
train_start_date = '2016-02-01' train_end_date = datetime.strptime(train_start_date, '%Y-%m-%d') + timedelta(days=3) train_end_date = train_end_date.strftime('%Y-%m-%d') day = 3 start_date = datetime.strptime(train_end_date, '%Y-%m-%d') - timedelta(days=day) start_date = start_date.strftime('%Y-%m-%d')
comments = pd.read_csv(comment_path) comment_date_end = train_end_date comment_date_begin = comment_date[0] for date in reversed(comment_date): if date < comment_date_end: comment_date_begin = date break comments = comments[comments.dt==comment_date_begin] df = pd.get_dummies(comments['comment_num'], prefix='comment_num') for i in range(0, 5): if 'comment_num_' + str(i) not in df.columns: df['comment_num_' + str(i)] = 0 df = df[['comment_num_0', 'comment_num_1', 'comment_num_2', 'comment_num_3', 'comment_num_4']] comments = pd.concat([comments, df], axis=1) comments = comments[['sku_id', 'has_bad_comment', 'bad_comment_rate','comment_num_0', 'comment_num_1', 'comment_num_2', 'comment_num_3', 'comment_num_4']] comments.head()

3.4 行为特征
- 分时间段
- 对行为类别进行独热编码
- 分别按照用户-类别行为分组和用户-类别-商品行为分组统计,然后计算
- 用户对同类别下其他商品的行为计数
- 针对用户对同类别下目标商品的行为计数与该时间段的行为均值作差
def get_action_feat(start_date, end_date, all_actions, i): actions = get_actions(start_date, end_date, all_actions) actions = actions[['user_id', 'sku_id', 'cate','type']] # 不同时间累积的行为计数(3,5,7,10,15,21,30) df = pd.get_dummies(actions['type'], prefix='action_before_%s' %i) before_date = 'action_before_%s' %i actions = pd.concat([actions, df], axis=1) # type: pd.DataFrame # 分组统计,用户-类别-商品,不同用户对不同类别下商品的行为计数 actions = actions.groupby(['user_id', 'sku_id','cate'], as_index=False).sum() # 分组统计,用户-类别,不同用户对不同商品类别的行为计数 user_cate = actions.groupby(['user_id','cate'], as_index=False).sum() del user_cate['sku_id'] del user_cate['type'] actions = pd.merge(actions, user_cate, how='left', on=['user_id','cate']) #本类别下其他商品点击量 # 前述两种分组含有相同名称的不同行为的计数,系统会自动针对名称调整添加后缀,x,y,所以这里作差统计的是同一类别下其他商品的行为计数 actions[before_date+'_1.0_y'] = actions[before_date+'_1.0_y'] - actions[before_date+'_1.0_x'] actions[before_date+'_2.0_y'] = actions[before_date+'_2.0_y'] - actions[before_date+'_2.0_x'] actions[before_date+'_3.0_y'] = actions[before_date+'_3.0_y'] - actions[before_date+'_3.0_x'] actions[before_date+'_4.0_y'] = actions[before_date+'_4.0_y'] - actions[before_date+'_4.0_x'] actions[before_date+'_5.0_y'] = actions[before_date+'_5.0_y'] - actions[before_date+'_5.0_x'] actions[before_date+'_6.0_y'] = actions[before_date+'_6.0_y'] - actions[before_date+'_6.0_x'] # 统计用户对不同类别下商品计数与该类别下商品行为计数均值(对时间)的差值 actions[before_date+'minus_mean_1'] = actions[before_date+'_1.0_x'] - (actions[before_date+'_1.0_x']/i) actions[before_date+'minus_mean_2'] = actions[before_date+'_2.0_x'] - (actions[before_date+'_2.0_x']/i) actions[before_date+'minus_mean_3'] = actions[before_date+'_3.0_x'] - (actions[before_date+'_3.0_x']/i) actions[before_date+'minus_mean_4'] = actions[before_date+'_4.0_x'] - (actions[before_date+'_4.0_x']/i) actions[before_date+'minus_mean_5'] = actions[before_date+'_5.0_x'] - (actions[before_date+'_5.0_x']/i) actions[before_date+'minus_mean_6'] = actions[before_date+'_6.0_x'] - (actions[before_date+'_6.0_x']/i) del actions['type'] # 保留cate特征 # del actions['cate'] return actions
all_actions = get_all_action() actions = get_actions(start_date, train_end_date, all_actions) actions = actions[['user_id', 'sku_id', 'cate','type']] # 不同时间累积的行为计数(3,5,7,10,15,21,30) df = pd.get_dummies(actions['type'], prefix='action_before_%s' %3) before_date = 'action_before_%s' %3 actions = pd.concat([actions, df], axis=1) # type: pd.DataFrame # 分组统计,用户-类别-商品,不同用户对不同类别下商品的行为计数 actions = actions.groupby(['user_id', 'sku_id','cate'], as_index=False).sum() actions.head(20)
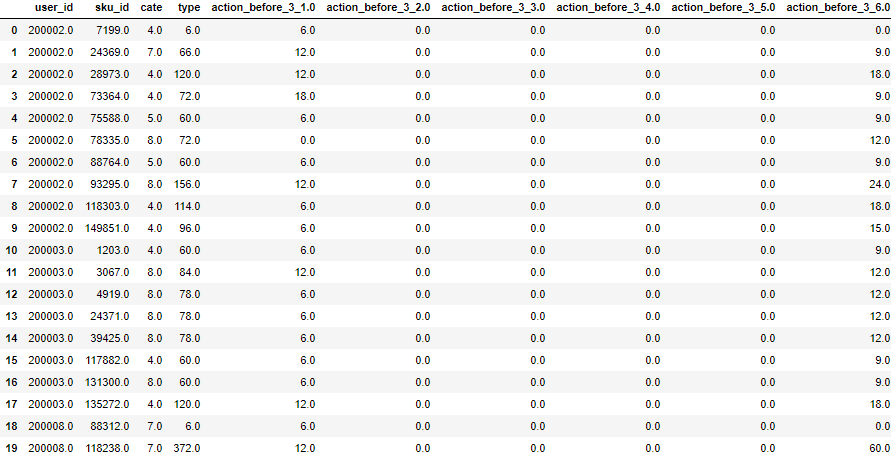
# 分组统计,用户-类别,不同用户对不同商品类别的行为计数 user_cate = actions.groupby(['user_id','cate'], as_index=False).sum() del user_cate['sku_id'] del user_cate['type'] user_cate.head()

actions = pd.merge(actions, user_cate, how='left', on=['user_id','cate']) actions.head()
actions[before_date+'_1_y'] = actions[before_date+'_1.0_y'] - actions[before_date+'_1.0_x'] actions.head()
3.5 累积用户特征
- 分时间段
- 用户不同行为的
- 购买转化率
- 均值
all_actions
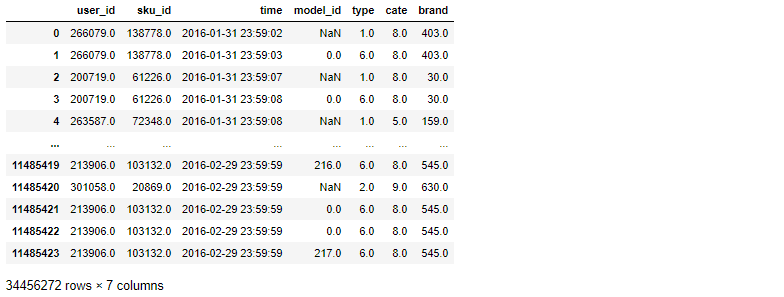
def get_accumulate_user_feat(end_date, all_actions, day): start_date = datetime.strptime(end_date, '%Y-%m-%d') - timedelta(days=day) start_date = start_date.strftime('%Y-%m-%d') before_date = 'user_action_%s' % day feature = [ 'user_id', before_date + '_1', before_date + '_2', before_date + '_3', before_date + '_4', before_date + '_5', before_date + '_6', before_date + '_1_ratio', before_date + '_2_ratio', before_date + '_3_ratio', before_date + '_5_ratio', before_date + '_6_ratio', before_date + '_1_mean', before_date + '_2_mean', before_date + '_3_mean', before_date + '_4_mean', before_date + '_5_mean', before_date + '_6_mean', before_date + '_1_std', before_date + '_2_std', before_date + '_3_std', before_date + '_4_std', before_date + '_5_std', before_date + '_6_std' ] actions = get_actions(start_date, end_date, all_actions) df = pd.get_dummies(actions['type'], prefix=before_date) actions['date'] = pd.to_datetime(actions['time']).apply(lambda x: x.date()) actions = pd.concat([actions[['user_id', 'date']], df], axis=1) actions[before_date + '_1_ratio'] = np.log(1 + actions[before_date + '_4.0']) - np.log(1 + actions[before_date +'_1.0']) actions[before_date + '_2_ratio'] = np.log(1 + actions[before_date + '_4.0']) - np.log(1 + actions[before_date +'_2.0']) actions[before_date + '_3_ratio'] = np.log(1 + actions[before_date + '_4.0']) - np.log(1 + actions[before_date +'_3.0']) actions[before_date + '_5_ratio'] = np.log(1 + actions[before_date + '_4.0']) - np.log(1 + actions[before_date +'_5.0']) actions[before_date + '_6_ratio'] = np.log(1 + actions[before_date + '_4.0']) - np.log(1 + actions[before_date +'_6.0']) # 均值 actions[before_date + '_1_mean'] = actions[before_date + '_1.0'] / day actions[before_date + '_2_mean'] = actions[before_date + '_2.0'] / day actions[before_date + '_3_mean'] = actions[before_date + '_3.0'] / day actions[before_date + '_4_mean'] = actions[before_date + '_4.0'] / day actions[before_date + '_5_mean'] = actions[before_date + '_5.0'] / day actions[before_date + '_6_mean'] = actions[before_date + '_6.0'] / day #actions = pd.merge(actions, actions_date, how='left', on='user_id') #actions = actions[feature] return actions
train_start_date = '2016-02-01' train_end_date = datetime.strptime(train_start_date, '%Y-%m-%d') + timedelta(days=3) train_end_date = train_end_date.strftime('%Y-%m-%d') day = 3 start_date = datetime.strptime(train_end_date, '%Y-%m-%d') - timedelta(days=day) start_date = start_date.strftime('%Y-%m-%d') before_date = 'user_action_%s' % day
before_date
'user_action_3'
print (start_date) print (train_end_date)
2016-02-01 2016-02-04
all_actions.shape
(34456272, 7)
actions = get_actions(start_date, train_end_date, all_actions)
actions.shape
(3015330, 7)
actions.head()

df = pd.get_dummies(actions['type'], prefix=before_date) df.head()

actions['date'] = pd.to_datetime(actions['time']).apply(lambda x: x.date()) actions = pd.concat([actions[['user_id', 'date']], df], axis=1) actions_date = actions.groupby(['user_id', 'date']).sum() actions_date.head()

actions_date = actions_date.unstack() actions_date.fillna(0, inplace=True) actions_date.head(3)

actions = actions.groupby(['user_id'], as_index=False).sum() actions.head()

actions[before_date + '_1_ratio'] = np.log(1 + actions[before_date + '_4.0']) - np.log(1 + actions[before_date +'_1.0']) actions.head()

actions[before_date + '_1_mean'] = actions[before_date + '_1.0'] / day actions.head()
3.6 用户近期行为特征
- 在上面针对用户进行累积特征提取的基础上,分别提取用户近一个月、近三天的特征,然后提取一个月内用户除去最近三天的行为占据一个月的行为的比重
def get_recent_user_feat(end_date, all_actions): actions_3 = get_accumulate_user_feat(end_date, all_actions, 3) actions_30 = get_accumulate_user_feat(end_date, all_actions, 30) actions = pd.merge(actions_3, actions_30, how ='left', on='user_id') del actions_3 del actions_30 actions['recent_action1'] = np.log(1 + actions['user_action_30_1.0']-actions['user_action_3_1.0']) - np.log(1 + actions['user_action_30_1.0']) actions['recent_action2'] = np.log(1 + actions['user_action_30_2.0']-actions['user_action_3_2.0']) - np.log(1 + actions['user_action_30_2.0']) actions['recent_action3'] = np.log(1 + actions['user_action_30_3.0']-actions['user_action_3_3.0']) - np.log(1 + actions['user_action_30_3.0']) actions['recent_action4'] = np.log(1 + actions['user_action_30_4.0']-actions['user_action_3_4.0']) - np.log(1 + actions['user_action_30_4.0']) actions['recent_action5'] = np.log(1 + actions['user_action_30_5.0']-actions['user_action_3_5.0']) - np.log(1 + actions['user_action_30_5.0']) actions['recent_action6'] = np.log(1 + actions['user_action_30_6.0']-actions['user_action_3_6.0']) - np.log(1 + actions['user_action_30_6.0']) return actions
3.7 用户对同类别下各种商品的行为
- 用户对各个类别的各项行为操作统计
- 用户对各个类别操作行为统计占对所有类别操作行为统计的比重
#增加了用户对不同类别的交互特征 def get_user_cate_feature(start_date, end_date, all_actions): actions = get_actions(start_date, end_date, all_actions) actions = actions[['user_id', 'cate', 'type']] df = pd.get_dummies(actions['type'], prefix='type') actions = pd.concat([actions[['user_id', 'cate']], df], axis=1) actions = actions.groupby(['user_id', 'cate']).sum() actions = actions.unstack() actions.columns = actions.columns.swaplevel(0, 1) actions.columns = actions.columns.droplevel() actions.columns = [ 'cate_4_type1', 'cate_5_type1', 'cate_6_type1', 'cate_7_type1', 'cate_8_type1', 'cate_9_type1', 'cate_10_type1', 'cate_11_type1', 'cate_4_type2', 'cate_5_type2', 'cate_6_type2', 'cate_7_type2', 'cate_8_type2', 'cate_9_type2', 'cate_10_type2', 'cate_11_type2', 'cate_4_type3', 'cate_5_type3', 'cate_6_type3', 'cate_7_type3', 'cate_8_type3', 'cate_9_type3', 'cate_10_type3', 'cate_11_type3', 'cate_4_type4', 'cate_5_type4', 'cate_6_type4', 'cate_7_type4', 'cate_8_type4', 'cate_9_type4', 'cate_10_type4', 'cate_11_type4', 'cate_4_type5', 'cate_5_type5', 'cate_6_type5', 'cate_7_type5', 'cate_8_type5', 'cate_9_type5', 'cate_10_type5', 'cate_11_type5', 'cate_4_type6', 'cate_5_type6', 'cate_6_type6', 'cate_7_type6', 'cate_8_type6', 'cate_9_type6', 'cate_10_type6', 'cate_11_type6' ] actions = actions.fillna(0) actions['cate_action_sum'] = actions.sum(axis=1) actions['cate8_percentage'] = ( actions['cate_8_type1'] + actions['cate_8_type2'] + actions['cate_8_type3'] + actions['cate_8_type4'] + actions['cate_8_type5'] + actions['cate_8_type6'] ) / actions['cate_action_sum'] actions['cate4_percentage'] = ( actions['cate_4_type1'] + actions['cate_4_type2'] + actions['cate_4_type3'] + actions['cate_4_type4'] + actions['cate_4_type5'] + actions['cate_4_type6'] ) / actions['cate_action_sum'] actions['cate5_percentage'] = ( actions['cate_5_type1'] + actions['cate_5_type2'] + actions['cate_5_type3'] + actions['cate_5_type4'] + actions['cate_5_type5'] + actions['cate_5_type6'] ) / actions['cate_action_sum'] actions['cate6_percentage'] = ( actions['cate_6_type1'] + actions['cate_6_type2'] + actions['cate_6_type3'] + actions['cate_6_type4'] + actions['cate_6_type5'] + actions['cate_6_type6'] ) / actions['cate_action_sum'] actions['cate7_percentage'] = ( actions['cate_7_type1'] + actions['cate_7_type2'] + actions['cate_7_type3'] + actions['cate_7_type4'] + actions['cate_7_type5'] + actions['cate_7_type6'] ) / actions['cate_action_sum'] actions['cate9_percentage'] = ( actions['cate_9_type1'] + actions['cate_9_type2'] + actions['cate_9_type3'] + actions['cate_9_type4'] + actions['cate_9_type5'] + actions['cate_9_type6'] ) / actions['cate_action_sum'] actions['cate10_percentage'] = ( actions['cate_10_type1'] + actions['cate_10_type2'] + actions['cate_10_type3'] + actions['cate_10_type4'] + actions['cate_10_type5'] + actions['cate_10_type6'] ) / actions['cate_action_sum'] actions['cate11_percentage'] = ( actions['cate_11_type1'] + actions['cate_11_type2'] + actions['cate_11_type3'] + actions['cate_11_type4'] + actions['cate_11_type5'] + actions['cate_11_type6'] ) / actions['cate_action_sum'] actions['cate8_type1_percentage'] = np.log( 1 + actions['cate_8_type1']) - np.log( 1 + actions['cate_8_type1'] + actions['cate_4_type1'] + actions['cate_5_type1'] + actions['cate_6_type1'] + actions['cate_7_type1'] + actions['cate_9_type1'] + actions['cate_10_type1'] + actions['cate_11_type1']) actions['cate8_type2_percentage'] = np.log( 1 + actions['cate_8_type2']) - np.log( 1 + actions['cate_8_type2'] + actions['cate_4_type2'] + actions['cate_5_type2'] + actions['cate_6_type2'] + actions['cate_7_type2'] + actions['cate_9_type2'] + actions['cate_10_type2'] + actions['cate_11_type2']) actions['cate8_type3_percentage'] = np.log( 1 + actions['cate_8_type3']) - np.log( 1 + actions['cate_8_type3'] + actions['cate_4_type3'] + actions['cate_5_type3'] + actions['cate_6_type3'] + actions['cate_7_type3'] + actions['cate_9_type3'] + actions['cate_10_type3'] + actions['cate_11_type3']) actions['cate8_type4_percentage'] = np.log( 1 + actions['cate_8_type4']) - np.log( 1 + actions['cate_8_type4'] + actions['cate_4_type4'] + actions['cate_5_type4'] + actions['cate_6_type4'] + actions['cate_7_type4'] + actions['cate_9_type4'] + actions['cate_10_type4'] + actions['cate_11_type4']) actions['cate8_type5_percentage'] = np.log( 1 + actions['cate_8_type5']) - np.log( 1 + actions['cate_8_type5'] + actions['cate_4_type5'] + actions['cate_5_type5'] + actions['cate_6_type5'] + actions['cate_7_type5'] + actions['cate_9_type5'] + actions['cate_10_type5'] + actions['cate_11_type5']) actions['cate8_type6_percentage'] = np.log( 1 + actions['cate_8_type6']) - np.log( 1 + actions['cate_8_type6'] + actions['cate_4_type6'] + actions['cate_5_type6'] + actions['cate_6_type6'] + actions['cate_7_type6'] + actions['cate_9_type6'] + actions['cate_10_type6'] + actions['cate_11_type6']) actions['user_id'] = actions.index actions = actions[[ 'user_id', 'cate8_percentage', 'cate4_percentage', 'cate5_percentage', 'cate6_percentage', 'cate7_percentage', 'cate9_percentage', 'cate10_percentage', 'cate11_percentage', 'cate8_type1_percentage', 'cate8_type2_percentage', 'cate8_type3_percentage', 'cate8_type4_percentage', 'cate8_type5_percentage', 'cate8_type6_percentage' ]] return actions
train_start_date = '2016-02-01' train_end_date = datetime.strptime(train_start_date, '%Y-%m-%d') + timedelta(days=3) train_end_date = train_end_date.strftime('%Y-%m-%d') day = 3 start_date = datetime.strptime(train_end_date, '%Y-%m-%d') - timedelta(days=day) start_date = start_date.strftime('%Y-%m-%d') print (start_date) print (train_end_date)
2016-02-01 2016-02-04
actions = get_actions(start_date, train_end_date, all_actions) actions = actions[['user_id', 'cate', 'type']] actions.head()

df = pd.get_dummies(actions['type'], prefix='type') actions = pd.concat([actions[['user_id', 'cate']], df], axis=1) actions = actions.groupby(['user_id', 'cate']).sum() actions.head()

actions = actions.unstack()
actions.head()

actions.columns
actions.columns = actions.columns.swaplevel(0, 1)
actions.columns
actions.columns = actions.columns.droplevel()
actions.columns
Index(['type_1.0', 'type_1.0', 'type_1.0', 'type_1.0', 'type_1.0', 'type_1.0',
'type_1.0', 'type_1.0', 'type_2.0', 'type_2.0', 'type_2.0', 'type_2.0',
'type_2.0', 'type_2.0', 'type_2.0', 'type_2.0', 'type_3.0', 'type_3.0',
'type_3.0', 'type_3.0', 'type_3.0', 'type_3.0', 'type_3.0', 'type_3.0',
'type_4.0', 'type_4.0', 'type_4.0', 'type_4.0', 'type_4.0', 'type_4.0',
'type_4.0', 'type_4.0', 'type_5.0', 'type_5.0', 'type_5.0', 'type_5.0',
'type_5.0', 'type_5.0', 'type_5.0', 'type_5.0', 'type_6.0', 'type_6.0',
'type_6.0', 'type_6.0', 'type_6.0', 'type_6.0', 'type_6.0', 'type_6.0'],
dtype='object')
actions.columns = [ 'cate_4_type1', 'cate_5_type1', 'cate_6_type1', 'cate_7_type1', 'cate_8_type1', 'cate_9_type1', 'cate_10_type1', 'cate_11_type1', 'cate_4_type2', 'cate_5_type2', 'cate_6_type2', 'cate_7_type2', 'cate_8_type2', 'cate_9_type2', 'cate_10_type2', 'cate_11_type2', 'cate_4_type3', 'cate_5_type3', 'cate_6_type3', 'cate_7_type3', 'cate_8_type3', 'cate_9_type3', 'cate_10_type3', 'cate_11_type3', 'cate_4_type4', 'cate_5_type4', 'cate_6_type4', 'cate_7_type4', 'cate_8_type4', 'cate_9_type4', 'cate_10_type4', 'cate_11_type4', 'cate_4_type5', 'cate_5_type5', 'cate_6_type5', 'cate_7_type5', 'cate_8_type5', 'cate_9_type5', 'cate_10_type5', 'cate_11_type5', 'cate_4_type6', 'cate_5_type6', 'cate_6_type6', 'cate_7_type6', 'cate_8_type6', 'cate_9_type6', 'cate_10_type6', 'cate_11_type6' ] actions.columns
Index(['cate_4_type1', 'cate_5_type1', 'cate_6_type1', 'cate_7_type1',
'cate_8_type1', 'cate_9_type1', 'cate_10_type1', 'cate_11_type1',
'cate_4_type2', 'cate_5_type2', 'cate_6_type2', 'cate_7_type2',
'cate_8_type2', 'cate_9_type2', 'cate_10_type2', 'cate_11_type2',
'cate_4_type3', 'cate_5_type3', 'cate_6_type3', 'cate_7_type3',
'cate_8_type3', 'cate_9_type3', 'cate_10_type3', 'cate_11_type3',
'cate_4_type4', 'cate_5_type4', 'cate_6_type4', 'cate_7_type4',
'cate_8_type4', 'cate_9_type4', 'cate_10_type4', 'cate_11_type4',
'cate_4_type5', 'cate_5_type5', 'cate_6_type5', 'cate_7_type5',
'cate_8_type5', 'cate_9_type5', 'cate_10_type5', 'cate_11_type5',
'cate_4_type6', 'cate_5_type6', 'cate_6_type6', 'cate_7_type6',
'cate_8_type6', 'cate_9_type6', 'cate_10_type6', 'cate_11_type6'],
dtype='object')
actions = actions.fillna(0) actions['cate_action_sum'] = actions.sum(axis=1) actions.head()
actions['cate8_percentage'] = ( actions['cate_8_type1'] + actions['cate_8_type2'] + actions['cate_8_type3'] + actions['cate_8_type4'] + actions['cate_8_type5'] + actions['cate_8_type6'] ) / actions['cate_action_sum'] actions.head()
actions['cate8_type1_percentage'] = np.log( 1 + actions['cate_8_type1']) - np.log( 1 + actions['cate_8_type1'] + actions['cate_4_type1'] + actions['cate_5_type1'] + actions['cate_6_type1'] + actions['cate_7_type1'] + actions['cate_9_type1'] + actions['cate_10_type1'] + actions['cate_11_type1']) actions.head()
3.8 累积商品特征
- 分时间段
- 针对商品的不同行为的
- 购买转化率
- 均值
- 标准差
def get_accumulate_product_feat(start_date, end_date, all_actions): feature = [ 'sku_id', 'product_action_1', 'product_action_2', 'product_action_3', 'product_action_4', 'product_action_5', 'product_action_6', 'product_action_1_ratio', 'product_action_2_ratio', 'product_action_3_ratio', 'product_action_5_ratio', 'product_action_6_ratio', 'product_action_1_mean', 'product_action_2_mean', 'product_action_3_mean', 'product_action_4_mean', 'product_action_5_mean', 'product_action_6_mean', 'product_action_1_std', 'product_action_2_std', 'product_action_3_std', 'product_action_4_std', 'product_action_5_std', 'product_action_6_std' ] actions = get_actions(start_date, end_date, all_actions) df = pd.get_dummies(actions['type'], prefix='product_action') # 按照商品-日期分组,计算某个时间段该商品的各项行为的标准差 actions['date'] = pd.to_datetime(actions['time']).apply(lambda x: x.date()) actions = pd.concat([actions[['sku_id', 'date']], df], axis=1) actions = actions.groupby(['sku_id'], as_index=False).sum() days_interal = (datetime.strptime(end_date, '%Y-%m-%d') - datetime.strptime(start_date, '%Y-%m-%d')).days actions['product_action_1_ratio'] = np.log(1 + actions['product_action_4.0']) - np.log(1 + actions['product_action_1.0']) actions['product_action_2_ratio'] = np.log(1 + actions['product_action_4.0']) - np.log(1 + actions['product_action_2.0']) actions['product_action_3_ratio'] = np.log(1 + actions['product_action_4.0']) - np.log(1 + actions['product_action_3.0']) actions['product_action_5_ratio'] = np.log(1 + actions['product_action_4.0']) - np.log(1 + actions['product_action_5.0']) actions['product_action_6_ratio'] = np.log(1 + actions['product_action_4.0']) - np.log(1 + actions['product_action_6.0']) # 计算各种行为的均值 actions['product_action_1_mean'] = actions[ 'product_action_1.0'] / days_interal actions['product_action_2_mean'] = actions[ 'product_action_2.0'] / days_interal actions['product_action_3_mean'] = actions[ 'product_action_3.0'] / days_interal actions['product_action_4_mean'] = actions[ 'product_action_4.0'] / days_interal actions['product_action_5_mean'] = actions[ 'product_action_5.0'] / days_interal actions['product_action_6_mean'] = actions[ 'product_action_6.0'] / days_interal #actions = pd.merge(actions, actions_date, how='left', on='sku_id') #actions = actions[feature] return actions
train_start_date = '2016-02-01' train_end_date = datetime.strptime(train_start_date, '%Y-%m-%d') + timedelta(days=3) train_end_date = train_end_date.strftime('%Y-%m-%d') day = 3 start_date = datetime.strptime(train_end_date, '%Y-%m-%d') - timedelta(days=day) start_date = start_date.strftime('%Y-%m-%d') print (start_date) print (train_end_date)
2016-02-01 2016-02-04
actions = get_actions(start_date, train_end_date, all_actions) df = pd.get_dummies(actions['type'], prefix='product_action') actions['date'] = pd.to_datetime(actions['time']).apply(lambda x: x.date()) actions = pd.concat([actions[['sku_id', 'date']], df], axis=1) actions.head()

actions = actions.groupby(['sku_id'], as_index=False).sum() actions.head()

days_interal = (datetime.strptime(train_end_date, '%Y-%m-%d') - datetime.strptime(start_date, '%Y-%m-%d')).days days_interal
3
actions['product_action_1_ratio'] = np.log(1 + actions['product_action_4.0']) - np.log(1 + actions['product_action_1.0']) actions.head()

3.9 类别特征
分时间段下各个商品类别的
- 购买转化率
- 标准差
- 均值
def get_accumulate_cate_feat(start_date, end_date, all_actions): feature = ['cate','cate_action_1', 'cate_action_2', 'cate_action_3', 'cate_action_4', 'cate_action_5', 'cate_action_6', 'cate_action_1_ratio', 'cate_action_2_ratio', 'cate_action_3_ratio', 'cate_action_5_ratio', 'cate_action_6_ratio', 'cate_action_1_mean', 'cate_action_2_mean', 'cate_action_3_mean', 'cate_action_4_mean', 'cate_action_5_mean', 'cate_action_6_mean', 'cate_action_1_std', 'cate_action_2_std', 'cate_action_3_std', 'cate_action_4_std', 'cate_action_5_std', 'cate_action_6_std'] actions = get_actions(start_date, end_date, all_actions) actions['date'] = pd.to_datetime(actions['time']).apply(lambda x: x.date()) df = pd.get_dummies(actions['type'], prefix='cate_action') actions = pd.concat([actions[['cate','date']], df], axis=1) # 按照类别分组,统计各个商品类别下行为的转化率 actions = actions.groupby(['cate'], as_index=False).sum() days_interal = (datetime.strptime(end_date, '%Y-%m-%d')-datetime.strptime(start_date, '%Y-%m-%d')).days actions['cate_action_1_ratio'] =(np.log(1 + actions['cate_action_4.0']) - np.log(1 + actions['cate_action_1.0'])) actions['cate_action_2_ratio'] =(np.log(1 + actions['cate_action_4.0']) - np.log(1 + actions['cate_action_2.0'])) actions['cate_action_3_ratio'] =(np.log(1 + actions['cate_action_4.0']) - np.log(1 + actions['cate_action_3.0'])) actions['cate_action_5_ratio'] =(np.log(1 + actions['cate_action_4.0']) - np.log(1 + actions['cate_action_5.0'])) actions['cate_action_6_ratio'] =(np.log(1 + actions['cate_action_4.0']) - np.log(1 + actions['cate_action_6.0'])) # 按照类别分组,统计各个商品类别下行为在一段时间的均值 actions['cate_action_1_mean'] = actions['cate_action_1.0'] / days_interal actions['cate_action_2_mean'] = actions['cate_action_2.0'] / days_interal actions['cate_action_3_mean'] = actions['cate_action_3.0'] / days_interal actions['cate_action_4_mean'] = actions['cate_action_4.0'] / days_interal actions['cate_action_5_mean'] = actions['cate_action_5.0'] / days_interal actions['cate_action_6_mean'] = actions['cate_action_6.0'] / days_interal #actions = pd.merge(actions, actions_date, how ='left',on='cate') #actions = actions[feature] return actions