一、大数据关键技术
(1)数据采集
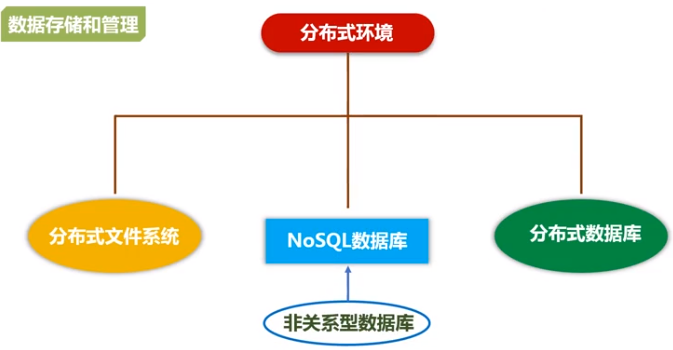
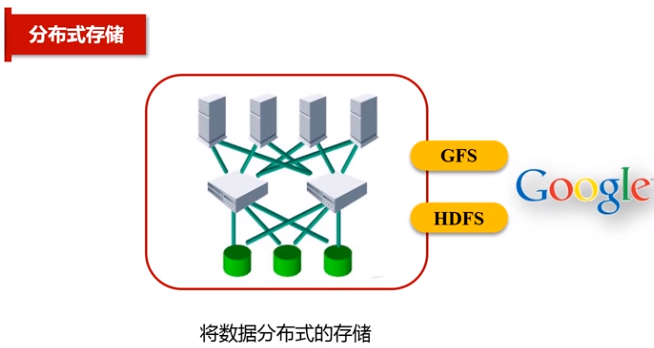
(2)数据存储
(3)数据处理



(4)数据安全

二、大数据计算模式
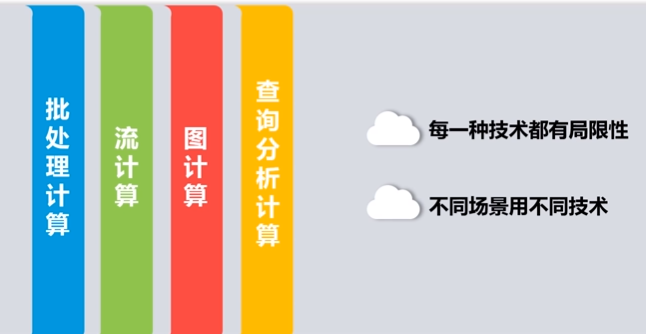
| 大数据计算模式 | 解决问题 | 代表产品 |
| 批处理计算 | 针对大规模数据的批量处理 | MapReduce、Spark等 |
| 流计算 | 针对流数据的实时计算 | Storm、Flume、DStream、银河流数据处理平台等 |
| 图计算 | 针对大规模图结构数据的处理 | Pregel、GraphX、Giraph、PowerGraph等 |
| 查询分析计算 | 大规模数据的存储管理和查询分析 | Hive、Presto、Impala等 |
1.批处理计算
特点:无法实时响应,但是能得到接近准实时性。


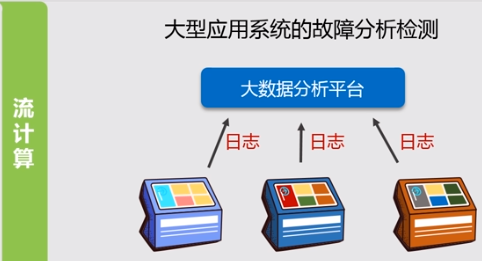
2.流计算
特点:数据量少,源源不断到达,但是响应时间要求非常短,一般是秒级/毫秒级



3.图计算
应用场景:社交网络、物流

4.查询分析计算
三、代表性大数据技术
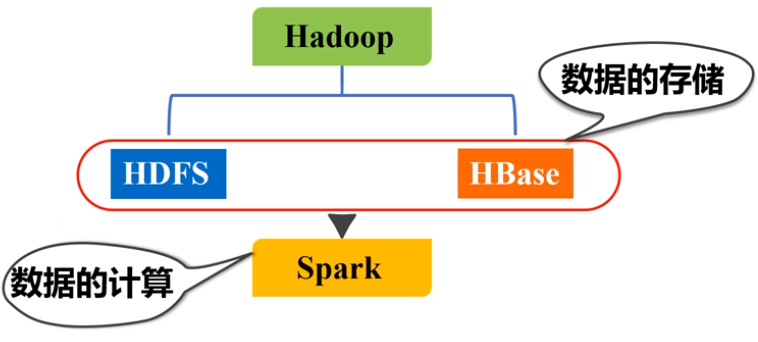
1.Hadoop
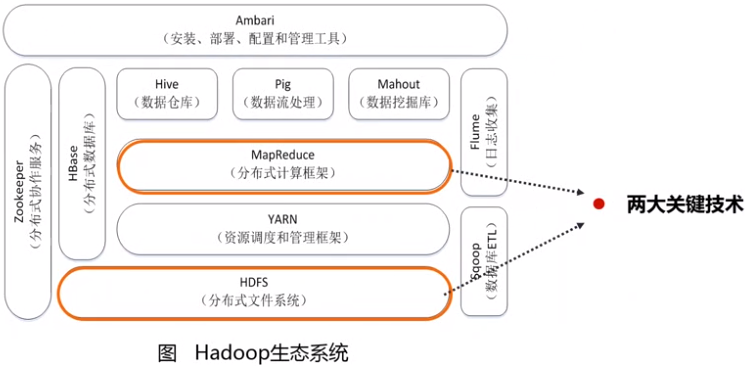
(1)HDFS
HDFS功能:海量数据的分布式存储
- 名称节点:作为中心服务器,负责管理文件系统的命名空间以及客户端对文件的访问。
- 数据节点:负责处理文件系统客户端的读写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。
(2)YARN
功能:负责为上层计算框架MapReduce提供资源调度(集群)和管理服务
YARN的目标就是实现“一个集群多个框架”
一个企业当中同时存在各种不同的业务应用场景,需要采用不同的计算框架:
- 使用MapReduce实现离线批处理
- 使用Impala实现实时交互式查询分析
- 使用Storm实现流式数据实时分析
- 使用Spark实现迭代计算
这些产品通常来自不同的开发团队,具有各自的资源调度管理机制为了避免不同类型应用之间互相干扰,企业就需要把内部的服务器拆分成多个集群,分别安装运行不同的计算框架,即“一个框架一个集群”
导致问题:
- 集群资源利用率低
- 数据无法共享
- 维护代价高


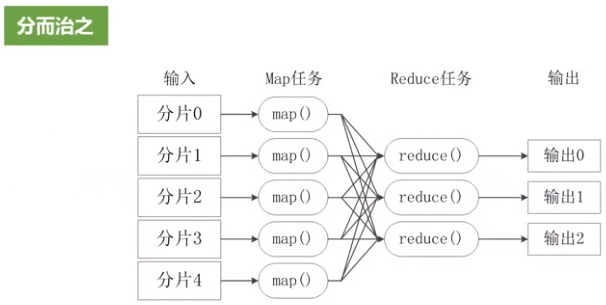
(3)MapReduce
功能:完成分布式并行计算任务
MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
(4)Hive数据仓库
功能:一个时间维度上保存连续数据
- 存储:数据仓库的数据保持在HDFS基础之上
- 查询:将SQL语句自动转换对HDFS的查询分析,得到结果
数据库 与 数据仓库区别:
- 数据库:保存某一时刻的状态数据,不能记录历史状态信息
- 数据仓库:数据仓库以天/周为单位,每天保存一次它的镜像,形成一个时间维度上保存连续数据。
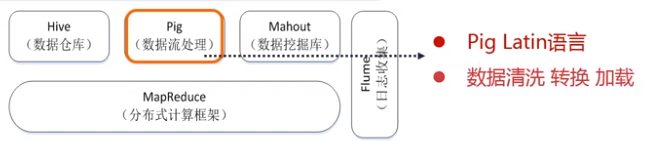
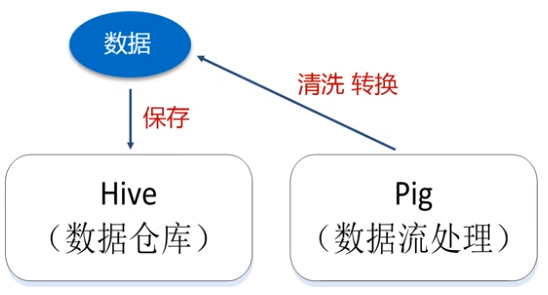
(5)Pig
功能:在数据放入数据仓库之前,将数据进行集成、转换、加载
(6)Mahout
功能:基于MapReduce的数据挖掘算法的接口


(7)HBase
功能:分布式数据库,HBase的底层数据是借助于分布式文件系统进行保存的
(8)Zookeeper
功能:负责分布式协调一致性服务
(9)Flume
功能:日志采集分析
(10)Sqoop
功能:完成Hadoop系统组件之间的互通(Hadoop组件与MySQL的互导),例如,HDFS<==>MySQL
2.Spark
功能:类似MapReduce

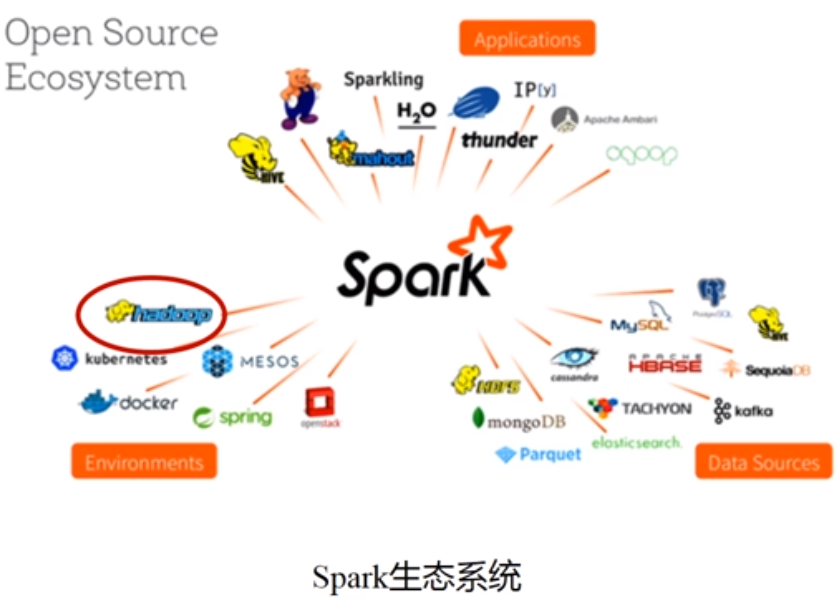
spark架构:
(1)Saprk SQL
功能:分析关系数据
(2)Spark Streaming
功能:进行流计算
(3)MLlib
功能:提供机器学习算法库
(4)GraphX
功能:编写图计算应用程序
(5)Spark Core
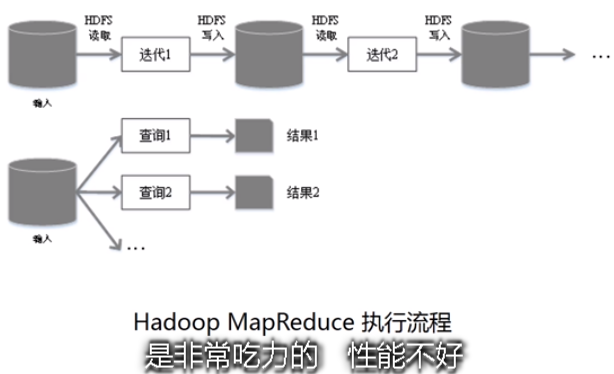
MapReduce缺点:
- 表达能力有限
- 磁盘IO开销大
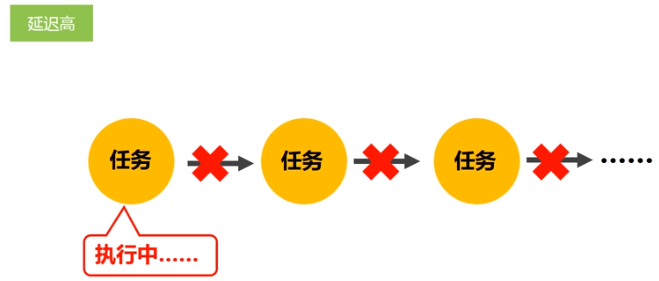
- 延迟高(存在任务衔接等待的开销;前一个任务未完成之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务)
spark优点:
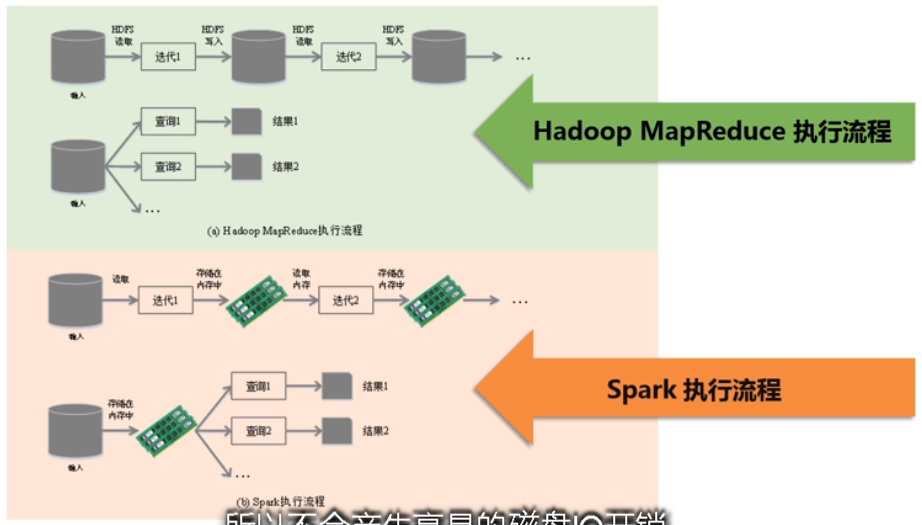
- spark的计算模式也属于MapReduce,但不限于Map和Reduce操作,还支持多种数据集操作类型,编程模型更灵活
- 提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高。
- 基于DAG(有向无环图)的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制


3.Flink
功能:类似Spark
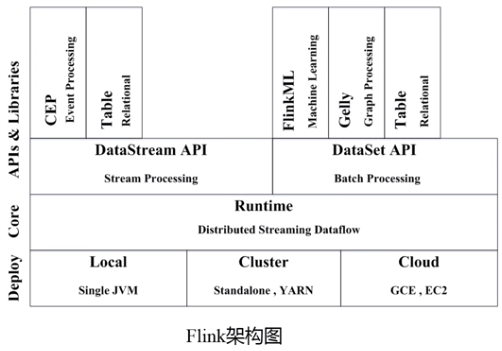
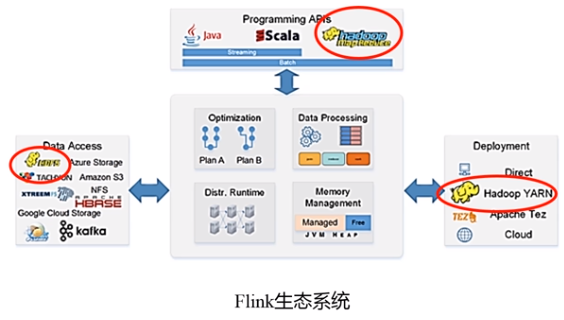
Flink 与 Spark的对比:
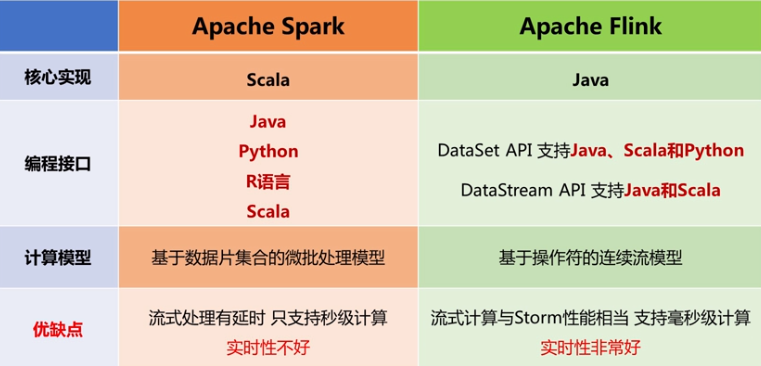
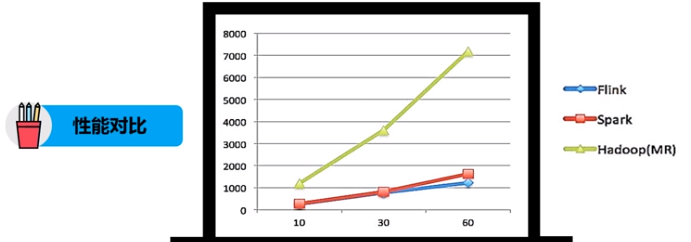
性能对比:都可以基于内存计算框架进行实时计算,所以都拥有非常好的计算性能。经过测试,Flink计算新呢过上略好。Spark和Flink都运行在Hadoop YARN上,性能为Flink>Spark>Hadoop(MR),迭代次数越多越明显,性能上Flink更优的主要原因是Flink支持增量迭代,具有对迭代自动优化的功能。
- 流式计算比较:它们都支持流式计算,Flink是一行一行处理,而Spark是基于数据片集合(RDD)进行小批量处理,所以Spark在流式处理方面,不可避免增加一些延时。Flink的流式计算跟Storm性能差不多,支持毫秒级计算,而Spark则只能支持秒级计算。
- SQL支持:都支持SQL,Spark对SQL的支持比Flink支持的范围要大一些,另外Spark支持对SQL的优化,而Flink支持主要是对API级的优化。
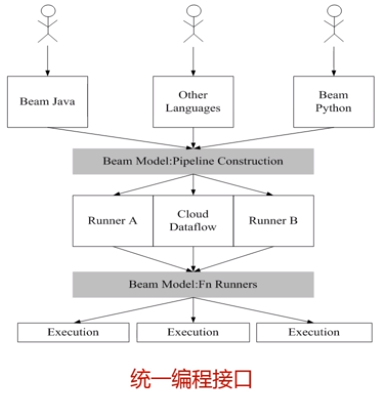
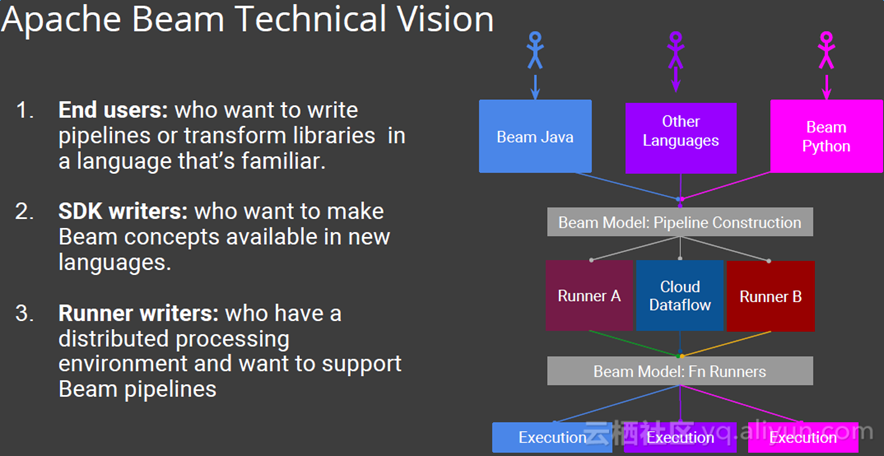
4.Beam
Beam是一整套编程接口,并没有完全开源