交换排序
所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
排序入门之冒泡排序
冒泡排序是典型的交换排序算法。冒泡排序的时间复杂度为O(n2),可以说效率比较低,但是,冒泡排序体现的思想是学习排序算法很好的入门,尤其是对学习快速排序(在冒泡排序基础之上发展起来的)很有帮助。
基本思想
冒泡排序的基本思想是,进行(最多进行)n-1趟冒泡,其中n为数据的个数,其中每次冒泡会将未排序的最大的值移动到未排序序列的末尾,冒泡的方式是从左到有依次两两比较,并将值较大的交换到右侧,将值较小的移动到左侧。这样每趟冒泡都会将一个最大值(未排序的部分)放到正确的位置上。
优化
可以对冒泡排序进行优化:当一趟冒泡过程中,没有发生值交换,说明整个序列已经有序,这个时候我们就退出外层循环,排序结束。
源代码
#include <stdio.h> #include <string.h> #include <stdlib.h> #include <stdbool.h> void bubble_sort(int value[],int n) { int i = 0; for(;i < n - 1;i++)//n-1趟 { int j = 0; bool tag = false; for(;j < n-i-1;j++)//依次进行两两比较 { if(value[j] > value[j+1]) { tag = true;//存在交换 int temp = value[j]; value[j] = value[j + 1]; value[j + 1] = temp; } } if(!tag)//不存在交换,说明已经有序,退出循环 break; } printf("进行了%d趟排序 ",i); } int main() { int value[] = {8,6,3,7,4,5,1,2,10,9}; int n = 10; bubble_sort(value,n); printf("排序结果为: "); int i = 0; for(;i < n;i++) { printf("%d ",value[i]); } printf(" "); return 0; }
快速排序
对于包含n个数的输入数组来说,快速排序是一种最坏情况时间复杂度为O(n2)的排序算法。虽然最坏情况时间复杂度很差,但是快排序通常是实际排序应用中最好的选择,因为它的平均性能非常好,它的期望时间复杂度是O(nlgn),而且常量因子非常小。
快速排序是实际中最常用的一种排序算法,速度快,效率高。就像名字一样,快速排序是最优秀的一种排序算法。
基本思想
快速排序的思想是典型的分治思想,而分治思想大多和递归是分不开的。
分治思想的重要三个步骤是,分解、解决、合并
分解:
将原问题分解成若干子问题,这些子问题是原问题的规模较小的实例。
解决:
递归地求解这些子问题,如果子问题的规模较小,则直接求解。
合并:
合并这些子问题的解以求得原问题的解。
具体到快速排序算法上,分治思想是这样体现的。
分解:
将数组 A[p…r]划分成两个子数组A[p….q-1]和A[q+1….r],其中A[p….q-1]中的元素都不大于A[q],A[q+1….r]中的元素都不小于A[q].
解决:
通过递归调用快速排序,对子数组A[p….q-1]和A[q+1….r]进行排序,当子数组为空,或者只有一个元素的时候,就不需要再递归解决了(这就是问题规模足够小的时候,直接解决)
合并:
由于子数组都是原地址排序,所以子数组有序后,原数组就有序了,不需要额外的合并处理了。
具体细节
从上面快速排序的分治思想三个步骤来看,最关键的就是第一步分解了,而分解中最关键的就是确定q了。下面我们来仔细说说如何确定q。
确定q的方法是这样的:
首先找一个主元(pivot element),然后设置两个哨兵,哨兵i和哨兵j,哨兵i指向首元素,j指向尾元素,哨兵j从后往前,哨兵i从前往后。我们要达到的目的是这样的:比主元大的元素都在主元的后面,比主元小的元素都在主元的前面。为了达到这个目的,我们首先比较pivot和A[j]的大小,如果A[j]大于pivot,那么A[j]不必移动,这时候哨兵j向前移动,也就是j--,知道找到A[j]小于pivot,停下来。然后比较pivot和A[i],同样,找到A[i]大于pivot停下来(不过i是向后移动),然后交换此时的A[i]和A[j],这样大的值就到后面去了,小的值就到前面去了。然后重复这个过程,直到两个哨兵相遇,也就是i=j。你可能会问:为什么是从j开始,而不是从i开始呢?这和你选择的pivot的位置有关系,其实从i和j开始都是可以的,不过分情况看,其中一种会简化步骤。这个我们后面再讨论。最后i=j后,还要安排pivot的位置,至于怎么安排我们后面讲。
实例解析如何确定q(也就是比A[p…q-1]中元素都大,比A[q+1…r]中元素都小的那个值的下标)
下面我们通过一个实例来讲解如何找到q
有这样一个序列:

1、 假设我们选择的pivot是8,pivot这个东西是随便选的(也不是,一个坏的pivot会影响快速排序的效率,不过那是后话,是优化的问题了)。之所以选择8,是因为选在两端处理起来比较容易(后面会讲为什么,也会随便选一个pivot)。
哨兵i指向8,j指向9,如下图
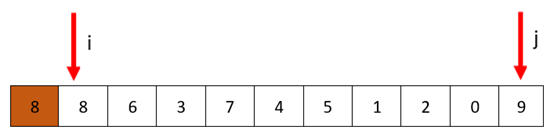
2、 然后,我们先j开始,从后往前,找到比8小的值停下,也就是j停在0的位置(至于为什么先从j开始,后面再讲)
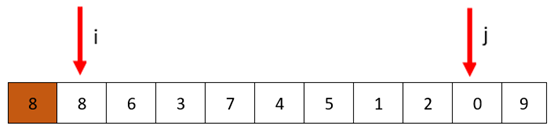
3、 然后我们再从i开始,找到比8大的值停下,我们发现知道i=j也没发现比8大的值,前面我们也说过,哨兵相遇的时候要终止,所以有
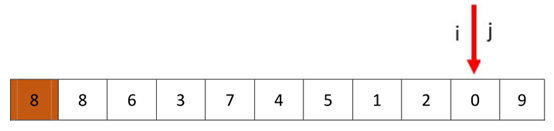
本来是要有i和j的值进行交换的,然后要重复执行2,3过程,直到i=j,因为我这个序列选的不是特别好,第一次就到i=j了(没关系,后面我们会随机选择一个pivot),这个时候我们要退出循环,然后安排pivot的位置。对于这种pivot选择在最左边,而且先从j开始的情况,直接交换8和i处的值(也是j处的值),然后返回i,就是我们所要求的q。分解成的两个子数组就是[0,6,3,7,4,5,1,2]和[9]。然后再对这两个数组递归排序。

注意,直接交换的前提是,pivot选择了最左侧的值,而且每一次是从后端(j端)开始。不同的pivot选择方式、从i开始还是从j开始会影响最后pivot的分配方式。下面我们分几种情况看。
上面我们从j端开始,那么下面我们从i开始会看看会怎样。
首先我们依然选择最左端的8为pivot,i指向最左端,j指向最右端,如图

然后我们从左端开始(i)开始,一直向后,直到找到大于8的值,最后找到了9,这是i和j也相遇了。
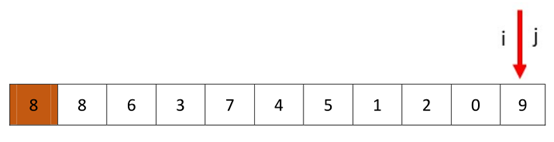
哨兵相遇后,我们要分配pivot,在上一种情况下,我们是直接交换了i处的值和8,但是这次我们如果直接交换i处的值,然后返回i作为我们所求得的q,结果就是错误的。

那么正确的做法是怎样的呢?应该是交换9左边的0和pivot,也就是交换0和8
为什么会造成这种结果呢?前面说过,最后pivot的分配问题,与两点有关,一是pivot的选择方式,二是从i端还是从j端开始的。Pivot选择在最左端,我们要注意最左端这个位置很特殊,特殊之处就在于:这个位置最终一定是要放置比pivot小的值,除非A[p…q+1]这个子数组为空(此时该处就应该放置pivot),想想看是不是这样。那么先从i开始和先从j开始又有什么区别呢?我们要注意从i开始是找大于pivot的值然后停下,而从j开始是找小于pivot的值然后停下来,所以如果先从i开始,当i和j相遇时,相遇处的值一定是大于pivot的(就像9)。相反,如果从j开始,相遇处的值一定是小于pivot的(比如第一种情况的0)。当相遇处的值小于pivot时,直接交换pivot和相遇处的值即可。但是如果相遇处的值大于pivot时,这个时候不能直接交换,直接交换就不满足条件了,应该交换pivot和相遇处前一位的值。
接下来,我们选择一个不在最左端的pivot,比如我们选择4。
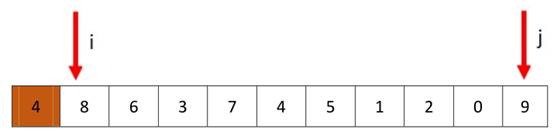
这次我们选择先从i开始,向后找到比4大的值然后停下,停在了8处。然后从j开始,向前找到比4小的值,停在了0处。
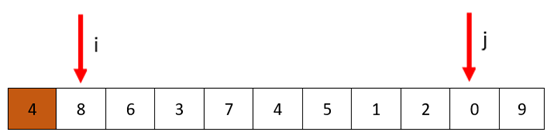
交换i处和j处的值
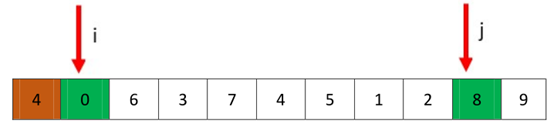
然后开始下一轮,即再次从i开始找到比4大的数,停下,停在了6处;然后从j开始向前找比4小的数,停在了2处.

交换i处和j处的值。
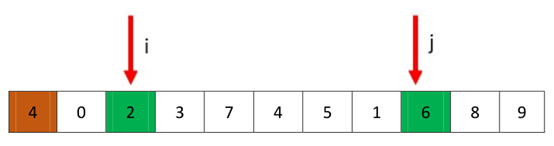
接着开始下一轮,从i开始,停在了7处,从j开始停在了1处
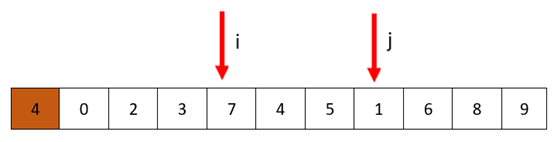
交换i和j处的值
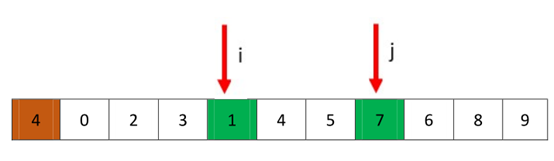
然后开始下一轮,从i处向后,停在了5处,然后从j开始找小于4的值,当到5处时,j和i相遇。相遇了我们就要分配pivot的值
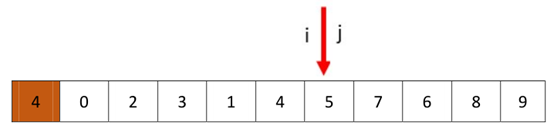
我们发现相遇处的值5比pivot(4)要大,所以这个时候我们要交换4和5前面一位(也就是4)的值,这个整好(巧了)pivot就是5的前一位,所以不用交换。然后我们返回i-1,就是我们求得的q。分解成的两个数组就是[0,2,3,1]和[5,7,6,8,9]
我们就一直写下去吧,我们先对[0,2,3,1]求解
为了最后分配pivot简单,我们就选最左侧的值为pivot,然后每次都从j开始。
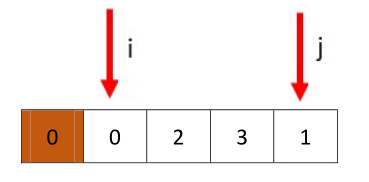
从j开始向前,找小于0的值,停在了0处,和i相遇,交换相遇处的值(0)和pivot(0)(是同一个)
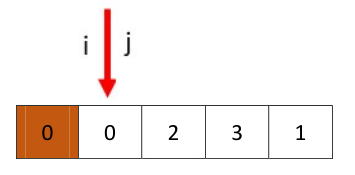
返回i的值,就是我们求得的q,两个子数组为,[]和[2,3,1]
然后我们处理[2,3,1]
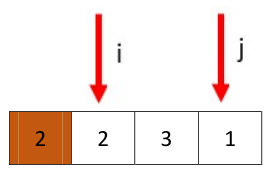
从j开始,停在1处,再从i开始停在3处
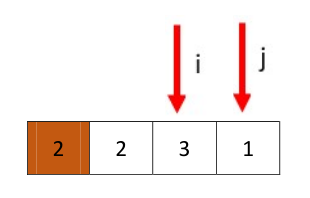
值交换
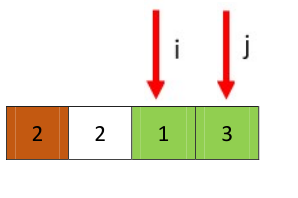
然后开始新一轮,从j开始,遇到了i停下,分配pivot
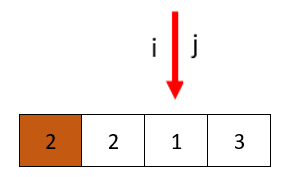
交换pivot和i处的值
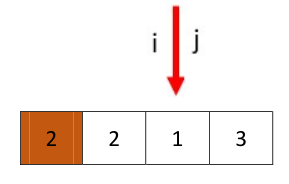
返回i,就是求得的q,两个数组为[1]和[3],都只有一个值结束。
回过头来,我们解决[7,6,8,9]
相信你早已经明白了,,,,,不写了。。。。。
最后给出代码
#include <stdio.h> #include <stdlib.h> int partition(int value[], int start, int end) { int pivot = value[start];//pivot选择最左端的值 int i = start; int j = end; while(i != j) { if(value[j] >= pivot )//先从j开始 { j--; continue; } if(value[i] <= pivot) { i++; continue; } //交换i处和j处的值 int temp = value[i]; value[i] = value[j]; value[j] = temp; } //交换pivot和相遇处的值 int temp = value[start]; value[start] = value[i]; value[i] = temp; //返回相遇处的下标 return i; } void quick_sort(int value[],int start,int end) { if(end - start + 1 <= 1)//当数组为空或只有一个元素时,不用排序了 return; int q = partition(value,start,end);//找到q //递归求解分解成的两个子数组 quick_sort(value,start,q-1); quick_sort(value,q+1,end); } int main() { int value[] = {8,6,3,7,4,5,1,2,0,9}; int n = 10; quick_sort(value,0,9); printf("排序结果为: "); int i = 0; for(;i < n;i++) { printf("%d ",value[i]); } printf(" "); return 0; }
10月10日更新
一个思路比较清晰,简洁的代码
#include <stdio.h> #include <stdlib.h> int partition(int value[], int start, int end) { int i = start; int j = end; int pivot = value[start]; while(i < j) { while(i < j && value[j] >= pivot) { j--; } if(i < j) { value[i] = value[j];//将小值移动到低处 i++;//别忘了 } while(i < j && value[i] <= pivot) { i++; } if(i < j) { value[j] = value[i];//将大值移动到高处 j--;//别忘了 } } value[i] = pivot;//将中值移动到相遇处 return i; } void quick_sort(int value[],int start,int end) { if(start >= end)//递归出口,主义start是有可能大于end的,这个时候,实际上数足为空 return; int q = partition(value,start,end); quick_sort(value,start,q - 1); quick_sort(value,q + 1,end); } int main() { int value[] = {8,6,3,7,4,5,1,2,0,9}; int n = 10; quick_sort(value,0,9); printf("排序结果为: "); int i = 0; for(;i < n;i++) { printf("%d ",value[i]); } printf(" "); return 0; }
最后附上word文档和源代码文件
链接:http://pan.baidu.com/s/1slLkPFf 密码:mnoi
如果你觉得对你有用,请点个赞吧~~~