使用python来刷csdn下载积分(一)中我们实现了csdn下载的自动评价,但是这样只是评价自己下载过的资源,还不能实现刷分的目的。本次,我们将学习批量下载csdn的免费资源。
csdn自己是带了资源的搜素工具的,网址: http://download.csdn.net/advanced_search, 里面是可以搜索指定资源积分的下载资源的。但是用起来非常不好用,总是搜索不到想要的资源。
于是我们就弃之不用,使用百度来搜索,搜索的关键字是 "资源积分:0分" 联通下载 pdf site:download.csdn.net"
这样能得到一大堆的免费资源
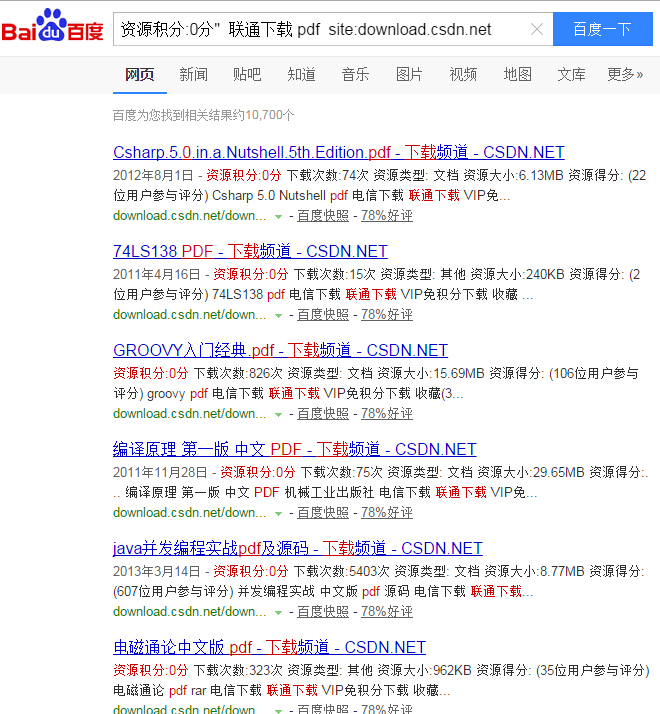
下一步就是解析出每个资源对应的url 去访问并下载。
代码如下:
1 #coding=utf-8 2 import os,time 3 from splinter import Browser 4 from timeout import timeout 5 6 7 def login(username="wojiaoqsc@gmail.com",passwd="dengdengdeng"): 8 """登录csdn""" 9 global browser 10 url = "http://passport.csdn.net/account/login" 11 browser.visit(url) 12 # browser.fill('f', 'splinter - python acceptance testing for web applications') 13 # Find and click the 'search' button 14 btnEmail = browser.find_by_id('username') 15 btnPasswd = browser.find_by_id('password') 16 btnRemember = browser.find_by_name('rememberMe') 17 18 19 btnEmail.fill(username)#用户名 20 btnPasswd.fill(passwd)#密码 21 btnRemember.check()# 22 #print dir(browser) 23 # Interact with elements 24 btnSubmit = browser.find_by_value("登 录") 25 btnSubmit.click()#登录 26 time.sleep(7) 27 # button.click() 28 29 @timeout(30) 30 def download(): 31 global browser 32 33 print "try to clcik" 34 btnDownload = browser.find_by_css(r'#wrap > div.bd.clearfix > div.article > div.information.mb-bg.clearfix > div.info > a.btn.btn-primary.btn-lg.WCDMA.btndownload')[0] 35 btnDownload.click() 36 time.sleep(4) 37 btnDownload = browser.find_by_css(r'#download_btn2')[0] 38 btnDownload.click() 39 # btnDownload = browser.find_by_xpath(r'//*[@id="download_btn2"]')[0] 40 # btnDownload.click() 41 time.sleep(3) 42 # btnConfirm = browser.find_by_xpath(r'//*[@id="user_score_btn"]')[0] 43 # btnConfirm.click() 44 # print "done" 45 46 # try: 47 btnConfirm = browser.find_by_xpath(r'//*[@id="user_score_btn"]')[0] 48 btnConfirm.click() 49 # time.sleep(3) 50 # print "done" 51 # except: 52 # print "error" 53 54 def searchFree(): 55 """用百度搜索免费的资源,返回资源的列表""" 56 global browser 57 url = "http://www.baidu.com" 58 browser.visit(url) 59 btnKeyWord = browser.find_by_id('kw')[0] 60 btnKeyWord.fill(u'"资源积分:0分" 联通下载 pdf site:download.csdn.net')#密码 61 btnSubmit = browser.find_by_id("su")[0] 62 btnSubmit.click()#提交搜素 63 64 base = 0 65 time.sleep(4) 66 for page in range(1,90): 67 # timerThread = closeWindow(browser) 68 # timerThread.start() 69 print base," base" 70 print page," page" 71 for x in range(base+1,base+11): 72 print x 73 time.sleep(4) 74 urlTmp = browser.find_by_xpath('//*[@id="%d"]/h3/a'%x)[0] 75 urlTmp.click() 76 browser.windows.current = browser.windows[1] 77 browser.driver.set_window_size(800,1000) 78 time.sleep(6) 79 download() 80 print "time out error" 81 browser.windows.current = browser.windows[0] 82 browser.windows.current.close_others() #关闭窗口 83 base = base + 10 84 nextPage = browser.find_link_by_text(u"下一页>")[0] 85 nextPage.click() 86 87 88 if __name__ == "__main__": 89 browser = Browser('chrome')# 90 login() 91 searchFree() 92 print "Hello Kitty"
代码未经过整理,有些乱。
中间遇到的主要问题就是元素的加载。
有的时候由于网络状况的不同,元素的加载时间也不一样。所以中间会有很多sleep。而且csdn还使用了谷歌的网站统计功能,有的时候网页加载时间就更加的长。网页中的js脚本有的时候不能执行,因为js脚本的执行顺序是比网页的加载顺序靠后的。
还有完善的空间,最后看下刷分的成果。
