一、 数据库的介绍
二、 MySQL的基本语法
l 注释:
单行注释: #注释内容
单行注释: -- 注释内容(注意,两个“--”之后有一个空格)
多行注释: /*注释内容*/
l 语句行:
一条语句也称为一条命令,通常用一个分号(;)结束;也可以通过"delimiter 新结束符" 命令来设定新的结束符。
语句的执行是以一条语句为单位进行,一次执行一条语句。
l 大小写:show databases; SHOW DATABASES;
mysql中的各种系统关键字和命令名本身是不区分大小写的
mysql中自定义的名称(标识符)的大小写问题,有的区分(跟操作系统有关),有的不区分,详见如下“命名规则”;
Windows是不区分的。Linux 是区分的。
l 命名(标识符)规则:
可以自己命名的名字,称为标识符,包括:数据库名, 表名,字段名,视图名,函数名,过程名,变量名,用户名,,等等。
可以命名标识符的字符比常规的语言多,但特别建议只用:字母数字和下划线,并不用数字开头。
非常规字符或系统关键字虽然可以作为标识符使用,但最好要包在反引号(数字1左边那个反撇 ` )中,并且不推荐。
对数据库名,表名,和视图名,在window系统中不区分大小写,而其他系统中区分,建议全使用小写,并采用下划线分割法。
对其他自己命名的标识符(字段名,函数名,过程名),不区分大小写,但也建议全使用小写,并采用下划线分割法
三、 库操作
SQL语句的分类
分四类
(1)ddl 语句(数据定义语句) create alter
(2)dml语句(数据操作语句) update insert delete
(3)dql语句(数据查询语句) select
(4)dcl语句(数据控制语句) 在数据库事务和 mysql 用户管理的时候,grant revoke commit rollback savepoint 等
1.创建数据库
语句:CREATE DATABASE [IF NOT EXISTS] dbname 字符集;
库选项:字符集、校对集
CREATE DATABASE PHP07 charset utf8; CREATE DATABASE 中国你好; CREATE DATABASE `DBNAME` charset utf8;


utf8_general_ci 不区分大小写
show character set 查询字符集
show collation 排序和校对规则
2.查询所有数据库
语句:show databases;

3.查询数据库创建语句
语句:show create database 数据库名;

4.查看当前 mysql 数据库的连接进程情况
show database processlist;

5.修改数据库
说明:不能修改数据库名称,只能修改字符集和校对集
语句:alter database 数据库名 charset=新字符集 collate=新的校对集
注意:字符集和校对集是可以分开修改的,但是建议必须一起修改
查看校对集:show collation; 查看字符集:show charset;


5.删除数据库
语句:drop database 数据库名;

6.选择数据库
语句:use 数据库名;
7.数据库备份,恢复数据库
7.1基本语法:cmd>mysqldump -u root -p 数据库>数据存放路径
>mysqldump -u root -p demodb > d:/demodb.bak;
7.2如何备份demodb数据库中的table1,table2表
>mysqldump -u root -p demodb table1 table2 > d:/demodb.bak;
7.3如何同时备份多个数据库
>mysqldump -u root -p -B demodb eblog > d:/demodb.bak;
四、 表操作
1.创建表
语句:
Create table 表名(
字段名称1 字段属性(类型) 字段选项,
字段名称2 字段类型 字段选项,
..........................
)表选项;
表选项:表字符集和数据引擎
字符集:charset=utf8;
数据引擎:默认innodb,语法:engine=引擎
什么是存储引擎?存储引擎也叫“表类型”,是指一个表中的数据以何种方式存放在文件或内存中。不同的存储引擎(表类型)提供不同的性能特性和可用功能。没有一种各方面都又具有最佳性能又具有各种功能的存储引擎。我们要做的是要根据数据的具体使用情形(需求)来选择合适的存储引擎,有的要读取速度快,有的要写入速度快,有的要具有高安全可靠性,有的要海量存储,等等。常用的存储引擎是innoDB(默认)和Myisam。

字段:当前表中的数据的数据名称,自定义就可以了,但是使用单词。
字段类型:当前字段中存储数据类型必须是一开始指定好。
字段选项:设置当前字段的一些选项-是否可以为空,是否是主键,是否是唯一键,是否加备注等。
Null|not null:是否可以为空
Default:是否有默认值
Auto_increment:是否可以自动增长,必须是数字,如:需要给每条数据一个编号,原因是数据内容可以重复,编号不能重复。
Primary key:设置主键,数据内容不能重复,在查询数据主查询条件,一个表中一个主键,一般都是id。
unique [key]:设定为唯一(键),即表中所有行的的数据在该字段中的值不能有重复。
Comment:设置备注,给当前字段设置说明

l 字段类型:字符串、日期时间、数值

数值型:存储的数值大小不一样,默认是有符号的,无符号:unsigned
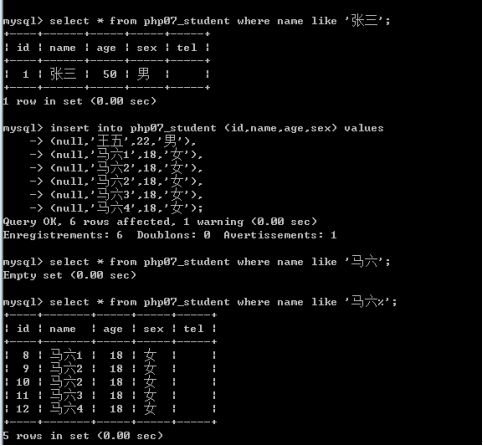
整数:tinyint、smallint、int


小数:float、decimal
float,范围大约是-3.4E+38到-1.1E-38、0和1.1E-38到3.4E+38
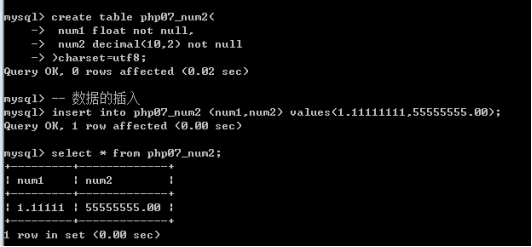
Decimal:定点型
Decimal(10,2):长度10位,其中小数2位。55555555.00,价格。
字符串:
Char:最大255 Varchar:65532 Text:无限制
Char和varchar的区别:定长型和变长型
Char:定长型,固定的长度,如:char(30),最大存储30的长度,如果没有写如30长度的数据,其他位置用空格补齐。
Varchar:变长型,可以变化长度,如:varchar(30),最大存储30的长度,如果没有写入30的长度,写入多占多少位置。

日期时间:
date类型: 支持的范围为'1000-01-01'到'9999-12-31'
datetime类型:支持的范围是'1000-01-01 00:00:00'到'9999-12-31 23:59:59'
2.删除表
语句:drop table 表名;

3.查看表
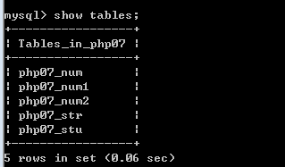
查看所有表:show tables;
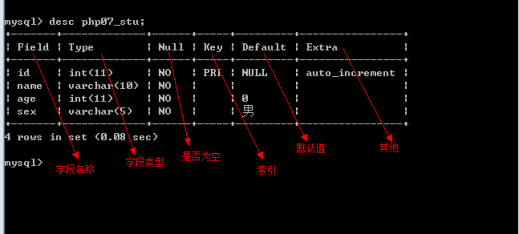
查看表结构:desc 表名;
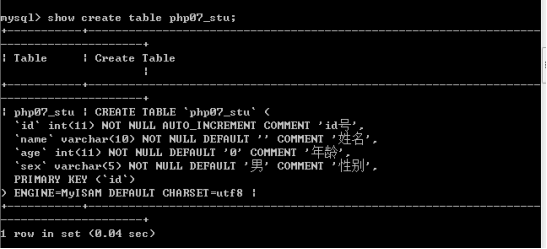
查看创建表语句:show create table 表名;
4.修改表
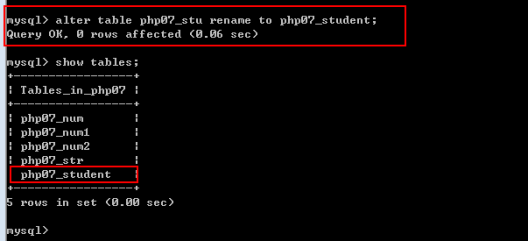
修改表名:alter table 旧表名 rename [to] 新表名;
添加新字段:alter table 表名 add 新字段 字段类型 字段选项;
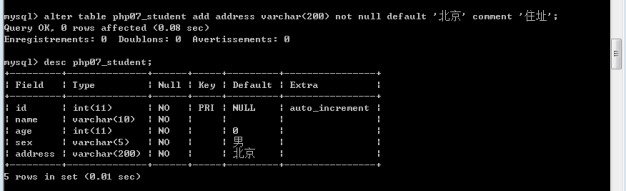
修改表字段(包括字段名):
Alter table 表名 change 旧字段名 新字段名 新字段类型 新字段选项;
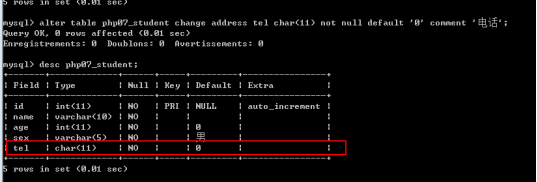
修改字段类型和选项:
Alter table 表名 modify 字段名 新字段类型 新字段选项;

删除字段:alter table 表名 drop 字段名;

数据库设计原则——也称为数据库设计三范式(3NF):
第一范式(1NF):原子性,数据不可再分:一个表中的数据(字段值)不可再分。我们来看一个不良做法:范式1,再来看修正后的做法:范式1
第二范式(2NF):唯一性,消除部分依赖:一个表中的每一行必须唯一可区分,且非主键字段值完全依赖主键字段值。也可说,必须消除在一个表中的的非主键字段值仅仅依赖于部分主键值的情形。显然这个要求只对有联合主键的表才有可能违反情况的,而对单字段主键的表是不会出现的。不良做法:范式2,修正之后:范式2
第三范式(3NF):独立性,消除传递依赖:使一个表中的任何一个非主键,完全独立地依赖于主键,而不能又依赖于另外的非主键。如果一个表中的一个非主键字段(B)依赖于另一个非主键字段(A),因为A作为非主键字段,自然是依赖于主键字段的(范式2所决定),则此时就会出现传递依赖:(主键)->(A)->(B)。第三范式就是要消除(或避免)这种依赖。通常的实际做法中,我们只要注意做到“一个表存储一种数据”就可以符合第三范式。不良做法:范式3,修正之后:范式3
五、 数据的操作
1.插入数据
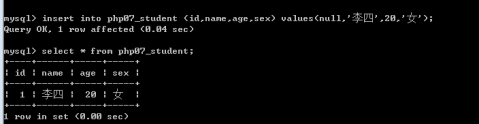
语句:insert into 表名 【(字段1,字段2,字段3,.....)】 values(值1,值2,值3,......);
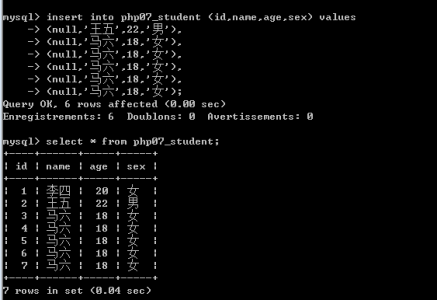
一次性插入多行数据
Insert into 表名 [(字段列表)] values (第一条数据),(第二条数据),......;
字段列表可以省略:省略后的数据必须对应上创建时字段顺序,-php必须是这样
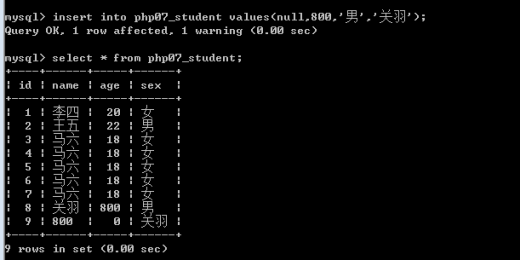
字段列表可以选择性的写:写几个后面的数据必须是一一对应。
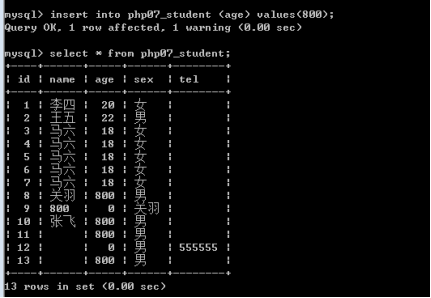
2.删除数据
语句:delete from 表名 where条件 [order排序] [limit限定];
Where条件必须添加,否则删除所有数据,建议id,原因id唯一性
删除大范围的数据。
Order:当前表倒序还是正序,不用添加,默认就可以了
Limit:限定范围,不同添加。
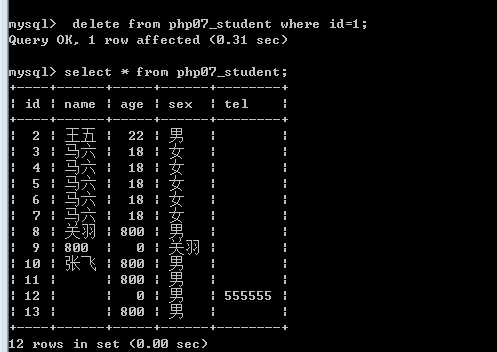

普通删除后保留删除的id号,不再让数据占用。
truncate语句:truncate [table] 表名;用于直接删除整个表(结构)并重新创建该表。

3.修改数据
语句:update 表名 set 字段名1=值表达式1,字段名2=值表达式2,....where条件 ;
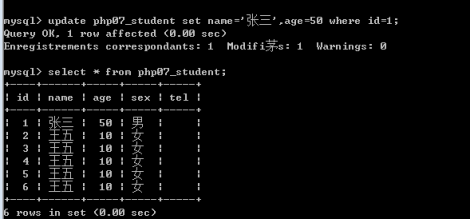
4.查询数据
查询数据只有两种结果:真(有数据)或假(没有数据)
语句:select 字段列表 [from子句] 表名 [where子句] [group by子句] [having子句] [order by子句] [limit子句];
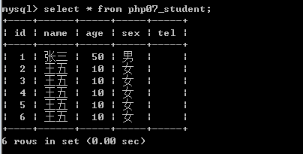
基础查询--查询所有数据及字段
Select * from 表名;
*:所有字段名称。
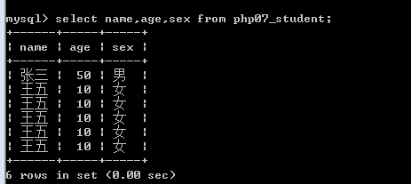
基础查询-查询某些字段
Select name,age,sex,........ from 表名;
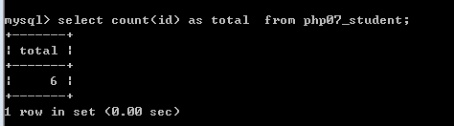
基础查询--别名--小名
如:查询数据的数据量,用count函数
字段名 as 别名
From字句:表示从哪个(或哪些)表中取得数据。
Where字句:给条件的查询
算数运算符:+ - * / %
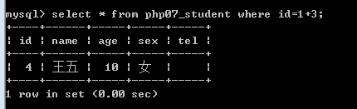
比较运算符:> < >= <= = !=

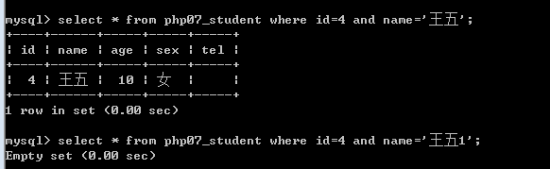
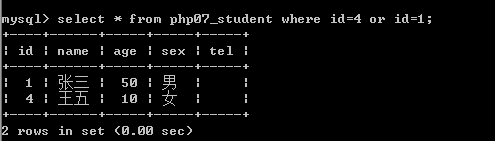
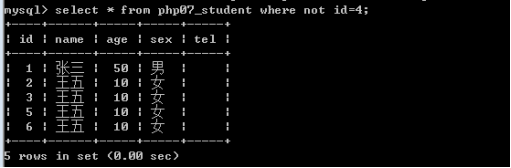
逻辑运算符:与(and)或(or)非(not)
含义和用法同其他编程语言(只是不用那几个符号,而是用单词)。
In :单独查询某些数据
字段名 in(值1,值2,...)
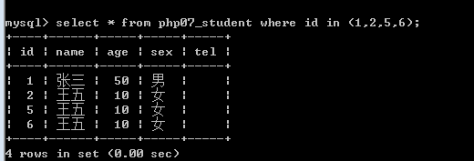
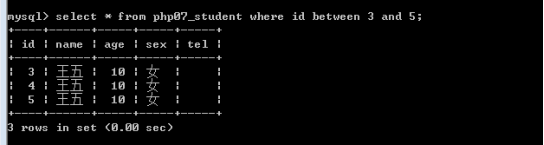
between语法:字段名 between 小值 and 大值(表示该字段的值在给定的两个值之间,含该俩值)
Like:模糊查询
字段名 like ‘要查询的字符’; 如果是直接写字符,配置查询字符必须一致。
字段名 like ‘%要查询的字符%’; %是匹配任何字符