TCP可靠数据传输
在TCP在IP不可靠的尽力而为的服务之上,创建了一条可靠数据传输服务(reliable data transfer service)。
TCP提供的可靠数据传输的方法涉及到可靠数据传输原理中许多机制。
也涉及到了定时器。如果为每一个已发送但未被确认的报文段都设置一个定时器,那开销是相当巨大的。因此
推荐的定时器管理过程[RFC 6298]仅适用单一的重传定时器。下面描述的TCP协议遵从了这种单一的定时器推荐。
TCP是使用超时和冗余确认技术来恢复报文段的丢失
TCP发送方有3个与发送和重传有关的事件
-
从上层应用程序接收数据
TCP从应用程序接收数据,将数据封装在一个报文段中(含有第一个数据字节的流编号),然后交给IP。 -
定时器超时
超时后,TCP重传超时报文,然后,重启定时器。 -
收到ACK
收到ACK后,将确认报文中确认号与发送方的SendBase(最早未被确认的字节序号)比较。
TCP采取累积确认,所以确认号之前的字节都被接收方收到。
当 确认号 > SendBase 时,则该ACK是在确认一个或多个先前未被确认的报文段,此时发送方更新
SendBase的值
如果当前有未被确认的报文段,TCP重启定时器
TCP协议在工作过程中的几种简单情况
1.由于确认丢失而重传
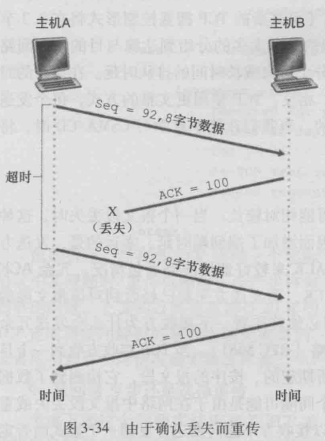
如上图所示,B发送给A的ACK丢失,引起了主机A的重传,B在接收到重传数据报后根据序号得知这是重传报文,于是丢弃该报文,向A发送ACK。
2.连续发送的报文段的ACK延迟
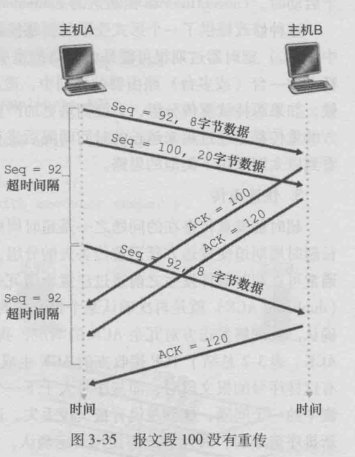
A连续向B发送了两个报文段,但是他们的ACK都延迟了,导致定时器超时,于是最早的未被确认的报文段92被重
传,接着他们的ACK到达,它们就不会被再次重传,A收到确认后,就会将SendBase后移,并重启定时器。
3.累积确认避免先前报文段重传
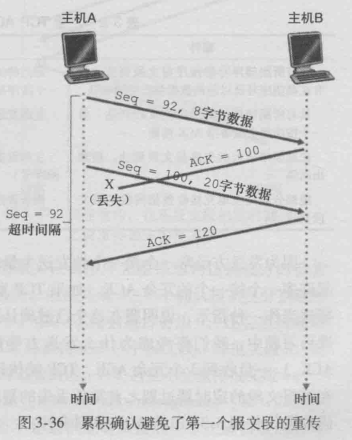
A还是向B连续发送了两个报文段,但是第一个报文段的ACK丢失啦。但是好的是在定时器超时之前,第二个报文
段的ACK到达,因为TCP采取了累计确认,第二个报文段ACK到达,说明了第一个报文段是被正确接收了哒。所以第一个报文段不会被重传。
快速重传
超时重传存在的问题之一就是超时周期可能较长。当一个报文段丢失时,通过超时重传来恢复报文,就会增加端
到端的时延。Luckily,可以通过检测收到的冗余ACK来进行对丢失报文段的重传。
至于为啥可以通过这样的方式来确信此报文段丢失是因为:
①发送方接到丢失报文段后的报文(也就是失序报文段)会将失序报文段缓存,并向发送方发送最近接收的未失
序报文段的最大编号。
②如果接收方连续接收多个失序报文,那么发送方将会收到对一个报文段的多个ACK,由此发送方可知该ACK代
表的报文段的后一个报文丢失了,于是,发送方重传丢失报文。
当发送方收到3个冗余ACK,就说明被确认过三次的报文段之后的那个报文段已经丢失,TCP就执行快重传
(fast retransmit),在丢失报文段定时器超时之前重传丢失报文段。
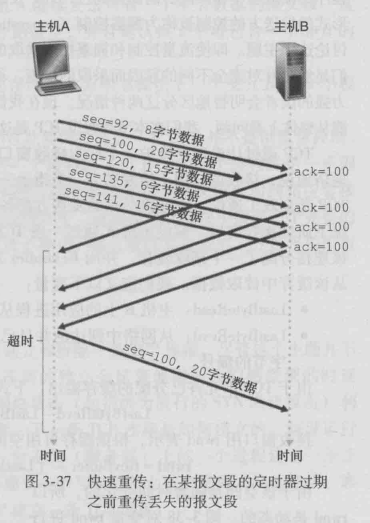
上图是快重传的一个示例
是回退N步还是选择重传
根据前面对TCP描述,可以得知TCP确认是采用累积确认方式,并且对失序报文不会给出确。这让TCP看起来像是一个GBN协议,但是与GBN不同的是,TCP会缓存失序的分组。所以,TCP提出的一种修改意见是选择确认(slective acknowledgment)[RFC 2018],它允许TCP接收方有选择地确认失序报文段,而不是累积确认最后一个正确接收的有序报文段。当将该机制和选择重传机制结合起来使用时(即跳过重传那些已被接收方选择确认过的报文段),TCP就像我们通常的SR协议。
因此,TCP的差错恢复机制为GBN协议和SR协议的混合体。
TCP流量控制
为什么要提供流量控制服务(flow-control service)?
简单地说,提供流控就是为了避免接收方缓存溢出问题。
接收方接收到数据后,会将其放入接收缓存中,待上层应用程序读取数据。但是上层应用可能忙于其他事务或者
读取数据的速度比较慢,而发送方发送数据的太多,速率太快,此时就会导致接收方的缓存溢出。
流量控制也是一个速率匹配服务。
TCP的发送方也可能会因为IP网络拥塞而被遏制,这种形式的控制被称为拥塞控制(congestion control)。这两
种控制是针对不同原因而采取的,尽管他们都是对发送方的遏制。后面会讲他们之间的区别。
TCP如何提供流量控制服务 ?
这里为了从整体上看问题,我们假设,TCP接收方会丢弃失序的报文。
- TCP让发送方A维护一个称为接收窗口(receive window)的变量来提供流量控制。这个窗口代表接收方B有多少可的缓存空间
- 主机A和主机B之间建立TCP连接后,主机B为连接分配了一个接收缓存,用RcvBuffer表示
定义如下变量
- LastByteRead:主机B的应用进程从缓存中取出的数据流最后一个字节的编号
- LastByteRevd:主机B缓存的数据流的最后一个字节编号
缓存不能溢出需满足
LastByteRevd - LastByteRead <= RevBuffer
接收窗口rwnd根据缓存可用空间设置:
rwnd = RevBuffer - [LastByteRevd-LastByteRead]
3. 主机B通过把当前的rwnd放到它发送给主机A的报文段的接收窗口字段,已通知主机A当前它还有多少空间可用。 4. 主机A始终跟踪两个LastByteSend和LastByteAcked,[LastByteSend-LastByteAcked]就是主机A中发送但未被确认的数据量。使这个值小于主机B的rwnd,就可以使主机B的缓存不会溢出。
因此,主机A需要在连接的整个生命周期满足: ``` LastByteSend-LastByteAcked <= rwnd ```
如何防止死锁?
死锁问题出现
主机B的接收缓存满了,rwnd=0。主机A知道了就会暂停数据发送,等待主机B的接收缓存有空闲。如果此时主机B没有数据发送给A那么A将不可能知道主机B会有缓存空闲,这会导致A被阻塞(主机B仅当他有数据发送或者有确认时才会发送报文段给A) !
解决死锁问题
当发送方A收到接收方B的窗口为0的通知,便启动一个一个持续计数器,每隔一段时间向B发送只有一个字节数据的零窗口探测报文段。这些报文段将被接收方确认。最终缓存将开始清空,并且确认报文里包含一个非0的rwnd值。
此文为《计算机网络 自顶向下方法》的学习笔记5,文中图来自本书。