URL: https://arxiv.org/abs/1608.08021
year: 2016
TL;DR
PVANet 一个轻量级多物体目标检测架构, 遵循 “less channels with more layers” 的设计原则, 通过结合 CReLU, Inception, HyperNet 3 个模块构成了一个高效的目标检测架构, 在达到了当时 SOTA.
- CReLU 应用于PVANet 早期阶段, 以将计算次数减少一半而不会失去准确性。
- Inception 应用于特征生成子网络的剩余部分。 Inception 模块产生不同大小的感受野的输出,因此增加了前一层中感受野大小的多样性。 我们观察到堆叠 Inception 模块可以比线性卷积链更有效地捕获大小不同大小的对象。
- HyperNet 采用了多尺度表示的概念,它结合了多个中间输出,因此可以同时考虑多个级别的细节和非线性。
Dataset/Algorithm/Model/
CReLU
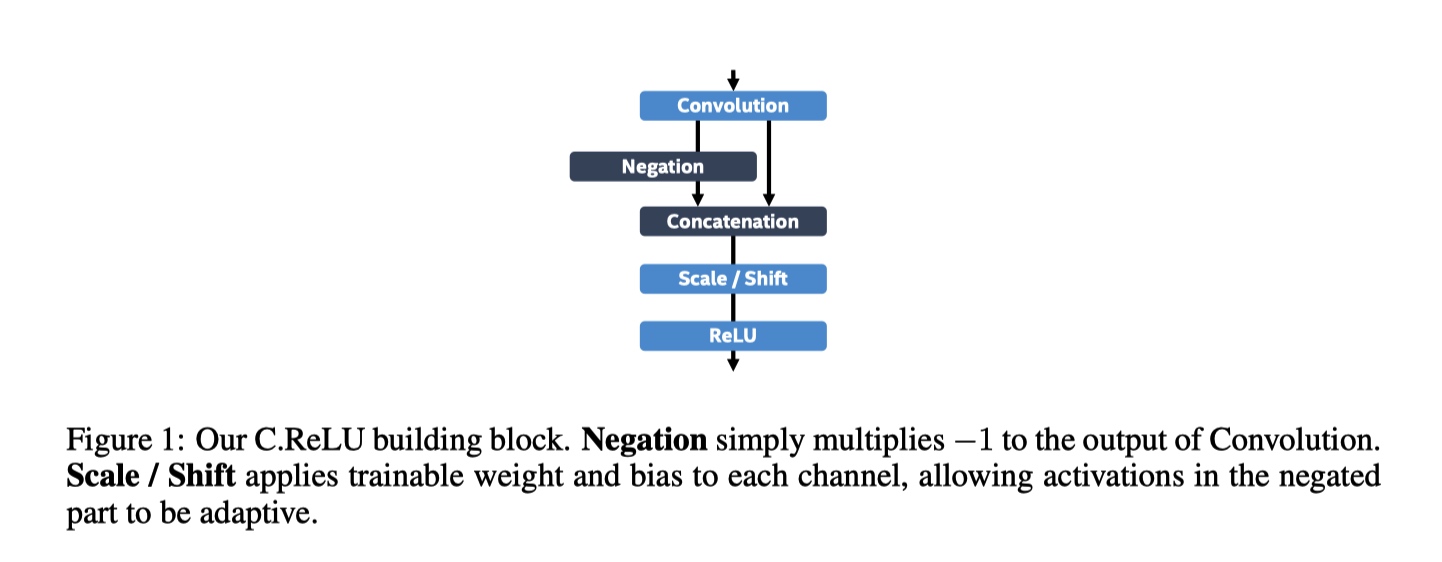 

C.ReLU的设计动机来自对CNN中的激活模式的有趣观察。 在CNN早期阶段,输出节点倾向于“成对”出现,使得一个节点的激活是另一个节点的取反。 根据这一观察结果,CReLU将输出通道的数量减少了一半,并通过简单地将输出与其取反Concat来使通道加倍,这可以在网络的早期阶段加速2倍而不会失去准确性。
Inception
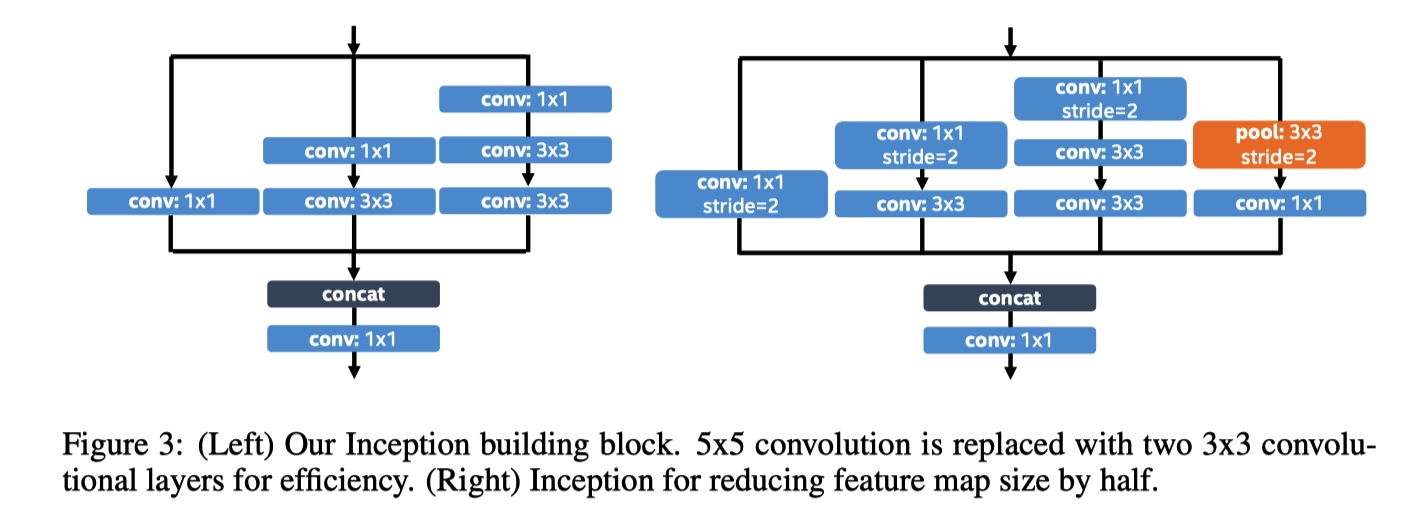 

我们发现Inception可以是用于捕获输入图像中的小对象和大对象的最具成本效益的构建块之一。 要学习捕获大型物体的视觉模式,CNN的输出特征应该对应于足够大的感受野,这可以通过堆叠3x3或更大内核的卷积来轻松实现。 另一方面,为了捕获小尺寸物体,输出特征应该对应于足够小的感受野,以精确地定位感兴趣的小区域。
HyperNet
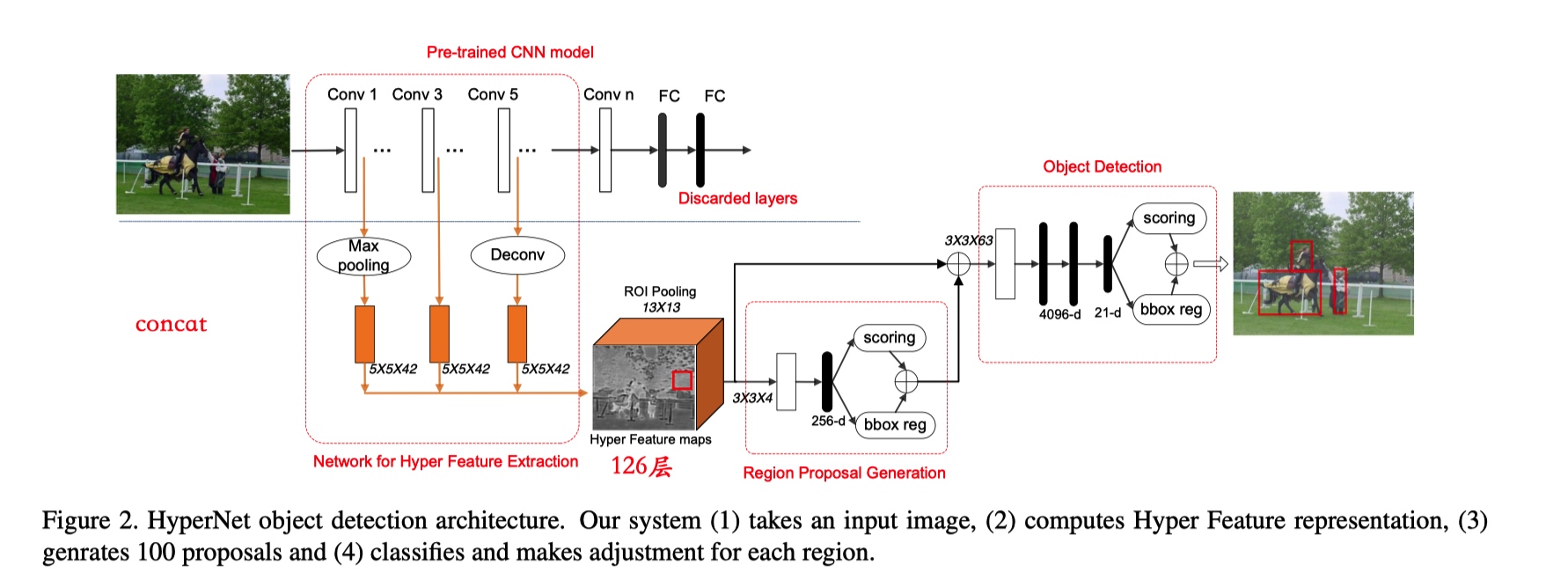 

多尺度表示及其融合被证明在许多最近的深度学习任务中是有效的。 将细粒度细节与特征提取层中的高度抽象信息相结合,有助于以下 RPN(region proposal network) 和分类网络检测不同尺度的对象。
PVANet
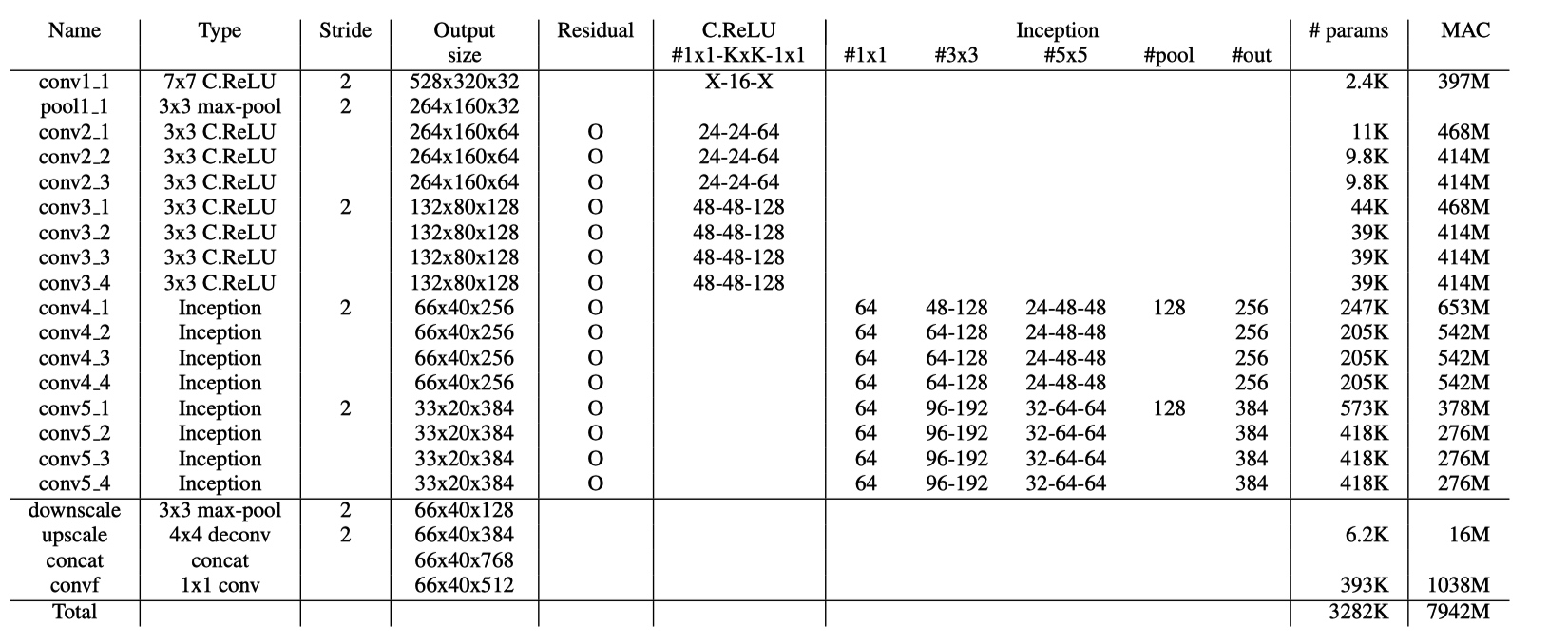 

Experiment Detail
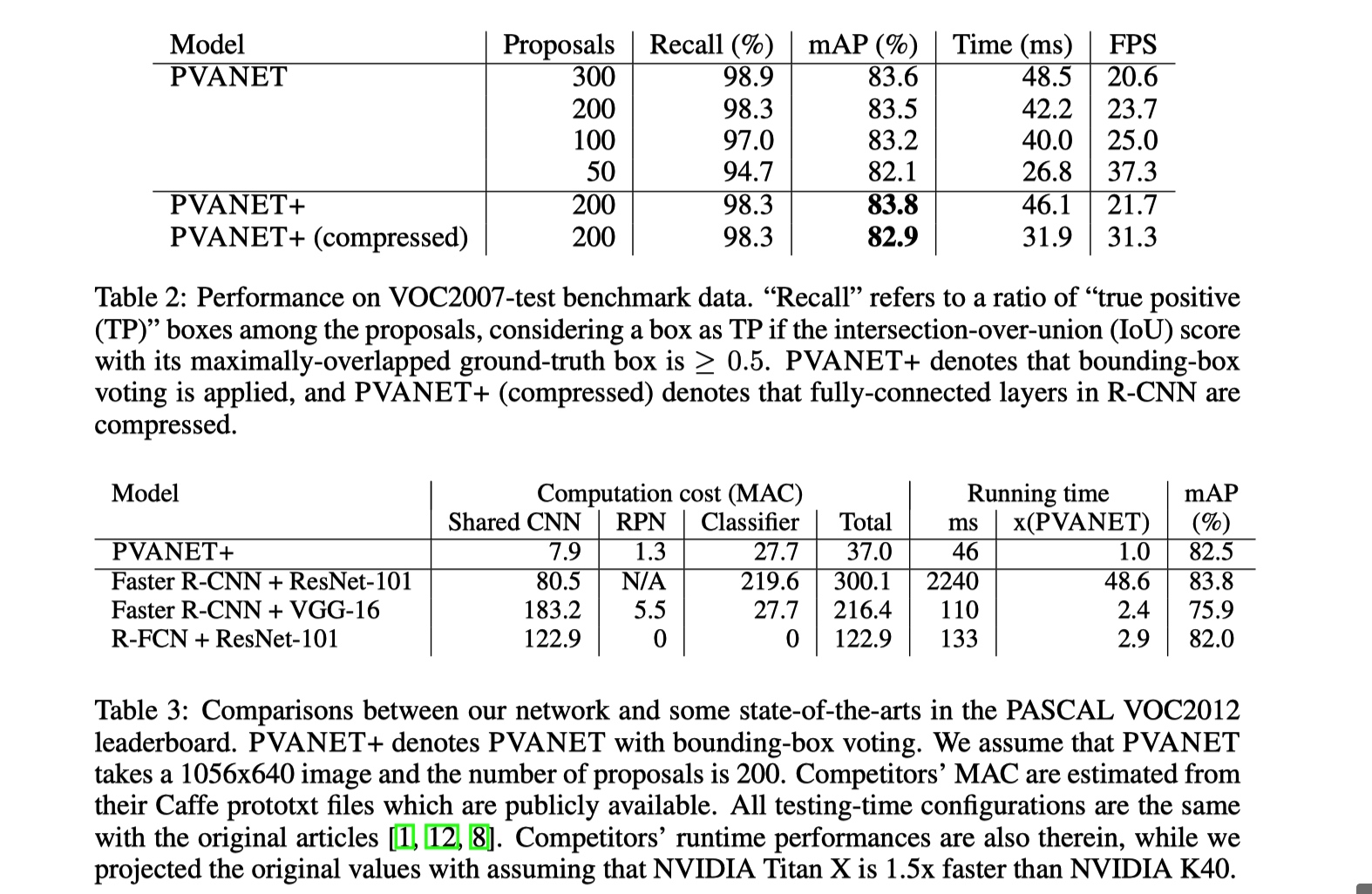 

Thoughts
为设计轻量级多尺度特征检测, 特征融合提供思路