1. sift.detectAndComputer(gray, None) # 计算出图像的关键点和sift特征向量
参数说明:gray表示输入的图片
2.cv2.findHomography(kpA, kpB, cv2.RANSAC, reproThresh) # 计算出单应性矩阵
参数说明:kpA表示图像A关键点的坐标, kpB图像B关键点的坐标, 使用随机抽样一致性算法来进行迭代,reproThresh表示每次抽取样本的个数
3.cv2.warpPespective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageA.shape[0])) # 获得根据单应性矩阵变化后的图像
参数说明:image表示输入图像,H表示单应性的矩阵,(imageA.shape[1] + imageB.shape[1], imageA.shape[0])表示矩阵变化后的维度
4. cv2.line(imageA, kpsA, imageB, kpsB, (0,0,255), 2) 进行画出直线的操作
参数说明:imageA和imageB表示输入图片, kpsA和kpsB表示关键点的坐标(x, y) ,(0, 0, 255)表示颜色, 2表示直线的宽度
RANSAC算法(随机抽样一致性算法), 对于左边的图,可以看到使用最小二乘法尽可能多的满足点可以分布在拟合曲线周围,减小均分根误差,因此拟合的曲线在一定程度上容易发生偏离,而RANSAC却不会出现这种情况
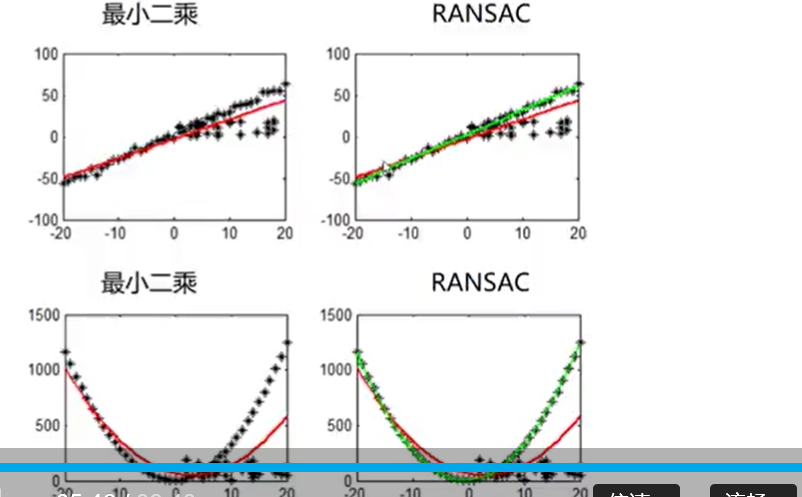
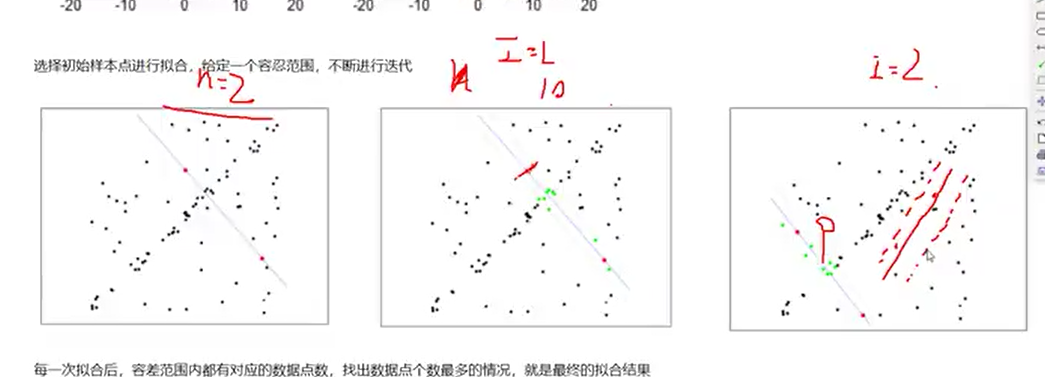
RANSCA原理, 因为拟合一条直线只需要两个点,因此我们每次随机选取两个点,做出直线,划定一个距离,判断落在直线周围距离范围点的个数,不断的迭代,直到找出拟合的直线,使得点落在上面最多的拟合曲线
图像拼接的关键是在于对图像进行变化,变化后的点与需要拼接的图片中的sift点,越接近,即欧式距离越短,对图像拼接的过程中,至少需要有4对特征点,求取变化矩阵Hi
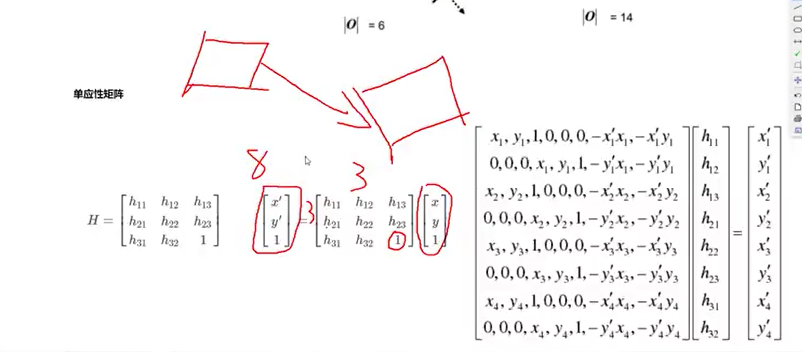
我们使用RANSAC不断去取随机从两个图像中取4对的sift特征点,计算出H,定义损失值,即x’,与x的距离,即y‘与y的距离之和是否是最小值,不断迭代,找出最佳的H
上述就是计算出来了H值,也就是变化矩阵
代码思路:
第一步:对图像进行灰度化,使用sift.detectAndCompute(image, None) 进行ksp关键点,dpSIFT特征向量,将kps进行向量化操作,即kps.pt
第二步:构建BMFmatch匹配器,获得符合条件的匹配值,matches获得的是ksp关键点的匹配值得索引,使用索引获得符合条件的kspA和kspB
第三步:使用cv2.findHomography(kpA, kpB, cv2.RANSAC,reproThresh) 随机抽取4个点,求得最合适的H变化矩阵
第四步:使用获得的变化矩阵H, cv.warpPerspective 对imageA求取变化后的图像
第五步:将imageB加入到变化后的图像获得最终图像
第六步:如果需要进行展示,构造新的图像,尺寸为imageA.shape[0], imageB.shape[1] +imageA.shape[1], 使用matches的索引,使用cv2.line将符合条件的点进行连接
第七步:返回最终的结果,进行画图展示
import cv2 import numpy as np import matplotlib.pyplot as plt class Stitcher: def stitch(self, imgs, ratio=0.75, reproThresh=4, showMathes = False): (imageB, imageA) = imgs # 第一步:计算kpsA和dpsA (kpsA, dpsA) = self.detectandcompute(imageA) (kpsB, dpsB) = self.detectandcompute(imageB) # 获得变化的矩阵H M = self.matchKeypoint(kpsA, dpsA, kpsB, dpsB, ratio, reproThresh) if M is None: return None (matches, H, status) = M # 第四步:使用cv2.warpPerspective获得经过H变化后的图像 result = cv2.warpPerspective(imageA, H, (imageA.shape[1] + imageB.shape[1], imageB.shape[0])) # 第五步:将图像B填充到进过H变化后的图像,获得最终的图像 result[0:imageB.shape[0], 0:imageB.shape[1]] = imageB if showMathes: # 第六步:对图像的关键点进行连接 via = self.showMatches(imageA, imageB, kpsA, kpsB, matches, status) return (via, result) return result # 进行画图操作 def showMatches(self, imageA, imageB, kpsA, kpsB, matches, status): # 将两个图像进行拼接 # 根据图像的大小,构造全零矩阵 via = np.zeros((max(imageB.shape[0], imageA.shape[0]), imageA.shape[1] + imageB.shape[1], 3), np.uint8) # 将图像A和图像B放到全部都是零的图像中 via[0:imageA.shape[0], 0:imageA.shape[1]] = imageA via[0:imageB.shape[0], imageA.shape[1]:] = imageB # 根据matches中的索引,构造出点的位置信息 for (trainIdx, queryIdx), s in zip(matches, status): if s==1: ptA = (int(kpsA[queryIdx][0]), int(kpsA[queryIdx][1])) ptB = (int(kpsB[trainIdx][0] + imageA.shape[1]), int(kpsB[trainIdx][1])) # 使用cv2.line进行画图操作 cv2.line(via, ptA, ptB, (0, 255, 0), 1) return via def matchKeypoint(self, kpsA, dpsA, kpsB, dpsB, ratio, reproThresh): # 第二步:实例化BFM匹配, 找出符合添加的关键点的索引 bf = cv2.BFMatcher() matcher = bf.knnMatch(dpsA, dpsB, 2) matches = [] for match in matcher: if len(match) == 2 and match[0].distance < match[1].distance * ratio: # 加入match[0]的索引 matches.append((match[0].trainIdx, match[0].queryIdx)) #第三步:使用cv2.findHomography找出符合添加的H矩阵 if len(matches) > 4: # 根据索引找出符合条件的位置 kpsA = np.float32([kpsA[i] for (_, i) in matches]) kpsB = np.float32([kpsB[i] for (i, _) in matches]) (H, status) = cv2.findHomography(kpsA, kpsB, cv2.RANSAC, reproThresh) return (matches, H, status) return None def cv_show(self, img, name): cv2.imshow(name, img) def detectandcompute(self, image): # 进行灰度值转化 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) #实例化sift函数 sift = cv2.xfeatures2d.SIFT_create() # 获得kps关键点和dps特征向量sift kps, dps = sift.detectAndCompute(gray, None) # 获得特征点的位置信息, 并转换数据类型 kps = np.float32([kp.pt for kp in kps]) return (kps, dps)



使用cv2.warpPesctive即根据H变化后的图片 经过图像拼接后的result图片 经过图片关键点连接的图片