基于zk的分布式锁:
大概原理:仍然跟基于db或者redis一致,就是注册节点,然后删除。不同的是zk因为可以对节点的事件进行监听,那么在收到节点删除的事件时,正在阻塞的线程便可以发起新的抢占锁的请求。当然,真正生产的代码一般不是这么写的,因为这样的情况下如果等待的线程非常多,那么zk向所有注册点的广播就要消耗大量的带宽,也会极大的消耗zk的性能,这显然是不合理的。所以,基于临时有序节点的分布式锁的优势就非常明显了,所有节点只关注自己的前节点,消耗少,线程等待时间可控,而且高可用。
---------Talk Is Cheap, Just Show Me The Code-------------------------------------------------
第一版本的zk分布式锁(做法跟db、redis完全相同):
锁工具类主要方法:
锁的获取:
/**
* 阻塞获取锁
*/
public boolean lock(){
if(tryLock()){
return true;
}
waitForLock();
return lock();
}
/**
* 非阻塞获取锁
*/
public boolean tryLock(){
try{
zkClient.createPersistent("/lock");
System.out.println("抢到了锁"+Thread.currentThread().getName());
}catch (ZkNodeExistsException e){
System.out.println("没抢到锁"+Thread.currentThread().getName());
return false;
}
return true;
}
关键的抢占失败后等待方法:
/**
* 监听节点,等待抢锁
*/
private void waitForLock(){
IZkDataListener listener = new IZkDataListener() {
@Override
public void handleDataChange(String s, Object o) throws Exception {}
@Override
public void handleDataDeleted(String s) throws Exception {
System.out.println("有锁释放了,开始抢占锁"+Thread.currentThread().getName());
if(cdl != null){
cdl.countDown();
}
}
};
zkClient.subscribeDataChanges("/lock",listener);
if(zkClient.exists("/lock")){//节点是否存在
cdl = new CountDownLatch(1);
try {
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}else{//节点可能刚好被删除
lock();
}
}
锁的释放:
/**
* 解锁
*/
public void unlock(){
System.out.println("删除锁"+Thread.currentThread().getName());
zkClient.delete("/lock");
}
测试代码:
private CountDownLatch cdl = new CountDownLatch(num);
@Test
public void testLock(){
for(int i=0;i<num;i++){
MyThread t = new MyThread("mythread"+i);
t.start();
cdl.countDown();
}
try {
Thread.sleep(100000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//内部类
class MyThread extends Thread{
private String threadName;
public MyThread(){};
public MyThread(String threadName){
this.threadName = threadName;
}
@Override
public void run() {
ZkLock zkLock = new ZkLock();
try {
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
if(zkLock.lock()){
System.out.println("线程-"+threadName+"获得锁,orderId为:"+MyResources.getInstance().getNextId());
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
zkLock.unlock();
}
}
}
执行结果一部分如下:
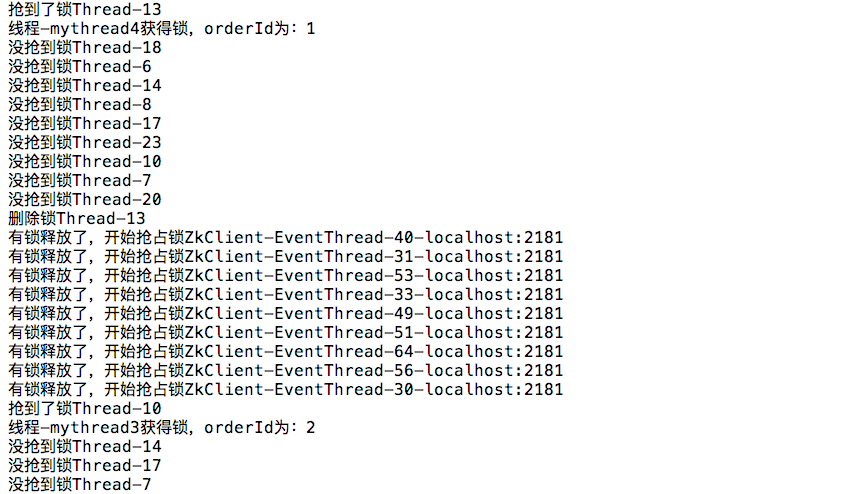
已经不用再说什么了,这么多通知已经说明了一切,每删除一个节点通知所有订阅节点的代价是高昂的,这是不能忍受的,得改!
第二版本的zk分布式锁(临时有序节点版):
/**
* 阻塞锁
* @return
*/
public boolean lock(){
if(tryLock()){
return true;
}else{
waitForLock();
return lock();
}
}
/**
* 非阻塞锁
* @return
*/
public boolean tryLock(){
if(currentPath == null){
currentPath = zkClient.createEphemeralSequential(lockPath+"/lock",Thread.currentThread().getName());
System.out.println(Thread.currentThread().getName()+"创建节点:"+currentPath+"=================================================");
List<String> nodeList = zkClient.getChildren(lockPath);
Collections.sort(nodeList);
if(currentPath.equals(lockPath+"/"+nodeList.get(0))){//当前注册节点为最靠前节点
return true;
}else{
int weizhi = Collections.binarySearch(nodeList,currentPath.substring(8));
beforePath = lockPath +"/"+nodeList.get(weizhi-1);
return false;
}
}else{
return true;
}
}
一样重要的等待方法:
//锁等待
private boolean waitForLock() {
IZkDataListener listener = new IZkDataListener() {
@Override
public void handleDataChange(String s, Object o) throws Exception {
}
@Override
public void handleDataDeleted(String s) throws Exception {
if(cdl!=null){
System.out.println("前面的节点"+beforePath+"被删除了=====================");
cdl.countDown();
}
}
};
zkClient.subscribeDataChanges(beforePath,listener);
if(zkClient.exists(beforePath)){//前节点存在
cdl = new CountDownLatch(1);
try {
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
return false;
}else{//订阅的时候,可能前边线程处理较快,已经删除了
return true;
}
}
释放锁:
/**
* 释放锁
* @return
*/
public boolean unlock(){
return zkClient.delete(currentPath);
}
测试代码:
private int num = 10;
private CountDownLatch cdl = new CountDownLatch(num);
@Test
public void testLock(){
for(int i=0;i<num;i++){
ZkLockTest2.MyThread t = new ZkLockTest2.MyThread("mythread"+i);
t.start();
cdl.countDown();
}
try {
Thread.sleep(1000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//内部类
class MyThread extends Thread{
private String threadName;
public MyThread(){};
public MyThread(String threadName){
this.threadName = threadName;
}
@Override
public void run() {
try {
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
ZkLock2 zkLock = new ZkLock2();
if(zkLock.lock()){
System.out.println("线程-"+threadName+"获得锁,orderId为:"+MyResources.getInstance().getNextId());
zkLock.unlock();
}
}
}
执行结果如下(所有):
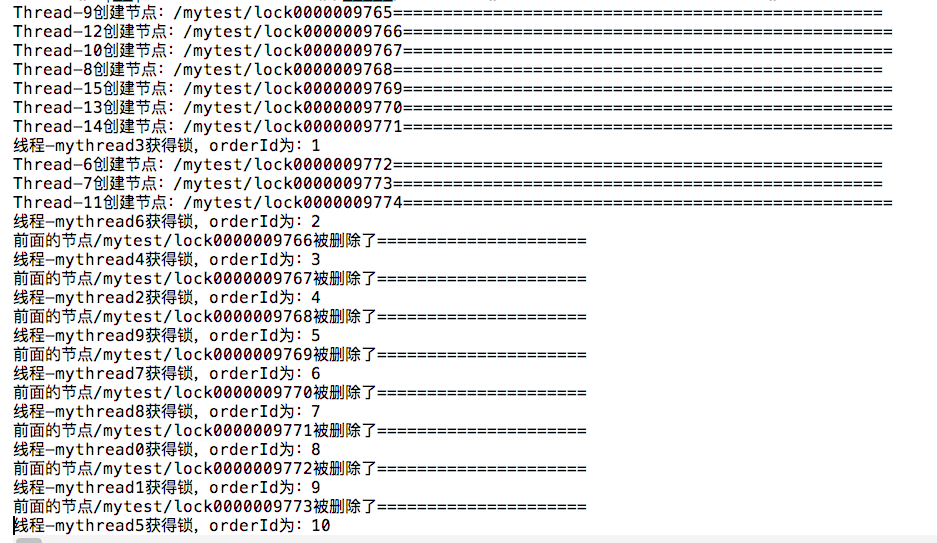
结束语:
三篇结束了,对比三种实现方式结论如下:
a、基于db的分布式锁,相对容易理解,易上手;但依赖数据库,对数据库有损耗(这个影响其实比较小,多数时候可以忽略),可能会有短时间死锁等,其它线程重试的时间不确定,整体时间利用率不好把控(个人认为这个是主要的,其它的可重入,死锁之类的有其它办法解决)。
b、基于redis的分布式锁,性能远高于db的,依赖redis(这个跟db一般不会挂,但就怕万一),主备之间可能数据不一致,一样线程休眠时间不好确定,整体时间利用率不好把控(个人认为这个也是主要原因,解决办法的话,休眠时间设置为正常单线程处理业务时间的2-3倍(经验值),所有线程休眠时间在某个时间段内随机,不要固定时间;其它问题多数可以有办法解决)。
c、基于zk的分布式锁,性能略逊redis但一样远高于db,得益于zk的高可用,不用担心挂掉的问题,而且由于临时有序节点的排序跟节点监听,解决了休眠问题;缺点实现略复杂。
只是自己学习之作,没有考虑生产中具体的需求,可能有理解不正确的地方,欢迎批评斧正。