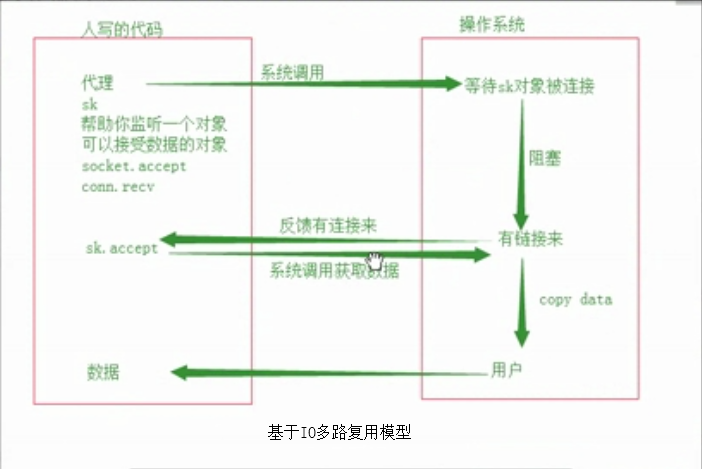
两者相互比较
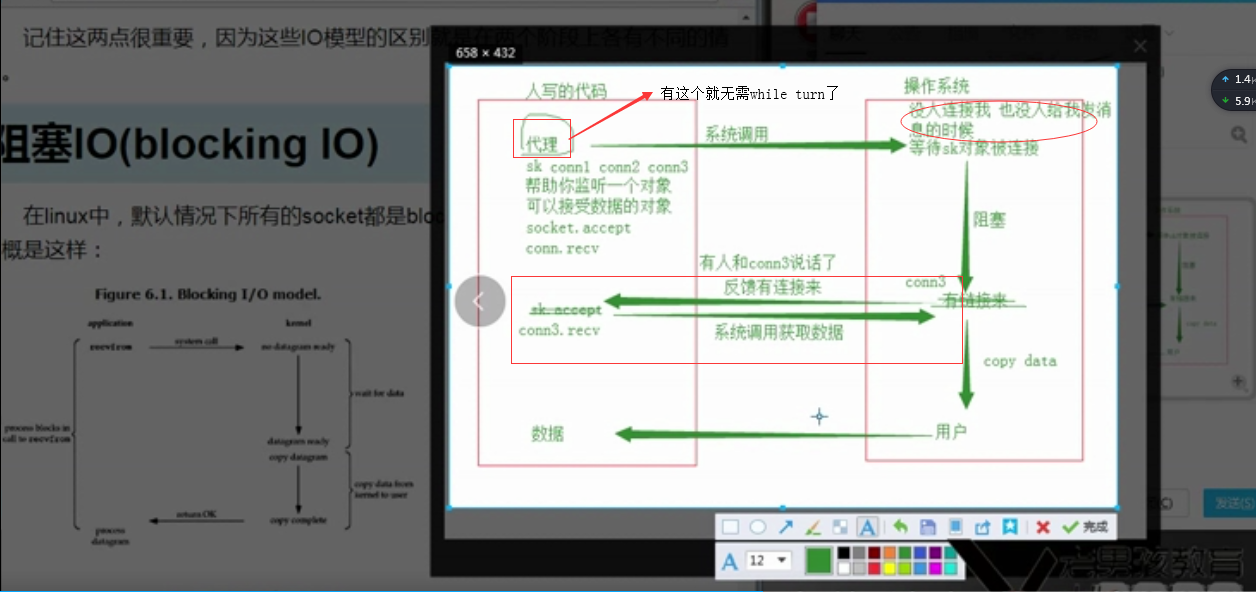
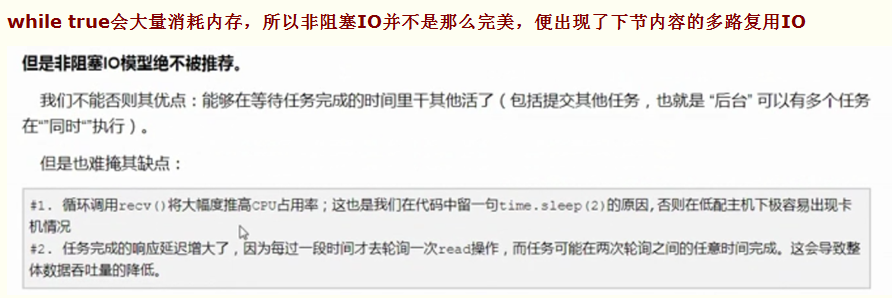
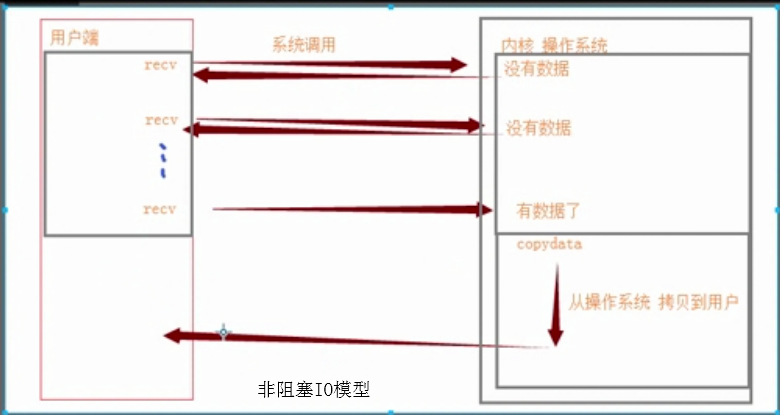
1、如果只有一个用户连接server端,多路复用IO还不如阻塞IO效率高
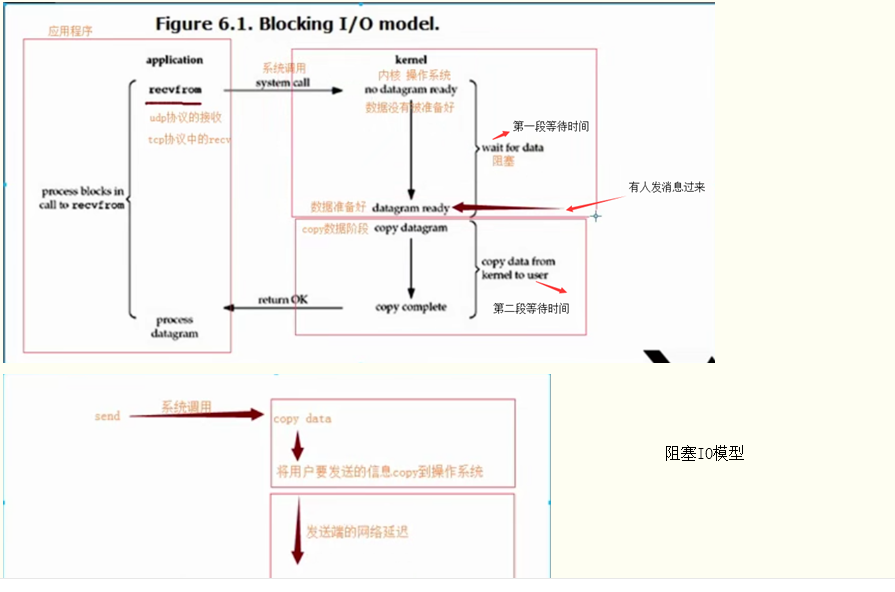
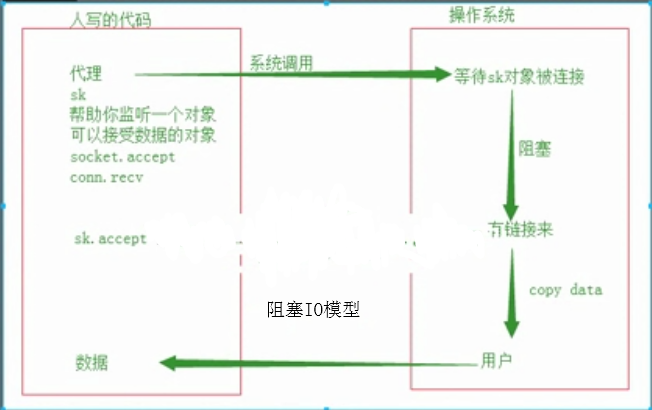
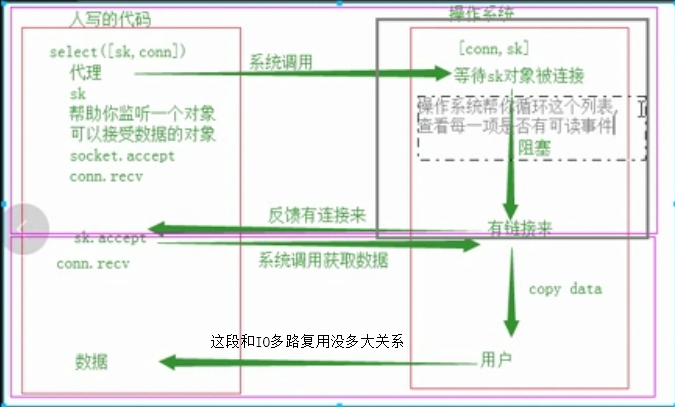
2、相比阻塞IO,多路复用IO中间多了个反馈机制
3、多路复用IO的代码可以同时监控socket、多个socket对象coon1 coon2....、 recv
4、多路复用IO可以识别有人连接某个coon3,然后告知有coon3,然后coon3 recv
5、可以不用while turn(占内存)去循环监听,直接有个代替我去做这些事
6、多路复用IO机制是操作系统提供的,不是代码级别的,win下有专门提供多路复用IO机制select模块来完成【代理】的服务
io多路复用
server端
import select
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8000))
sk.setblocking(False)
sk.listen()
read_lst = [sk]
while True: # [sk,conn]
r_lst,w_lst,x_lst = select.select(read_lst,[],[])
for i in r_lst:
if i is sk:
conn,addr = i.accept()
read_lst.append(conn)
else:
ret = i.recv(1024)
if ret == b'':
i.close()
read_lst.remove(i)
continue
print(ret)
i.send(b'goodbye!')
client端
import time
import socket
import threading
def func():
sk = socket.socket()
sk.connect(('127.0.0.1',8000))
sk.send(b'hello')
time.sleep(3)
print(sk.recv(1024))
sk.close()
for i in range(20):
threading.Thread(target=func).start()
这种并发是使用IO多路复用机制来实现并发的socket的server,并不是牺牲CPU的使用率来实现的,而是利用操作系统提供的IO多路复用的机制
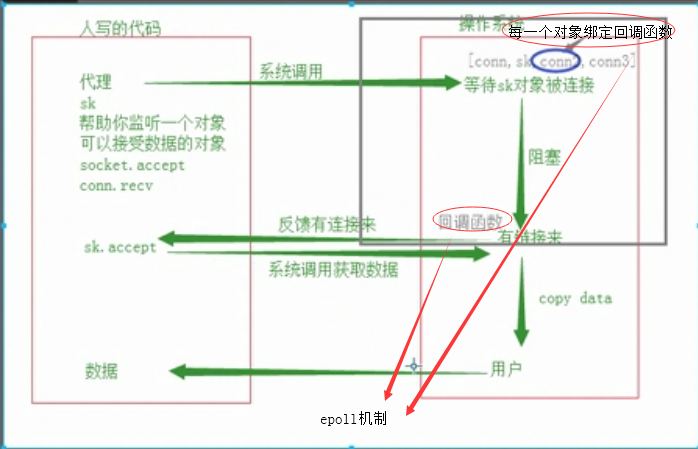
# IO多路复用(在win下并不是很高效)
# select机制 Windows 和 linux 都有 都是操作系统轮询每一个被监听的项,看是否有读操作
# poll机制 linux 它可以监听的对象比select机制可以监听的多
# 随着监听项的增多,导致效率降低
# epoll机制 linux 对每一个列表监听的对象绑定一个回调函数,回调函数来反馈有人来链接(Linux下推荐使用)
为了代码的可用于适用不同系统机制,出现selector,根据系统自动选择对于的IO多路复用机制(selector_demo)
import selectors
from socket import *
def accept(sk,mask):
conn,addr=sk.accept()
sel.register(conn,selectors.EVENT_READ,read)
def read(conn,mask):#一般使用我们只需要变动这段内容就好,其他不用变
try:
data=conn.recv(1024)
if not data:
print('closing',conn)
sel.unregister(conn)
conn.close()
return
conn.send(data.upper()+b'_SB')
except Exception:
print('closing', conn)
sel.unregister(conn)
conn.close()
sk=socket()
sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
sk.bind(('127.0.0.1',8088))
sk.listen(5)
sk.setblocking(False) #设置socket的接口为非阻塞
sel=selectors.DefaultSelector() # 选择一个适合我的IO多路复用的机制
sel.register(sk,selectors.EVENT_READ,accept)
#相当于网select的读列表里append了一个sk对象,并且绑定了一个回调函数accept
# 说白了就是 如果有人请求连接sk,就调用accept方法
while True:
events=sel.select() #检测所有的sk,conn,是否有完成wait data阶段,这里没SK对象是阻塞,当有SK对象时走下面的for
for sel_obj,mask in events: # [SK] [conn]
callback=sel_obj.data #callback=read
callback(sel_obj.fileobj,mask) #read(conn,1)
站在python角度,不太好实现异步框架,因为在copy date阶段未提供对于python接口
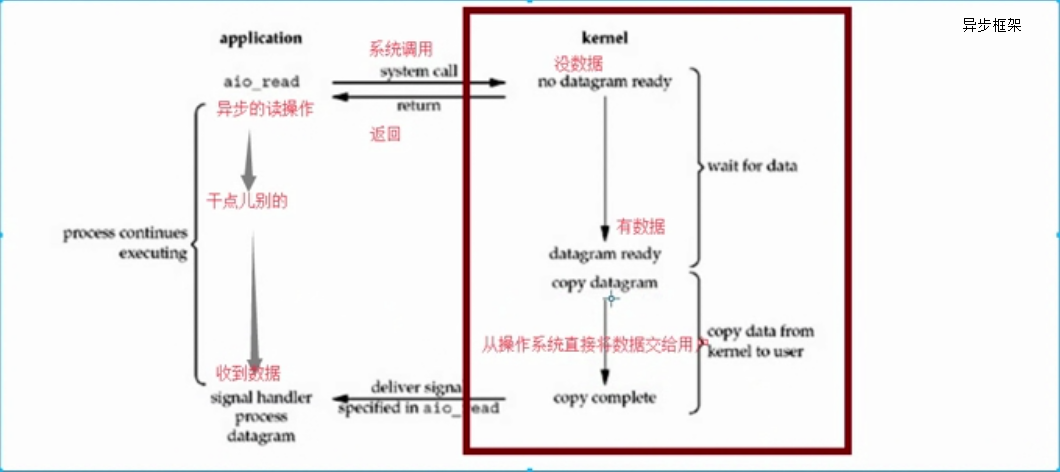
当我们web开发server端时,如果预计可能每秒的访问量比较大时,这时候我们就不要选择diango框架(非异步框架),应该选择 tornade(或 twstied)异步IO框架(没有wait date和copy date阻塞阶段,能响应更多的请求)