Retention Policy
RP表示数据保留策略,策略包含数据保留时长,备份个数等信息。InfluxDB为每个database默认创建了一个默认的RP,名称为autogen,默认数据保留时间为永久。
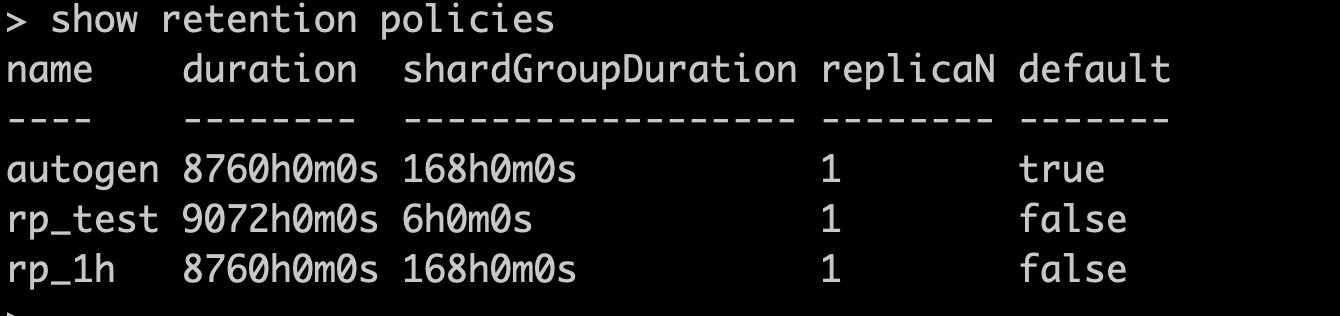
查看RP
show retention policies
新建RP
CREATE RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> [SHARD DURATION <duration>] [DEFAULT]
| name | example |
|---|---|
| duration | 表示数据保留时间,最长为INF,最短为1h |
| replication | 备份数,在集群模式中可用 |
| shard duration | 一个分片包含的时间,InfluxDB会根据duration设置默认的shard duration |
| default | 表示该RP为默认的RP |
新建一个RP,保留时间为1d
CREATE RETENTION POLICY "one_day_only" ON "NOAA_water_database" DURATION 1d REPLICATION 1
修改RP
ALTER RETENTION POLICY <retention_policy_name> ON <database_name> DURATION <duration> REPLICATION <n> SHARD DURATION <duration> DEFAULT
删除RP
DROP RETENTION POLICY <retention_policy_name> ON <database_name>
RP使用
在查询或者插入数据时,需要指定RP,若不指定,则认为选择了默认的RP
select sum(value) from "rp_1h".test_me where time > now() - 6h;
假设默认RP为autogen,则
select sum(value) from test_me where time > now() - 6h;=== 两条语句等价
select sum(value) from "autogen".test_me where time > now() - 6h;
Continue Query
InfluxDB提供了自动聚合数据,并将聚合数据存储至measurement的方法,即continue query
基础用法
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
BEGIN
<cq_query>
END
其中cq_query表示聚合语句,
SELECT <function[s]> INTO <destination_measurement> FROM <measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<tag_key[s]>]
cq_query的where条件中不需要设置时间区间,inflxuDB会自动生成时间区间
influxDB根据cq_query中的Group By time(interval)的interval,每隔interval执行一次cq_query,而查询的时间区间也为interval。例如当前时间为17:00,interval为1h,则cq_query会查询16:00至16:59分的数据。
生成一条CQ如下,则每隔1h执行一次query
CREATE CONTINUOUS QUERY "cq_basic" ON "transportation"
BEGIN
SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(1h)
END
在8:00,时间区间为[7:00,8:00)
在9:00,时间区间为[8:00,9:00)
根据CQ的特性,可以进行数据降准,例如将维度为1m的数据聚合为5m,measurement_1m存储维度为1m的数据,cq每隔5m对数据进行聚合,并将聚合的数据存储到rp_5m.measurement_5m中,此时维度变成了5m
CREATE CONTINUOUS QUERY "cq_basic_5m" ON "test_database"
BEGIN
SELECT mean(*) INTO "rp_5m"."measurement_5m"
FROM "rp_1m"."measurement_1m"
GROUP BY time(5m),*
END
时间偏移
CREATE CONTINUOUS QUERY "cq_basic_offset" ON "transportation"
BEGIN
SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(1h,15m)
END
group by time(1h) 与 group by time(1h,15m)的区别
group by time(1h)的执行时间点和时间区间
| time | range |
|---|---|
| 8:00 | [7:00,8:00) |
| 9:00 | [8:00,9:00) |
group by time(1h, 15m)的执行时间点和时间区间
| time | range |
|---|---|
| 8:15 | [7:15,8:15) |
| 9:15 | [8:15,9:15) |
高级用法
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>
RESAMPLE EVERY <interval> FOR <interval>
BEGIN
<cq_query>
END
其中EVERY表示执行间隔,即每隔多久执行一次,FOR表示时间区间,即每次执行查询多久的数据,区间为[now - for_interval, now)
EVERY=30m,GROUP BY time(1h)
CREATE CONTINUOUS QUERY "cq_advanced_every" ON "transportation"
RESAMPLE EVERY 30m
BEGIN
SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(1h)
END
| time | range | 返回time |
|---|---|---|
| 8:00 | [7:00,8:00) | 7:00 |
| 8:30 | [7:00,8:00) | 7:00 |
| 9:00 | [8:00,9:00) | 8:00 |
可以看到区间[7:00,8:00)的数据被查询了两次,后一次的数据会覆盖前一次的查询
FOR=1h,GROUP BY time(30m)
CREATE CONTINUOUS QUERY "cq_advanced_for" ON "transportation"
RESAMPLE FOR 1h
BEGIN
SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(30m)
END
| time | range | 返回time |
|---|---|---|
| 8:00 | [7:00,8:00) | 7:00 7:30 |
| 8:30 | [7:30,8:30) | 7:30 8:00 |
| 9:00 | [8:00,9:00) | 8:00 8:30 |
每次查询都会返回两条数据,每个时间点的数据都被计算了两次,这样在一定程度可以避免数据延迟而导致CQ数据丢失的情况。
EVERY=1h,FOR=90m,GROUP BY time(30m)
CREATE CONTINUOUS QUERY "cq_advanced_every_for" ON "transportation"
RESAMPLE EVERY 1h FOR 90m
BEGIN
SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(30m)
END
| time | range | 返回time |
|---|---|---|
| 8:00 | [6:30,8:00) | 6:30 7:00 7:30 |
| 9:00 | [7:30,9:00) | 7:30 8:00 8:30 |
FOR interval必须大于GROUP by time(interval)以及EVERY interval,否则InfluxDB会返回如下错误,因为这样会造成数据丢失
error parsing query: FOR duration must be >= GROUP BY time duration: must be a minimum of <minimum-allowable-interval> got <user-specified-interval>
CQ管理
查看CQ
SHOW CONTINUOUS QUERIES
删除CQ
DROP CONTINUOUS QUERY <cq_name> ON <database_name>
修改CQ
CQ不能被修改,如果需要需改,只能先删除CQ,在重新创建CQ
使用CQ与RP的目的
- 利用CQ可以达到数据降准的目的,即将细粒度的数据转换为粗粒度的数据,例如1m维度的数据可以聚合为5m数据
- 不同粒度的数据可以设置不同的RP,节省存储空间。例如1m维度的数据可以保存7d,而5m维度的数据则可以保存30d,细粒度的数据主要用于及时排查问题,粗粒度的数据在于查看变化趋势。