一. 解析模块
1)drf给我们通过了多种解析数据包方式的解析类
2)我们可以通过配置来控制前台提交的哪些格式的数据后台在解析,哪些数据不解析
3)全局配置就是针对每一个视图类,局部配置就是针对指定的视图来,让它们可以按照配置规则选择性解析数据
源码入口
APIView类的dispatch方法中
request = self.initialize_request(request, *args, **kwargs) # 点进去
获取解析类
parsers=self.get_parsers(), # 点进去
去类属性(局部配置) 或 配置文件(全局配置) 拿 parser_classes
return [parser() for parser in self.parser_classes]
全局配置: 项目settings.py文件
REST_FRAMEWORK = {
# 全局解析类配置
'DEFAULT_PARSER_CLASSES': [
'rest_framework.parsers.JSONParser', # json数据包
'rest_framework.parsers.FormParser', # urlencoding数据包
'rest_framework.parsers.MultiPartParser' # form-date数据包
],
}
局部配置: 应用views.py的具体视图类
from rest_framework.parsers import JSONParser
class Book(APIView):
# 局部解析类配置,只要json类型的数据包才能被解析
parser_classes = [JSONParser]
pass
二. 异常模块
为什么要自定义异常模块
1)所有经过drf的APIView视图类产生的异常,都可以提供异常处理方案
2)drf默认提供了异常处理方案(rest_framework.views.exception_handler),但是处理范围有限
3)drf提供的处理方案两种,处理了返回异常现象,没处理返回None(后续就是服务器抛异常给前台)
4)自定义异常的目的就是解决drf没有处理的异常,让前台得到合理的异常信息返回,后台记录异常具体信息
源码分析:
# 异常模块:APIView类的dispatch方法中
response = self.handle_exception(exc) # 点进去
# 获取处理异常的句柄(方法)
# 一层层看源码,走的是配置文件,拿到的是rest_framework.views的exception_handler
# 自定义:直接写exception_handler函数,在自己的配置文件配置EXCEPTION_HANDLER指向自己的
exception_handler = self.get_exception_handler()
# 异常处理的结果
# 自定义异常就是提供exception_handler异常处理函数,处理的目的就是让response一定有值
response = exception_handler(exc, context)
使用自定义exception——handler函数书写实现体
# 修改自己的配置文件setting.py
REST_FRAMEWORK = {
# 全局配置异常模块
'EXCEPTION_HANDLER': 'api.exception.exception_handler', # api下的exception文件,, exception文件建立的目的是让异常走我自己定义的异常
}
# 1)先将异常处理交给rest_framework.views的exception_handler去处理
# 2)判断处理的结果(返回值)response,有值代表drf已经处理了,None代表需要自己处理
# 自定义异常处理文件exception,在文件中书写exception_handler函数
from rest_framework.views import exception_handler as drf_exception_handler
from rest_framework.views import Response
from rest_framework import status
def exception_handler(exc, context):
# drf的exception_handler做基础处理
response = drf_exception_handler(exc, context)
# 为空,自定义二次处理
if response is None:
# print(exc) # 异常的根本信息
# print(context) # 我们发送的内容 {'view', 'args', 'request'}
print('%s - %s - %s' % (context['view'], context['request'].method, exc))
return Response({
'detail': '服务器错误'
}, status=status.HTTP_500_INTERNAL_SERVER_ERROR, exception=True)
return response
3. 响应模块
响应类构造器: rest_framework.response.Response
def __init__(self, data=None, status=None,
template_name=None, headers=None,
exception=False, content_type=None):
"""
:param data: 响应数据
:param status: http响应状态码
:param template_name: drf也可以渲染页面,渲染的页面模板地址(不用了解)
:param headers: 响应头
:param exception: 是否异常了
:param content_type: 响应的数据格式(一般不用处理,响应头中带了,且默认是json)
"""
pass
使用:常规实例化响应对象
# status就是解释一堆 数字 网络状态码的模块
from rest_framework import status就是解释一堆 数字 网络状态码的模块
# 一般情况下只需要返回数据,status和headers都有默认值
return Response(data={数据}, status=status.HTTP_200_OK, headers={设置的响应头})
4. 序列化组件
用drf实现序列化:第一步声明序列化器 第二步使用我们的序列化器序列化queryset,把模型对象(orm对象)放入序列化器进行字段匹配,匹配上的字段进行序列化,匹配不上丢弃,序列化好的数据在ser_obj.data中。外键关系的序列化是嵌套的序列化器对象特别注意many=True
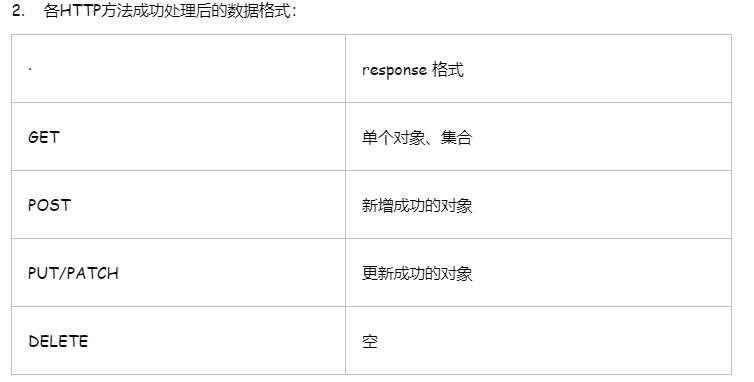
将Python对象转化为json格式的字符串,如果前后端分离一定是不能把对象直接返回去,json不能序列化对象,只能序列化字典和列表,get请求是序列化,post请求为反序列化,前端页面返回数据给后端,如果数据不合法,错误信息全都在对象.error里面.并且返回给前端.
使用序列化组件有两个要求:
1. 新建一个序列化类继承Serializer
2. 在类中写要序列化的字段
# 这里建议在app01应用下重新建一个ap01serializer的文件夹
在视图中使用序列化的类:
1 实例化序列化的类产生对象,在产生对象的时候,传入需要序列化的对象
2. 对象.data返回就行
3. return Response(对象.data)
url层:urls.py
url(r'^books/', views.Books.as_view())
models.py
from django.db import models
# Create your models here.
class Book(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
publish_date = models.DateField()
publish = models.ForeignKey(to='Publish',to_field='nid',on_delete=models.CASCADE)
authors=models.ManyToManyField(to='Author')
def __str__(self):
return self.name
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
email = models.EmailField()
app01serializer.py
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
# 指定source=’name’,表示序列化模型表中的字段name字段,重命名为name5(name和source=name不能重名)
name5 = serializers.CharField(source='name')
price = serializers.CharField() # 将price转换为字符串
# 如果获取出版社的city, source=‘publish.city’
publish = serializers.CharField(source='publish.name')
# source不但可以指定一个字段,还可以指定一个方法
# 序列化出版社的详情, 指定SerializerMethodField之后,可以对应一个方法,返回什么内容,publish——detail就是什么内容
publish_detail = serializers.SerializerMethodField()
views.py
from rest_framework.views import APIView
from rest_framework.serializers import Serializer # 序列化的类
from rest_framework.response import Response # 在drf中返回用Response 比jsonresponse强大,可以返回页面
from app01 import models
from app01.app01serializer import BookSerializer
class Books(APIView):
def get(self, request):
books = models.Book.objects.all()
# 如果序列化多条,many=True (也就是queryset对象, 就需要写)
# 如果序列化一条,就可以不写many=True
bookser = BookSerializer(books, many=True)
print(bookser.data)
return Response(bookser.data) # 返回一个页面,用其他的不会产生页面
序列化的两种方式:
Serializers: 没有指定表模型
-source: 指定要序列化哪个字段, 可以是字段,可以是方法
-SerializerMethodField的用法
authors=serializers.SerializerMethodField()
def get_authors(self,obj):
ret=AuthorSerializer(instance=obj.authors.all(),many=True)
return ret.data
-ModelSerializers: 指定了表模型
class Meta:
model=表模型
#要显示的字段
fields=('__all__')
fields=('id','name')
#要排除的字段
exclude=('name')
#深度控制
depth=1
-重写某个字段
在Meta外部,重写某些字段,方式同Serializers
5. 反序列化之create重写
反序列化的目的在于数据校验与数据入库,使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。在获取反序列化的数据前,必须调用is_valid()方法进行验证,验证成功返回True,否则返回False。验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误。验证成功,可以通过序列化器对象的validated_data属性获取数据。在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为
-高级用法:
-source:可以指定字段(name publish.name),可以指定方法,
-SerializerMethodField搭配方法使用(get_字段名字)
publish_detail=serializers.SerializerMethodField(read_only=True)
def get_publish_detail(self,obj):
return {'name':obj.publish.name,'city':obj.publish.city}
-read_only:反序列化时,不传
-write_only:序列化时,不显示
重写create方法,得在校验通过之后才可以调用create方法
重写create方法,实现序列化
在序列化类中:
def create(self, validated_data):
ret = models.Book.objects.create(**validated_data)
return ret
在视图中:
def post(self, request):
# 实例化产生一个序列化类的对象, data是反序列化的字典
bookser = BookSerializer(data=request.data) # 用data接收request.data表示反序列化
if bookser.is_valid():
ret = bookser.create(bookser.validated_data)
return Response()
6. 反序列化的校验,全局和局部
反序列化:第一步确定新增的数据结构, 第二步在序列化器中,正序列化与反序列化字段不统一,require=False 只序列化不走校验,read_only=True只序列化用,write_only=True 只反序列化用,重写create方法,验证通过返回user_obj.validated_data,验证不通过返回user_obj.errors。
from app01 import models
# 继承了modelSerializers序列化类的对象,反序列化
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book
# 需要序列化的字段
fields = ["name", "publish"] # 列表或者元组
exclude=(‘name’) # 除了name,其他的都显示,跟field不能同时使用
# 全部的字段
fields = ("__all__",)
有choice的字段时,如果要将前面的序号转化为后面的汉字,用字段名=serializer.CharField(source="get_xx_display")即可,也就是等于把这个字段重写了,
比如想拿出所有的authors
authors = serializers.SerializerMethodField()
def get_authors(self, obj)
ret = AuthorSerializer(instance=obj.authors.all(), many=True)
return ret.data
反序列化的校验:(局部校验,全局校验)
比如校验名字
from rest_framework.exception import ValidationError
def validate_name(self, value): # value是当前传过来字段的值
if value.startswith('sb'):
raise ValidationError("不能以sb开头")
return value
全局校验:
def validate(self, attrs): # 校验通过的所有字典
if attrs.get('password') == attrs.get('repassword')
raise ValidationError("两次密码不一致")
return attrs