Python 之 多任务:
Python之多任务是现在多任务编程运用Python语言为载体的一种体现。其中涵盖:进程、线程、并发等方面的内容,以及包括近些年在大数据运算、人工智能领域运用强大的GPU运算能力实现的各种算法。属于Python语言中比较高级的应用形式。文章采取问答的形式对知识点和相关应用的模式进行详解,看似像意识流形态的文章,其内容也是遵循循序渐进,力求全面和精细。
问:什么是多任务?
答:百度定义:“当多任务处理是指用户可以在同一时间内运行多个应用程序,每个应用程序被称作一个任务。”也就是说操作系统可以同时运行多个任务。这个概念是基于操作系统来说的。比如电脑同时开启多个软件或者应用程序,这就是一种多任务的体现;于此相对如果我们电脑只能每次开启一个软件或者一个应用程序,关闭前者才能开启后者这就叫做单任务,在早期的电脑基本都属于单任务,对于现在的计算机应用基本上都属于多任务的形式存在,因此我们也只讨论多任务。
问:CPU是整个运算的核心,CPU、操作系统、多任务之间的关系什么?
答:1. 现在的CPU基本上都是2核以上的CPU,如果我们现在手里有一台单核的CPU和一台多核CPU,我们的多任务在上面又是怎么实现的呢?
1.1. 单核CPU实现多任务原理?
操作系统轮流让各个任务交替执行,CPU对每个任务进行“时间切片”的动作,这个切片时间非常短暂,打个比方,一整块的奶酪难以下咽,我们把奶酪切成一小块一小块的,让我们的CPU以飞快的速度进行“吞噬”。同样我们比如有N个任务,把每一个任务切成“时间切片”,如此交替往复的切换运行。这样表面上看像是多任务一起执行,但是CPU调度执行速度太快了,导致我们感觉所有任务都是同事执行一样。
1.2. 多核CPU实现多任务原理?
真正的并行执行多任务只能在多核CPU上实现,但是任务数量远远多于CPU核心数量,所以操作系统会把很多任务轮流调度到每个核心上执行。和单核CPU实现多任务原理相比,多核CPU真正实现了“多窗口”的轮流调度任务。
1.3. 打个比方,单核CPU就像银行开一个窗口来处理任务,多核CPU开多个窗口来处理任务。这个任务之间的调度是通过操作系统来完成的。
2. CPU核和线程是一个什么概念?
这里再稍微扩展一下:我们说一下CPU的主频、核心、线程、架构。
CPU是整个计算机的大脑。
主频:我们经常看到CPU参数当中有3.0GHz、3.7GHz等,这就是CPU的主频,严谨的说他是CPU的时钟频率,也可以直接理解为运算速度。主频越大力量越大。
核心:我们常常说计算机是几核心的。主频我们可以理解为肌肉,核心我们可以理解为胳膊,如果你有16条胳膊(也就是16核心),你所能干的事情也是越多。直观来看在CPU中心隆起的芯片就是核心,是由单晶硅以一定的生产工艺制造出来的。每一个CPU核心都有自己固定的逻辑结构,一级缓存、二级缓存,执行单元、指令集单元和总线接口等。打个比如,一条胳膊都有肌肉,骨骼、神经、血管等一套逻辑系统。
线程:有了胳膊还必须有手才能工作。一般来说单核配单线程,双核配双线程。也就说一条胳膊配一只手。但是我们有些CPU比如4核8线程,也就是说有4条胳膊,每条胳膊配2只手(看起来有点儿恐怖了),但是这样多造出来的两只手,干活的效率就大大的提高了。
架构:现在有了肌肉、胳膊、手,就差一个工具就可以干活了,这就是CPU的架构,架构对刑恩该影响巨大。比如现在通行的ARM架构等。
3. 关系:
计算机通过操作系统,把多个任务调度到CPU的核心上进行计算,他们之间是载体和对象,实现和被实现、调度和被调度之间的关系。
问:并行和并发是什么概念?
答:并发:看上去是一起执行,任务多于CPU核心数。
并行:真正一起执行,任务数小于CPU核心数。
再直观的理解一下:并发(Concurrent):指两个或多个事件在同一时间间隔内发生,即交替做不同事的能力。并行(Parallel):指两个或多个事件在同一时刻发生,即同时做不同的能力。我们以进程举例:并发就像是我们前面说的单核CPU执行多任务的概念,交替执行,并行就像多核CPU执行多任务的概念,同时执行。再比如,我们现在有一个4核4线程的CPU,我们有5个任务一起发送给CPU,这个时候后可能是某几个程序并行一起运行,其他多于的1个任务交替并发执行。如果我们现在只有4个任务,这样4个任务就可以完全“吃饱”了CPU的进程,就可以并行(当然这里是不考虑其他因素的情况下)。
问:进程、线程、任务都是什么东西?
答:进程:对于操作系统而言,一个任务就是一个进程。进程是系统中程序执行和资源分配的基本单位。每个进程都有自己的数据段、代码段、堆栈段。
线程:在一个进程的内部,要同时干多件事情(就是手的问题),就需要同时运行多个子任务,我们把进程内的这些子任务叫做线程。也就是说线程是进程的子任务。
线程通常叫做情景进程。线程是通过向内侧控件的并发执行的多任务。每个线程都共享一个进程的资源。线程是最小的执行单元,而进程至少由一个线程组成。如何调度进程和线程,完全是由操作系统决定,用户程序不能自己决定什么时候执行。执行多长时间。
我们闭上眼睛形象的比喻一下,在线程这根柱子上面,子任务不断围绕这根柱子交替来执行(这是符合我们之前的单任务CPU的工作原理的),然后多根柱子又去并行多少个进程一起来执行。从实际运行的过程来看,任务在线程这个最小单元是并发执行的,在任务数小于CPU核心数的情况下,有可能还是并行执行的。并发是线程的经常运作模式,并行是总体的实际运行调度,微观来说任务都是在并发执行在线程上面的。
问:“抢占式”和协同式任务模式?
答:在windows3.x的时代,那个时候的程序运行任务基本上是依靠代码的编写逻辑进行的。当一个程序运行完毕后再运行下一个程序,这样做最大的风险就是如果一个程序出问题卡死就很容易出现死机的情况。抢占式任务模式,是现在基本的任务模式,比如现在我们开启了N个程序,现在我们在打字,这个优先级最高,我们就把它先推送给CPU让它先去执行,如果我们现在再打开一个程序,之前的打字的那个程序优先级退下,让当前的程序推送到最高的优先级。我们其实可以通过Windows的任务管理器去观察所有的当前任务。我们发现这些任务并不是按照一定有规律的顺序排列进行执行的,如果当前程序优先级很高它就是排在前面,而且我们如果静止不动去观察,他们的排序是会产生不断变化的。这就是“抢占式”任务模式。因此我们的程序在进程或者线程当中去运行的话,也是这种抢占式任务运行模式。
问:GIL在Python中的作用?
答:GIL全称:global interpreter lock,全局编译器锁。
GIL是实现Python解释器(CPython)时所引入的概念。Python中一个线程对应于C语言中的一个线程。Python为了简单,前期会在我们的解释器上面加一把非常大的锁。GIL一次只有一个线程运行在CPU上执行我们的字节码。字节码我们可以用dis这个包进行反编译,获得字节码。无法将多个线程映射到多个CPU上,无法体现多核的优势。如果用Java或者C语言我们可以将多个线程映射到多个CPU上形成并发或并行。PyPy编码是去GIL话的,我们大多数用测CPython解释器是由GIL概念的。
我们写一个函数然后通过dis这个包获取这个函数的字节码:
import dis def add(a): a = a + 1 return a print(dis.dis(add))
字节码翻译如下:
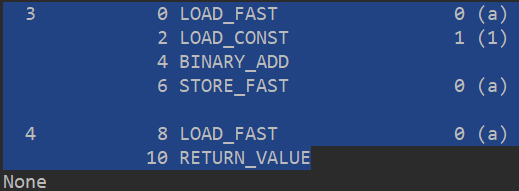
我们再来看看Python的官方文档:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once.
This lock is necessary mainly because CPython’s memory management is not thread-safe.
(However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
在 CPython中,全局解释器锁或者说GIL是一个"Mutex"(互斥锁),这个互斥锁一次阻止来自执行Python字节码的多个自然线程。这个锁最主要的必须行是因为CPython的内存管理不是线程安全的。
由于物理上的限制,各个CPU厂家在核心频率上的比赛已经被多核所替代,一切单个CPU为了增大主频提升“肌肉”硬度,但现在更像是用多核CPU去并发执行程序。Python开始支持多线程数据之间的完整性和代码状态的同步性,自然是要进行加锁控制的,正如上面说的是线程安全的,无需在实现时考虑额外的内存锁或同步操作。这一把全局排他锁,无疑会给多线程的执行效率有不小影响。甚至几乎等于单个线程的程序。GIL是站在线程的角度来说明这个问题的。
问:前面说的,由于GIL这个全局互斥锁让线程是安全的,一个进程运行在一个CPU上面,是不是就不用考虑线程的同步呢?
答:事实上并不是的!原因很简单,GIL是会被释放的,释放和加载的过程正是我们要考虑的同步问题!
我们来写一段经典的加减过程的相互对冲的函数:
import threading total = 0 def add(): global total for i in range(1000000): total += 1 def desc(): global total for i in range(1000000): total -= 1 thread1 = threading.Thread(target=add) thread2 = threading.Thread(target=desc) thread1.start() thread2.start() thread1.join() thread2.join() print(total) # 第一遍结果:-262850 # 第二遍结果:-306734
我们发现运行的结果两次都不一样。这就证明了GIL是被释放的。也证明了GIL并不是等待第一个线程完了之后再执行第二个线程,线程被任务完全的占有。他是在某个时刻适当的进行释放的。这个是结合了我们字节码的执行了多少行数,比如字节码执行了100行,或者1000行后他会释放。这侧面的说明了不是第一个函数加到了100万次,然后再执行第二个函数减到100万次的。
因此GIL释放一般会在三种情况释放:
第一种:就是前面说的按照字节码的行数进行释放。
第二种:按照时间片来进行释放。
第三种:如果遇到IO操作的时候会进行释放。
如果:#1.dosomthing
#2.IO操作
#3.dosomthing
像这样的操作的时候会主动释放,从这个角度来说GIL并不是限制的那么死。
问:线程、进行、协程等待?从那个地方进行入手呢?
答:先从线程开始入手,先讲解threading模块。在Python中还有一个_thread模块,这是更加底层的线程模块,threading模式是对_thread更加高级的一种封装。在早期的CPU是没有线程的这个概念的,只有进程的概念,但是这样对CPU的开销过大,后期引入了线程的概念。我们ctrl-alt-del键,就会在我们的任务管理器当中看到现在正在执行或者排队的线程(前面见过现在的任务模式是一种抢占式任务模式)。
对于IO操作来说:多线程和多进程差别不大。对于操作系统而言,线程的调度比进行的调度室更加轻量级的。
我们以一个简单的IO例子来说明threading模块的应用,因为正如前面说的三种释放情况,遇到IO操作的时候前面线程会释放,IO操作结束后,后面的线程再跟进来。
代码如下:
import time import threading def get_detail_html(url): print("get detail html started") time.sleep(2) print("get detail html end") def get_detail_url(url): print("get detail url started") time.sleep(2) print("get detail url end") if __name__ == '__main__': thread1 = threading.Thread(target=get_detail_html,args=("",)) thread2 = threading.Thread(target=get_detail_url,args=("",)) start_time = time.time() thread1.start() thread2.start() print("last time {}".format(time.time()-start_time))
我们分析这个打印结果发现一个有意思的现象:
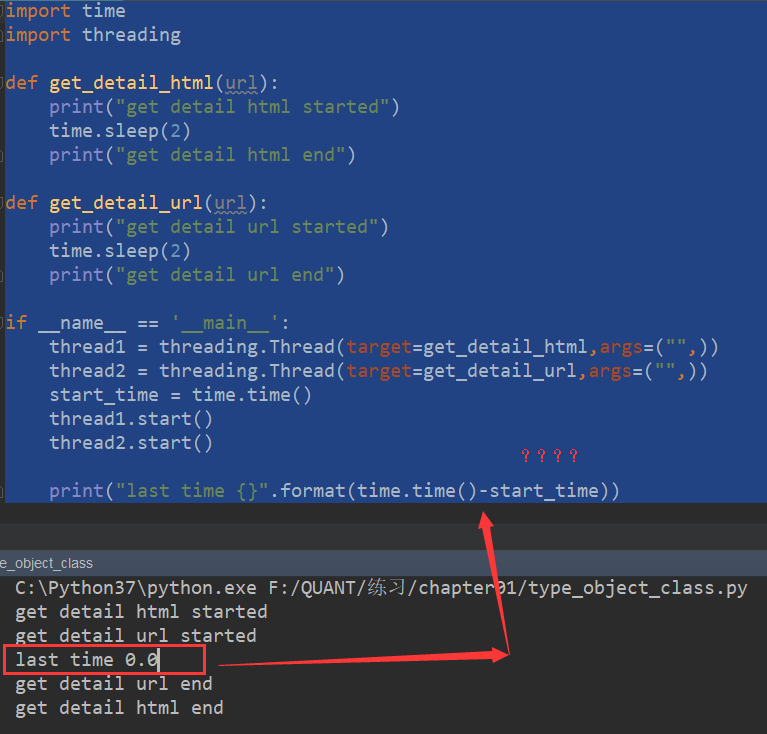
问:为什么前面代码没有执行完毕直接把时间给打印出来了?
答:这是因为在你执行thread1和thread2的时候,在背后隐藏了一个主线程。主线程不会等到两个子线程结束了之后才把结果打印出来。因此我们有如下这样一个框架:
主线程----------------------- 并发执行
子线程 -- 并发执行
子线程 -- 并发执行
如果我们不加限制的话,只要程序一运行,有没有子线程,主线程都会并发执行,当然这里有两个子线,也就是说程序在一开始运行的时候,主线+子线程1+子线程2并发执行。
问:如果我们想有这样一种状态:在程序运行的时候,我们可不可以控制主线程和子线程的运行先后关系呢?
答:答案是肯定的,我们引入“守护”和“阻塞”两个概念。
比如:我们让程序并发后,其中线程1一直去执行,不管主线程和子线程2结束不结束,这就叫做守护,就好像打仗一样,有人掩护你们都撤退了,我再撤退(其实他自己撤退不了)
还是这段代码,我们在thread1.setDaemon方法,这只为True,进行线程守护(备注还可以在Thread里面,在args=后面加入,daemon=True其效果一样的)。
if __name__ == '__main__': thread1 = threading.Thread(target=get_detail_html,args=("",)) thread2 = threading.Thread(target=get_detail_url,args=("",)) thread1.setDaemon(True) # thread2.setDaemon(True) start_time = time.time() thread1.start() thread2.start() print("last time {}".format(time.time()-start_time))
运行结果:
get detail html started get detail url started last time 0.0 ???????????? get detail url end
thread1去哪儿了?还在那里进行守护(活着没活着不知道)。这就是守护的概念。这个线程可以一直运行而不阻塞主程序活着其他子程序的退出。如果一个服务不能很容易的终端线程,或者即使让线程工作到一半时终止也不会造成数据损失或破坏。这个守护线程是非常有用的。
再比如:如果前面有一个守护线程或者没有守护线程,我们在子线程中横叉一杠子,对某一个子线程进行拦截(这里用阻塞的词语),直到完全撤离了再执行到主程序的结束。这就用到了join的方法。
比如阻塞1个
thread1 = threading.Thread(target=get_detail_html,args=("",)) thread2 = threading.Thread(target=get_detail_url,args=("",)) # thread1.setDaemon(True) # thread2.setDaemon(True) start_time = time.time() thread1.start() thread2.start() thread1.join()
打印结果:
get detail html started get detail url started get detail url end get detail html end last time 4.006964206695557
比如阻塞2个:并且换一下位置
thread1 = threading.Thread(target=get_detail_html,args=("",)) thread2 = threading.Thread(target=get_detail_url,args=("",)) # thread1.setDaemon(True) # thread2.setDaemon(True) start_time = time.time() thread1.start()
thread1.join()
thread2.start()
thread2.join()
打印结果:
get detail html started get detail html end get detail url started get detail url end last time 6.0321221351623535
在比如同时守护和阻塞:
thread1 = threading.Thread(target=get_detail_html,args=("",)) thread2 = threading.Thread(target=get_detail_url,args=("",)) thread1.setDaemon(True) thread2.setDaemon(True) start_time = time.time() thread1.start() thread1.join() thread2.start() thread2.join()
打印结果:
get detail html started get detail html end get detail url started get detail url end last time 6.02401328086853
让我们总结一下:阻塞不管阻塞了几个,都会等到全部疏通后再打印主程序的结束;如果前面有守护线程,前面的守护线程仍然活着也要用join阻塞去拯救前面的阻塞线程。另外我们还发现了,join里面是可以传递参数的这里需要传递一个浮点数来控制阻塞的时间,我们通过print来观察。
thread1.start() a1 = time.time() thread1.join() a2 = time.time() print(a2 - a1)
这个阻塞时间如果不设定的话,是和前面的代码中运行的睡眠时间是一致的。如果我们设置阻塞时间为0.1秒钟
thread1.start() a1 = time.time() thread1.join(0.1) a2 = time.time() print(a2 - a1) get detail html started 0.10939979553222656 get detail html end
可以看到是可以控制的。
问:这样看线程增加守护和阻塞是非常必要的,是规矩现在在并发时的先后关系。我们有看到了线程的实例化方式和线程的启动,还有没有其他的使用方式呢?
答:当然我们还可以通过类的继承方式,重洗Thread中的run方法,效果是一样的,这属于一种内嵌的写入方式。记住这里是重写的是Thread这个模块类中的这个方法。
import time import threading class GetDetailHtml(threading.Thread): def __init__(self,name): super().__init__(name=name) def run(self): print("get detail html started") time.sleep(2) print("get detail html end") class GetDetailUrl(threading.Thread): def __init__(self,name): super().__init__(name=name) def run(self): print("get detail Url started") time.sleep(2) print("get detail Url end") if __name__ == '__main__': thread1 = GetDetailHtml("get_detail_html") thread2 = GetDetailHtml("get_detail_url") thread1.start() thread2.start() thread1.join() thread2.join() # get detail html started # get detail html started # get detail html end # get detail html end
我们可以看到和前面的编写方式也是比较适用的,如果我们动态的方式这种方式是比较适用的。另外我们还可通过for循环来循环把任务载入线程,原理很简单后面也会写到
另外我们还可以通过getName方法打印出我们当前线程运行那个任务的名称:这个方式很简单就不在举例了。
问:前面说过了,让两段程序在多线程直接交替执行。那在交替执行的同时,两段程序之间可不可以相互交互数据呢?
答:这就叫做多线程之间的通信。比如两段程序,对应一个数据点,相互交替进行修改的过程就叫做多线程之间的通信,换句话说就是两段动作需要协作来完成一件事情。多线程之间的通信常用的两种方式:第一种:采取全局变量(共享变量)的方式;第二种:采取队列的方式。
第一种:采用全局变量的方式:
import time import threading detail_url_list = [] def get_detail_html(): global detail_url_list url = detail_url_list.pop() print("get detail html started") time.sleep(2) print("get detail html end") def get_detail_url(): global detail_url_list print("get detail url started") time.sleep(2) for i in range(20): detail_url_list.append("http://projectsedu.com/{id}".format(id=i)) print("get detail url end") if __name__ == '__main__': thread_detail_url = threading.Thread(target=get_detail_url) for i in range(10): html_thread =threading.Thread(target=get_detail_html) html_thread.start() # thread_detail_html = threading.Thread(target=)
这种方式是可行的,但其实我们更好的做法是把list这段数据端的数据单独生成一个.py文件,专门用于存放数据有关的.py文件,然后通过import把它引用进来,这样做的安全性会跟高。
import time import threading from chapter11 import variabls def get_detail_html(): detail_url_list = variabls.detail_url_list while True: if len(detail_url_list): url = detail_url_list.pop() print("get detail html started") time.sleep(2) print("get detail html end") def get_detail_url(): detail_url_list = variabls.detail_url_list while True: print("get detail url started") time.sleep(2) for i in range(20): detail_url_list.append("http://projectsedu.com/{id}".format(id=i)) print("get detail url end") if __name__ == '__main__': thread_detail_url = threading.Thread(target=get_detail_url) for i in range(10): html_thread =threading.Thread(target=get_detail_html) html_thread.start() # thread_detail_html = threading.Thread(target=)
第二种:采取队列的方式(这里的队列是用的单端队列,不是双端队列)
import time import threading from queue import Queue def get_detail_html(queue): while True: url = queue.get() # 这是一种阻塞的方法 print("get detail html started") time.sleep(2) print("get detail html end") def get_detail_url(queue): while True: print("get detail url started") time.sleep(2) for i in range(20): queue.put("http://projectsedu.com/{id}".format(id=i)) print("get detail url end") if __name__ == '__main__': detail_url_queue = Queue(maxsize=1000) thread_detail_url = threading.Thread(target=get_detail_url,args=(detail_url_queue,)) for i in range(10): html_thread =threading.Thread(target=get_detail_html,args=(detail_url_queue,)) html_thread.start() detail_url_queue.join() detail_url_queue.task_done()
我们发现queue方法是线程安全的,获取数据采用.get()方法,这个方法从原码我们可以看到是一种阻塞的方式,只有当这个动作完成后,才能进行下面的方式。推入队列的方式我么用的是put方法。
另外,我们在队列当中也可以实现类似于线程中的daemon守护和join阻塞的方式。对应的队列里面是task_done和join方法。当然这些也是需要成对出现的。
问:我们想到了最早的加减问题,因为线程前面有一把GIL的大锁,这把锁并不是排队按照顺序执行的,到一定的逻辑时会出现线程释放的情况导致了计算结果的偏差,我们可不可以控制线程在任务执行时的顺序呢?
答:这就是线程同步的问题,分几个部分来说:
第一部分:关于锁的概念,Lock和RLock
from threading import Lock import threading total = 0 lock = Lock() def add(): global total,lock for i in range(1000000): lock.acquire() total += 1 lock.release() def desc(): global total,lock for i in range(1000000): lock.acquire() total -= 1 lock.release() thread1 = threading.Thread(target=add) thread2 = threading.Thread(target=desc) thread1.start() thread2.start() thread1.join() thread2.join() print(total) # 0
前面的代码我们通过线程锁限制了锁中内容的计算,导致最后结果统一。
不过我们发现加入了锁之后会影响性能,锁会引起死锁。所以我们要注意如下这么几个问题:
第一种问题:
for i in range(1000000): lock.acquire() lock.acquire() total += 1 lock.release()
像这种我们获取了锁,而不释放就会造成死锁
第二种问题:
def add(): global total,lock for i in range(1000000): lock.acquire() dosomething(lock) total += 1 lock.release() def dosomething(lock): lock.acquire() # do something lock.release()
我们发现如果我们再在锁中间再加一把锁,这样做就会产生错误:锁中锁是不允许的!但是Python给我们提供了一种可重入的锁RLock就可以解决这个问题。
可重入的锁RLock:
在同一个线程里面,可以连续调用多次acquire,但是我们一定要注意acquire的次数和release一定要配对。这样我们重新改一下代码,发现不会再报错。
from threading import Lock,RLock import threading total = 0 lock = Lock() rlock = RLock() def add(): global total,lock,rlock for i in range(1000000): lock.acquire() dosomething(rlock) total += 1 lock.release() def dosomething(rlock): rlock.acquire() # do something rlock.release() def desc(): global total,lock for i in range(1000000): lock.acquire() total -= 1 lock.release() thread1 = threading.Thread(target=add) thread2 = threading.Thread(target=desc) thread1.start() thread2.start() thread1.join() thread2.join() print(total)
第二部分:Condition条件变量,用于实现复杂的线程同步
前面我们看到了,第一段函数执行完了,然后释放了,再执行第二段片段。但是我们如果有这么一种情况,我们让两个人来对古诗,你一句我一句。用上面的方法是否还可行呢?
按照这个逻辑我们写一下代码:以天猫和小爱来进行对话:
import threading from threading import Lock class XiaoAi(threading.Thread): def __init__(self,lock): super().__init__(name="小爱") self.lock = lock def run(self): lock.acquire() print("{}:{}".format(self.name, "在")) lock.release() lock.acquire() print("{}:{}".format(self.name, "好啊")) lock.release() class TianMao(threading.Thread): def __init__(self,lock): super().__init__(name="天猫精灵") self.lock = lock def run(self): lock.acquire() print("{}:{}".format(self.name,"小爱同学")) lock.release() lock.acquire() print("{}:{}".format(self.name,"我们在对古诗吧?")) lock.release() if __name__ == '__main__': lock = Lock() tianmao = TianMao(lock) xiaoai = XiaoAi(lock) tianmao.start() xiaoai.start()
我们来查看返回的结果:
天猫精灵:小爱同学
天猫精灵:我们在对古诗吧?
小爱:在
小爱:好啊
并不是我一言你一语的那种对话了吧。这是因为用锁的概念,只能按照顺序来解锁。这就导致了不能交替来执行,因此我们要用条件来解决这个问题。也就是说某一个条件结束了再来解释其他条件,而不能用锁的概念。因此我们需要的是某一种状态的锁定和解锁,而不是像锁这样简单的顺序开锁解锁。
因此在使用条件的话我们要知道的不是acquire和release,而需要的是wait和notify,wait是等待某一个条件变量的通知,notify是通知调用某一个waiti的部分去通知他们启动,我们更改代码如下:(注意我们用condition的时候用的是with语句,这样能够在退出程序的时候自然释放condition状态。)
import threading from threading import Condition class XiaoAi(threading.Thread): def __init__(self,cond): super().__init__(name="小爱") self.cond = cond def run(self): with self.cond: self.cond.wait() print("{}:{}".format(self.name, "在")) self.cond.notify() self.cond.wait() print("{}:{}".format(self.name, "好啊")) class TianMao(threading.Thread): def __init__(self,cond): super().__init__(name="天猫精灵") self.cond = cond def run(self): with self.cond: print("{}:{}".format(self.name,"小爱同学")) self.cond.notify() self.cond.wait() print("{}:{}".format(self.name, "我们对古诗吧?")) self.cond.notify() if __name__ == '__main__': cond = threading.Condition() tianmao = TianMao(cond) xiaoai = XiaoAi(cond) xiaoai.start() tianmao.start()
我们查看输出:
天猫精灵:小爱同学
小爱:在
天猫精灵:我们对古诗吧?
小爱:好啊
这样就实现了我们的对话,但是这里有两点注意:
第一点要使用with语句,如果我们不用with语句的话,前后要加上cond.acquire()和cond.release(),我们采用with语句是非常方便的方式,可以不用考虑释放的问题。当然前面的lock也可以用with语句。因此看with语句是非常方便的。
第二点我们要把小爱先启动,目的是为了等待天猫给他的说话。