监控的工具---top

第一行:
- 03:07:27 当前系统时间
- 3 days, 18:58 系统已经运行了3天18小时58分钟(在这期间没有重启过)
- 4 users
- load average: 0.00, 0.00, 0.00
Load这个东西怎么理解呢,就像一条马路,有N个车道,如果N个进程进入车道,那么正好一人一个,再多一辆车就占不到车道,要等有一个车空出车道。 在CPU中可以理解为CPU可以并行处理的任务数,那么就是“CPU个数 * 核数”,如果CPU Load = CPU个数 * 核数 那么就是说CPU正好满负载,再多一点,可能就要出问题了,有任务不能被及时分配处理器,那么保证性能的话,最好是小于CPU个数 * 核数 *0.7。
Load Average是 CPU的 Load,它所包含的信息不是 CPU的使用率状况,而是在一段时间内 CPU正在处理以及等待 CPU处理的进程数之和的统计信息,也就是 CPU使用队列的长度的统计信息
Load Average < CPU个数 * 核数 *0.7
使用 vmstat 看到的数据中也有这个数据,vmstat 查看r(Load Average)
第二行:
Tasks 任务(进程),系统现在共有108个进程,其中处于运行中的有2个,105个在休眠(sleep),stoped状态的有1个,zombie状态(僵尸)的有0个。
第三行:CPU状态
- 0.0% us 用户空间占用CPU的百分比。
- 0.0% sy 内核空间占用CPU的百分比。
- 0.0% ni 改变过优先级的进程占用CPU的百分比
- 99.7% id 空闲CPU百分比
- 0.3% wa IO等待占用CPU的百分比
- 0.0% hi 硬中断(Hardware IRQ)占用CPU的百分比
- 0.0% si 软中断(Software Interrupts)占用CPU的百分比
第四行:内存状态
- 1035660k total 物理内存总量(1GB)
- 1025928k used 使用中的内存总量(0.9GB)
- 9732k free 空闲内存总量(9M)
- 37784k buffers 缓存的内存量 (3.5M)
第五行:swap交换分区
- 2048276k total 交换区总量(2GB)
- 52576k used 使用的交换区总量(50M)
- 1995700k free 空闲交换区总量(1.9GB)
- 756448k cached 缓冲的交换区总量(750M)
第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数,空闲内存总量(free)是内核还未纳入其管控范围的数量。纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少。
可用内存的近似计算公式=第四行的free + 第四行的buffers + 第五行的cached
第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第七行以下:各进程(任务)的状态监控
- PID 进程id
- USER 进程所有者
- PR 进程优先级
- NI nice值。负值表示高优先级,正值表示低优先级
- VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
- RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
- SHR 共享内存大小,单位kb
- S 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
- %CPU 上次更新到现在的CPU时间占用百分比
- %MEM 进程使用的物理内存百分比
- TIME+ 进程使用的CPU时间总计,单位1/100秒
- COMMAND 进程名称(命令名/命令行)
按键盘数字1,可监控每个逻辑CPU的状况
监控的工具---vmstat

vmstat--CPU相关参数介绍:
- r,可运行队列的线程数,这些线程都是可运行状态,有多数的进程等待CPU;
- b,被 blocked 的进程数,正在等待 IO 请求;
- in,被处理过的中断数
- cs,系统上正在做上下文切换的数目
- us,用户占用 CPU 的百分比
- sys,内核和中断占用 CPU 的百分比
- wa,所有可运行的线程被 blocked 以后都在等待 IO,这时候 CPU 空闲的百分比
- id,CPU 完全空闲的百分比
vmstat--内存参数说明:
- swpd,已使用的 SWAP 空间大小,KB 为单位;
- free,可用的物理内存大小,KB 为单位;
- buff,物理内存用来缓存读写操作的 buffer 大小,KB 为单位;
- cache,物理内存用来缓存进程地址空间的 cache 大小,KB 为单位;
- si,数据从 SWAP 读取到 RAM(swap in)的大小,KB 为单位;
- so,数据从 RAM 写到 SWAP(swap out)的大小,KB 为单位;
- bi,磁盘块从文件系统或 SWAP 读取到 RAM(blocks in)的大小,block 为单位;
- bo,磁盘块从 RAM 写到文件系统或 SWAP(blocks out)的大小,block 为单位;
不同的系统用途也不同,要找到性能瓶颈需要知道系统跑的是什么应用、有些什么特点,比如 webserver 对系统的要求肯定和 file server 不一样,所以分清不同系统的应用类型很重要,通常应用可以分为两种类型:
看看实际中的例子,第1个是文件服务器拷贝一个大文件时表现出来的特征:
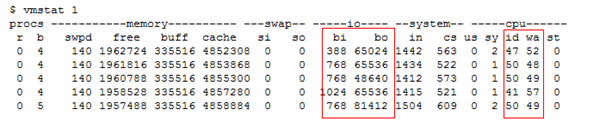
第2个是 CPU 做大量计算时表现出来的特征:

第一个示例:id 在50%左右,说明cpu比较空闲;bi,bo的值较大说明瓶颈在IO上
第二个示例:r为4(= CPU个数 * 核数),id 为0,说明cpu处于繁忙状态;bi,bo的值较小