在进行图像处理算法中,往往需要生成图像像素矩阵,这对于C语言来说可以直接用数组表示,但是对于verilog来说便不是那么容易了,硬件描述语言不比软件,它的核心不再算法,而是在于设计思想,加速硬件。在进行图像的滤波算法时,需要生成3x3矩阵,而altera的IP shift_ram 简直就是为矩阵运算而生的。下面便进行shift_ram的学习。
手册还是尽量看英文原版的比较好,刚开始是会比较痛苦,看习惯了就会发现,就是那么一些熟悉的单词,句子也很好理解,比较手册又不是文章。

这段话的意思是,这个IP支持一个时钟周期移位一个或多个bit的数据,位宽是可以设置的。
下面这个图是shift_ram的移位示意图,开始我一直以为是这个IP每存储三个数据就会进行移位到下一行,如果这样想当一行图像数据传过来的时候,显然如果是均值滤波的话,这是将第一行的数据进行了取中值操作,这样显然是不符合滤波的原理的。那么从这个图上所表达的貌似就是这个意思,为什么会出现这种矛盾。这也是一直困惑我的地方,还是手册没有好好看,手册上说的很清楚,图下一幅图所示。
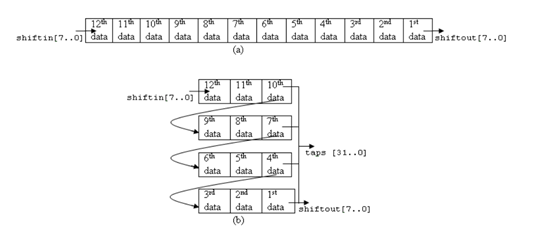

看Note所表明的,这里设置的行数是4行,每行的distance是3,所以便出现了这样的移位寄存,所以手册还是要仔细阅读的,我刚开始就是因为闲手册太麻烦便草草了事,后来实践证明,还是等弄清楚原理在下手操作,磨刀不误砍柴工。
当然手册中也给了仿真例程
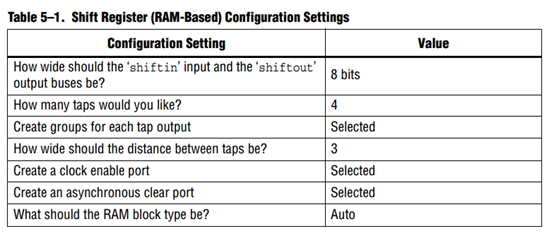
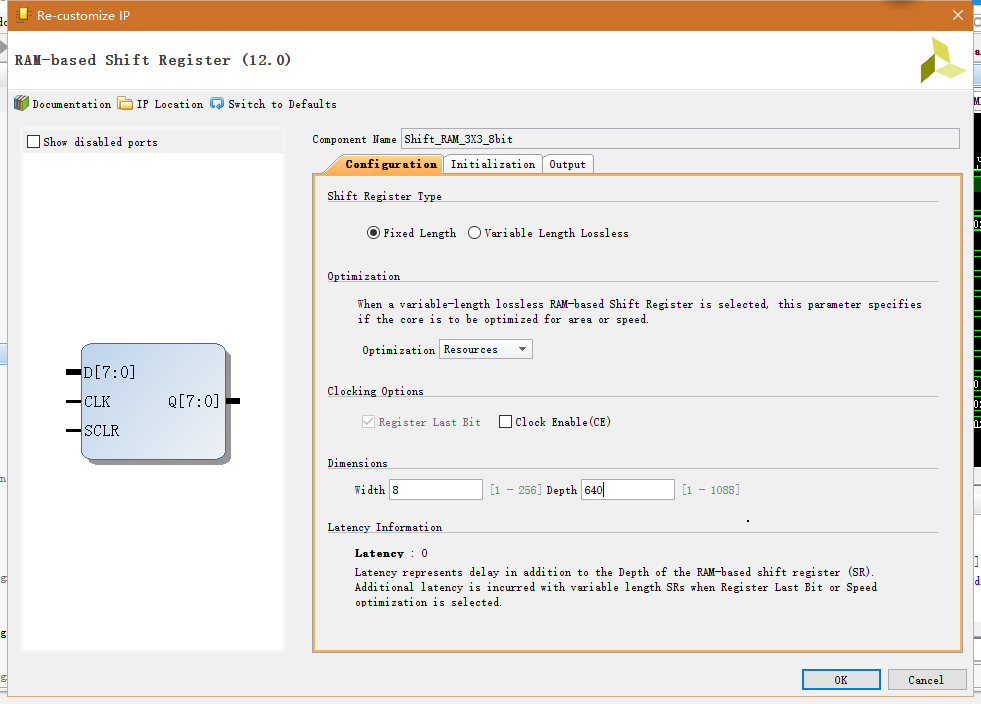
数据输入输出宽度为8bit,设置4行,选择每行宽度为3,添加使能和复位

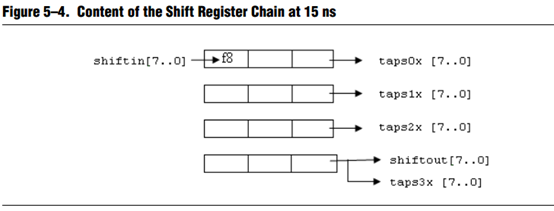
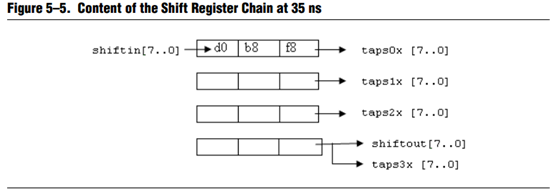

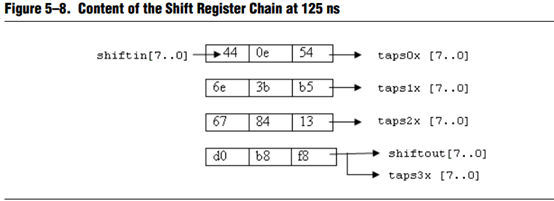
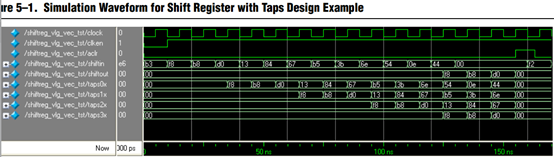
如上图顺序可以容易看出,shift_ram的工作方式是移位存储,后一个数据将前一个数据往前推,当填满一行的时候,跳到下一行再继续移位存储,相应的第一行的数据填满之后,会填上矩阵的第一行的数据,滤波是同时的,如果进行均值滤波的话显然这样目标像素会是0,以此类推,第二行移位存储完成,刚开始第一行的每一个像素点是目标像素,但是第三行还没有数据,所以第一行的目标像素滤波后显然是不准确的,等到把第三行数据填满后,进行原本第二行的滤波,这时目标像素周围均有数据,所以均值滤波会使图像的边缘不清楚。
这是将每一行的宽度设置成3,如果将宽度设置为640,800等分辨率的宽度,那么生成3x3矩阵岂不是十分方便。同样的还可以生成5x5、7x7等矩阵用于图像处理的算法研究。
Xilinx Vivado也有自己的Shift_RAM IP Core,不过这里只能缓存出来一行数据,我们这里需要两个Shift_RAM IP Core和正在输入的一行数据共同组成3行数据。这里调用两个Shift_RAM IP Core将这两个IP级联起来就行了。

对于硬件进行图像处理的算法研究只能进行一些简单的算法处理,对于更加复杂的算法处理,还是要在软件上实现。最近了解到卷积神经网络(CNN),在人工智能领域异常火爆,基于大数据的机器学习,深度学习,FPGA最擅长的就是高速处理数据,在后大数据时代,我相信一定会有FPGA的一个重要地位。

转载请注明出处:NingHeChuan(宁河川)
个人微信订阅号:NingHeChuan
如果你想及时收到个人撰写的博文推送,可以扫描左边二维码(或者长按识别二维码)关注个人微信订阅号
知乎ID:NingHeChuan
微博ID:NingHeChuan