一.模块介绍:
1.模块和包的定义:
模块用来从逻辑上组织python代码(变量,函数,类,逻辑:实现一个功能),本质就是.py结尾的python文件(文件名:test.py,对应的模块名:test)
包用来从逻辑上组织模块的,本质就是一个目录(必须带有一个__init__.py文件)
2.导入模块:
本质:导入模块的本质就是把python文件解释一遍;导入包的本质就是执行该包下的__init__.py文件
import module_name
import module1_name,module2_name
from module_alex import *
from module_alex import m1,m2,m3
from module_alex import logger as logger_alex
二.内置模块
1.time模块和datetime模块
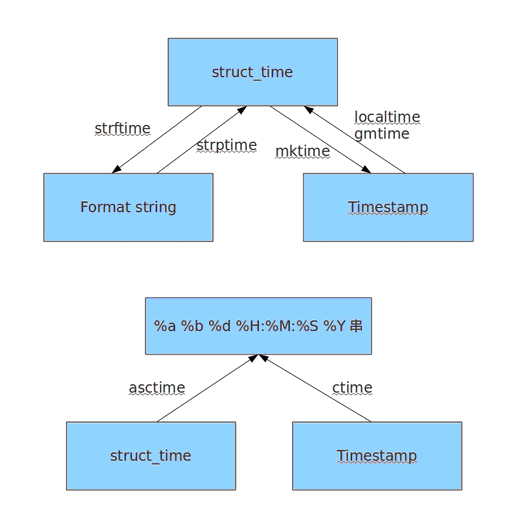
时间的三种表达方式:
♦ 时间戳(Timestamp) 1970年1月1日之后的秒,即:time.time()
♦ 格式化的时间字符串(Format string) 2017-09-22 15:49:52,即:time.strftime('%Y-%m-%d %H:%M:%S')
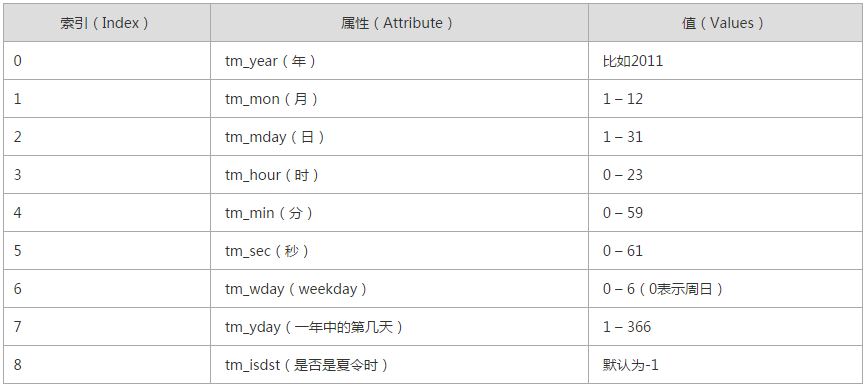
♦ 结构化时间(struct_time) 元组包含了:年,月,日,星期等9个元素,即:time.localtime()
time模块:


1 import time 2 3 print(time.time()) #时间戳 4 #1506067599.577602 5 6 time.sleep(3) #时间延迟3秒 7 8 print(time.gmtime(1231231234)) #时间戳------->结构化时间 返回UTC时间 9 #time.struct_time(tm_year=2009, tm_mon=1, tm_mday=6, tm_hour=8, tm_min=40, tm_sec=34, tm_wday=1, tm_yday=6, tm_isdst=0) 10 11 print(time.localtime(1231231234)) #时间戳------->结构化时间 返回本地时间 12 #time.struct_time(tm_year=2009, tm_mon=1, tm_mday=6, tm_hour=16, tm_min=40, tm_sec=34, tm_wday=1, tm_yday=6, tm_isdst=0) 13 14 print(time.asctime()) #传入的是结构化时间 15 #Fri Sep 22 16:30:11 2017 16 17 print(time.ctime()) 18 #Fri Sep 22 16:30:52 2017 #传入的是时间戳 19 20 #结构化时间转换为字符串格式 21 # strftime(format[, tuple]) -> string 22 print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime())) 23 print(time.strftime('%Y-%m-%d %H:%M:%S')) 24 #2017-09-22 16:49:28 25 #2017-09-22 16:49:28 26 27 #字符串格式转换为结构化时间 28 #strptime(string, format) -> struct_time 29 print(time.strptime('1990-08-24','%Y-%m-%d')) 30 #time.struct_time(tm_year=1990, tm_mon=8, tm_mday=24, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=236, tm_isdst=-1) 31 32 x = time.strptime('1990-08-24','%Y-%m-%d') 33 print(time.mktime(x)) #结构化时间转化为时间戳 34 #651427200.0
结构化时间:
时间戳、格式化字符串、结构化时间相互转换:
datetime模块:
1 import datetime 2 3 print(datetime.date) #表示日期的类,常用的属性有year,month,day 4 #<class 'datetime.date'> 5 print(datetime.time) #表示时间的类,常用的属性有hour,minute,second,microsecond 6 #<class 'datetime.time'> 7 print(datetime.datetime) #表示日期时间 8 #<class 'datetime.datetime'> 9 print(datetime.timedelta) #表示时间间隔 10 #<class 'datetime.timedelta'> 11 12 print(datetime.datetime.now()) 13 #2017-09-25 13:41:17.307477 14 print(datetime.datetime.now() + datetime.timedelta(-3)) #三天前的时间,可以以此类推修改时间,如:hours=3 15 #2017-09-22 13:41:17.307477 16 17 c_time = datetime.datetime.now() 18 print(c_time) 19 #2017-09-25 13:49:38.505144 20 print(c_time.replace(minute=1,hour=5)) #时间替换 21 #2017-09-25 05:01:38.505144
2.random模块:
生成随机数:
1 import random 2 3 print(random.random()) #生成0~1的随机数 4 #0.626012024763689 5 6 print(random.randint(1,4)) #生成1~4随机整数 7 #3 8 9 print(random.randrange(1,4)) #生成1~3随机整数,不包含4 10 #1 11 12 print(random.choice('hello')) #随机选择字符串 13 #l 14 15 print(random.sample('hello',2)) #随机选取特定的字符 16 #['l', 'o'] 17 18 items = [1,2,3,4,5,6,7] 19 random.shuffle(items) #洗牌,重新排序 20 print(items) 21 #[2, 3, 6, 5, 4, 7, 1] 22 23 print(random.uniform(1,10)) #生成1~10的随机浮点数 24 #5.136551625292955
验证码:
1 方法一: 2 import random 3 4 5 checkcode = '' 6 for i in range(4): 7 current = random.randint(0,3) 8 if i == current: 9 temp = chr(random.randint(65,90)) #ascii转化为字母 10 else: 11 temp = random.randint(0,9) 12 checkcode += str(temp) 13 14 print(checkcode) 15 16 方法二: 17 import random 18 19 list = [1,2,3,4,5,6,7,8,9,'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'] 20 x = random.sample(list,6) 21 for i in x: 22 print(i,end='') #打印不换行,end=''
3.os模块:
1 import os 2 3 os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径 4 os.chdir("dirname") # 改变当前脚本工作目录;相当于shell下cd 5 os.curdir # 返回当前目录: ('.') 6 os.pardir # 获取当前目录的父目录字符串名:('..') 7 os.makedirs('dirname1/dirname2') # 可生成多层递归目录 8 os.removedirs('dirname1') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 9 os.mkdir('dirname') # 生成单级目录;相当于shell中mkdir dirname 10 os.rmdir('dirname') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 11 os.listdir('dirname') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 12 os.remove() # 删除一个文件 13 os.rename("oldname", "newname") # 重命名文件/目录 14 os.stat('path/filename') # 获取文件/目录信息 15 os.sep # 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/" 16 os.linesep # 输出当前平台使用的行终止符,win下为" ",Linux下为" " 17 os.pathsep # 输出用于分割文件路径的字符串 18 os.name # 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' 19 os.system("bash command") # 运行shell命令,直接显示 20 os.environ # 获取系统环境变量 21 os.path.abspath(path) # 返回path规范化的绝对路径 22 os.path.split(path) # 将path分割成目录和文件名二元组返回 23 os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素 24 os.path.basename(path) # 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素 25 os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False 26 os.path.isabs(path) # 如果path是绝对路径,返回True 27 os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False 28 os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False 29 os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 30 os.path.getatime(path) # 返回path所指向的文件或者目录的最后存取时间 31 os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间
4.sys模块:
1 import sys 2 3 sys.argv #命令行参数List,第一个元素是程序本身路径 4 sys.exit(n) #退出程序,正常退出时exit(0) 5 sys.version # 获取Python解释程序的版本信息 6 sys.maxint #最大的Int值 7 sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 8 sys.platform #返回操作系统平台名称 9 sys.stdout.write('please:') 10 val = sys.stdin.readline()[:-1]
5.shutil模块:
高级的 文件,文件夹,压缩包 处理模块
① shutil.copyfileobj 将文件内容拷贝到另一个文件中,可以部分内容
1 def copyfileobj(fsrc, fdst, length=16*1024): 2 """copy data from file-like object fsrc to file-like object fdst""" 3 while 1: 4 buf = fsrc.read(length) 5 if not buf: 6 break 7 fdst.write(buf)
1 #shutil 文件拷贝 2 import shutil 3 4 f1 = open("fsrc",encoding="utf-8") 5 6 f2 = open("fdst","w",encoding="utf-8") 7 8 shutil.copyfileobj(f1,f2) 9 10 #把f1的内容拷贝到f2
②shutil.copyfile 文件拷贝
1 def copyfile(src, dst): 2 """Copy data from src to dst""" 3 if _samefile(src, dst): 4 raise Error("`%s` and `%s` are the same file" % (src, dst)) 5 6 for fn in [src, dst]: 7 try: 8 st = os.stat(fn) 9 except OSError: 10 # File most likely does not exist 11 pass 12 else: 13 # XXX What about other special files? (sockets, devices...) 14 if stat.S_ISFIFO(st.st_mode): 15 raise SpecialFileError("`%s` is a named pipe" % fn) 16 17 with open(src, 'rb') as fsrc: 18 with open(dst, 'wb') as fdst: 19 copyfileobj(fsrc, fdst)
1 import shutil 2 3 shutil.copyfile("fsrc","fdst2") 4 5 #把文件fsrc的内容拷贝到fdst2中
③ shutil.copymode(src, dst) 仅拷贝权限。内容、组、用户均不变
1 def copymode(src, dst): 2 """Copy mode bits from src to dst""" 3 if hasattr(os, 'chmod'): 4 st = os.stat(src) 5 mode = stat.S_IMODE(st.st_mode) 6 os.chmod(dst, mode)
④ shutil.copystat(src, dst) 拷贝状态的信息,包括:mode bits, atime, mtime, flags
1 def copystat(src, dst): 2 """Copy all stat info (mode bits, atime, mtime, flags) from src to dst""" 3 st = os.stat(src) 4 mode = stat.S_IMODE(st.st_mode) 5 if hasattr(os, 'utime'): 6 os.utime(dst, (st.st_atime, st.st_mtime)) 7 if hasattr(os, 'chmod'): 8 os.chmod(dst, mode) 9 if hasattr(os, 'chflags') and hasattr(st, 'st_flags'): 10 try: 11 os.chflags(dst, st.st_flags) 12 except OSError, why: 13 for err in 'EOPNOTSUPP', 'ENOTSUP': 14 if hasattr(errno, err) and why.errno == getattr(errno, err): 15 break 16 else: 17 raise
⑤ shutil.copy(src, dst) 拷贝文件和权限
1 def copy(src, dst): 2 """Copy data and mode bits ("cp src dst"). 3 4 The destination may be a directory. 5 6 """ 7 if os.path.isdir(dst): 8 dst = os.path.join(dst, os.path.basename(src)) 9 copyfile(src, dst) 10 copymode(src, dst)
⑥ shutil.copy2(src, dst) 拷贝文件和状态信息
1 def copy2(src, dst): 2 """Copy data and all stat info ("cp -p src dst"). 3 4 The destination may be a directory. 5 6 """ 7 if os.path.isdir(dst): 8 dst = os.path.join(dst, os.path.basename(src)) 9 copyfile(src, dst) 10 copystat(src, dst)
⑦ shutil.copytree(src, dst, symlinks=False, ignore=None) 递归的去拷贝文件 拷贝多层目录
1 def ignore_patterns(*patterns): 2 """Function that can be used as copytree() ignore parameter. 3 4 Patterns is a sequence of glob-style patterns 5 that are used to exclude files""" 6 def _ignore_patterns(path, names): 7 ignored_names = [] 8 for pattern in patterns: 9 ignored_names.extend(fnmatch.filter(names, pattern)) 10 return set(ignored_names) 11 return _ignore_patterns 12 13 def copytree(src, dst, symlinks=False, ignore=None): 14 """Recursively copy a directory tree using copy2(). 15 16 The destination directory must not already exist. 17 If exception(s) occur, an Error is raised with a list of reasons. 18 19 If the optional symlinks flag is true, symbolic links in the 20 source tree result in symbolic links in the destination tree; if 21 it is false, the contents of the files pointed to by symbolic 22 links are copied. 23 24 The optional ignore argument is a callable. If given, it 25 is called with the `src` parameter, which is the directory 26 being visited by copytree(), and `names` which is the list of 27 `src` contents, as returned by os.listdir(): 28 29 callable(src, names) -> ignored_names 30 31 Since copytree() is called recursively, the callable will be 32 called once for each directory that is copied. It returns a 33 list of names relative to the `src` directory that should 34 not be copied. 35 36 XXX Consider this example code rather than the ultimate tool. 37 38 """ 39 names = os.listdir(src) 40 if ignore is not None: 41 ignored_names = ignore(src, names) 42 else: 43 ignored_names = set() 44 45 os.makedirs(dst) 46 errors = [] 47 for name in names: 48 if name in ignored_names: 49 continue 50 srcname = os.path.join(src, name) 51 dstname = os.path.join(dst, name) 52 try: 53 if symlinks and os.path.islink(srcname): 54 linkto = os.readlink(srcname) 55 os.symlink(linkto, dstname) 56 elif os.path.isdir(srcname): 57 copytree(srcname, dstname, symlinks, ignore) 58 else: 59 # Will raise a SpecialFileError for unsupported file types 60 copy2(srcname, dstname) 61 # catch the Error from the recursive copytree so that we can 62 # continue with other files 63 except Error, err: 64 errors.extend(err.args[0]) 65 except EnvironmentError, why: 66 errors.append((srcname, dstname, str(why))) 67 try: 68 copystat(src, dst) 69 except OSError, why: 70 if WindowsError is not None and isinstance(why, WindowsError): 71 # Copying file access times may fail on Windows 72 pass 73 else: 74 errors.append((src, dst, str(why))) 75 if errors: 76 raise Error, errors
⑧ shutil.rmtree(path[, ignore_errors[, onerror]]) 递归的去删除文件
1 def rmtree(path, ignore_errors=False, onerror=None): 2 """Recursively delete a directory tree. 3 4 If ignore_errors is set, errors are ignored; otherwise, if onerror 5 is set, it is called to handle the error with arguments (func, 6 path, exc_info) where func is os.listdir, os.remove, or os.rmdir; 7 path is the argument to that function that caused it to fail; and 8 exc_info is a tuple returned by sys.exc_info(). If ignore_errors 9 is false and onerror is None, an exception is raised. 10 11 """ 12 if ignore_errors: 13 def onerror(*args): 14 pass 15 elif onerror is None: 16 def onerror(*args): 17 raise 18 try: 19 if os.path.islink(path): 20 # symlinks to directories are forbidden, see bug #1669 21 raise OSError("Cannot call rmtree on a symbolic link") 22 except OSError: 23 onerror(os.path.islink, path, sys.exc_info()) 24 # can't continue even if onerror hook returns 25 return 26 names = [] 27 try: 28 names = os.listdir(path) 29 except os.error, err: 30 onerror(os.listdir, path, sys.exc_info()) 31 for name in names: 32 fullname = os.path.join(path, name) 33 try: 34 mode = os.lstat(fullname).st_mode 35 except os.error: 36 mode = 0 37 if stat.S_ISDIR(mode): 38 rmtree(fullname, ignore_errors, onerror) 39 else: 40 try: 41 os.remove(fullname) 42 except os.error, err: 43 onerror(os.remove, fullname, sys.exc_info()) 44 try: 45 os.rmdir(path) 46 except os.error: 47 onerror(os.rmdir, path, sys.exc_info())
⑨ shutil.move(src, dst) 递归的去移动文件
1 def move(src, dst): 2 """Recursively move a file or directory to another location. This is 3 similar to the Unix "mv" command. 4 5 If the destination is a directory or a symlink to a directory, the source 6 is moved inside the directory. The destination path must not already 7 exist. 8 9 If the destination already exists but is not a directory, it may be 10 overwritten depending on os.rename() semantics. 11 12 If the destination is on our current filesystem, then rename() is used. 13 Otherwise, src is copied to the destination and then removed. 14 A lot more could be done here... A look at a mv.c shows a lot of 15 the issues this implementation glosses over. 16 17 """ 18 real_dst = dst 19 if os.path.isdir(dst): 20 if _samefile(src, dst): 21 # We might be on a case insensitive filesystem, 22 # perform the rename anyway. 23 os.rename(src, dst) 24 return 25 26 real_dst = os.path.join(dst, _basename(src)) 27 if os.path.exists(real_dst): 28 raise Error, "Destination path '%s' already exists" % real_dst 29 try: 30 os.rename(src, real_dst) 31 except OSError: 32 if os.path.isdir(src): 33 if _destinsrc(src, dst): 34 raise Error, "Cannot move a directory '%s' into itself '%s'." % (src, dst) 35 copytree(src, real_dst, symlinks=True) 36 rmtree(src) 37 else: 38 copy2(src, real_dst) 39 os.unlink(src)
⑩ shutil.make_archive(base_name, format,...) 创建压缩包并返回文件路径,例如:zip、tar
▪ base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:www =>保存至当前路径
如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/
▪ format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
▪ root_dir: 要压缩的文件夹路径(默认当前目录)
▪ owner: 用户,默认当前用户
▪ group: 组,默认当前组
▪ logger: 用于记录日志,通常是logging.Logger对象
1 def make_archive(base_name, format, root_dir=None, base_dir=None, verbose=0, 2 dry_run=0, owner=None, group=None, logger=None): 3 """Create an archive file (eg. zip or tar). 4 5 'base_name' is the name of the file to create, minus any format-specific 6 extension; 'format' is the archive format: one of "zip", "tar", "bztar" 7 or "gztar". 8 9 'root_dir' is a directory that will be the root directory of the 10 archive; ie. we typically chdir into 'root_dir' before creating the 11 archive. 'base_dir' is the directory where we start archiving from; 12 ie. 'base_dir' will be the common prefix of all files and 13 directories in the archive. 'root_dir' and 'base_dir' both default 14 to the current directory. Returns the name of the archive file. 15 16 'owner' and 'group' are used when creating a tar archive. By default, 17 uses the current owner and group. 18 """ 19 save_cwd = os.getcwd() 20 if root_dir is not None: 21 if logger is not None: 22 logger.debug("changing into '%s'", root_dir) 23 base_name = os.path.abspath(base_name) 24 if not dry_run: 25 os.chdir(root_dir) 26 27 if base_dir is None: 28 base_dir = os.curdir 29 30 kwargs = {'dry_run': dry_run, 'logger': logger} 31 32 try: 33 format_info = _ARCHIVE_FORMATS[format] 34 except KeyError: 35 raise ValueError, "unknown archive format '%s'" % format 36 37 func = format_info[0] 38 for arg, val in format_info[1]: 39 kwargs[arg] = val 40 41 if format != 'zip': 42 kwargs['owner'] = owner 43 kwargs['group'] = group 44 45 try: 46 filename = func(base_name, base_dir, **kwargs) 47 finally: 48 if root_dir is not None: 49 if logger is not None: 50 logger.debug("changing back to '%s'", save_cwd) 51 os.chdir(save_cwd) 52 53 return filename
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
1 import zipfile 2 3 # 压缩 4 z = zipfile.ZipFile('laxi.zip', 'w') 5 z.write('a.log') 6 z.write('data.data') 7 z.close() 8 9 # 解压 10 z = zipfile.ZipFile('laxi.zip', 'r') 11 z.extractall() 12 z.close() 13 14 zipfile 压缩解压
1 import tarfile 2 3 # 压缩 4 tar = tarfile.open('your.tar','w') 5 tar.add('/Users/wupeiqi/PycharmProjects/bbs2.zip', arcname='bbs2.zip') 6 tar.add('/Users/wupeiqi/PycharmProjects/cmdb.zip', arcname='cmdb.zip') 7 tar.close() 8 9 # 解压 10 tar = tarfile.open('your.tar','r') 11 tar.extractall() # 可设置解压地址 12 tar.close() 13 14 tarfile 压缩解压
1 class ZipFile(object): 2 """ Class with methods to open, read, write, close, list zip files. 3 4 z = ZipFile(file, mode="r", compression=ZIP_STORED, allowZip64=False) 5 6 file: Either the path to the file, or a file-like object. 7 If it is a path, the file will be opened and closed by ZipFile. 8 mode: The mode can be either read "r", write "w" or append "a". 9 compression: ZIP_STORED (no compression) or ZIP_DEFLATED (requires zlib). 10 allowZip64: if True ZipFile will create files with ZIP64 extensions when 11 needed, otherwise it will raise an exception when this would 12 be necessary. 13 14 """ 15 16 fp = None # Set here since __del__ checks it 17 18 def __init__(self, file, mode="r", compression=ZIP_STORED, allowZip64=False): 19 """Open the ZIP file with mode read "r", write "w" or append "a".""" 20 if mode not in ("r", "w", "a"): 21 raise RuntimeError('ZipFile() requires mode "r", "w", or "a"') 22 23 if compression == ZIP_STORED: 24 pass 25 elif compression == ZIP_DEFLATED: 26 if not zlib: 27 raise RuntimeError, 28 "Compression requires the (missing) zlib module" 29 else: 30 raise RuntimeError, "That compression method is not supported" 31 32 self._allowZip64 = allowZip64 33 self._didModify = False 34 self.debug = 0 # Level of printing: 0 through 3 35 self.NameToInfo = {} # Find file info given name 36 self.filelist = [] # List of ZipInfo instances for archive 37 self.compression = compression # Method of compression 38 self.mode = key = mode.replace('b', '')[0] 39 self.pwd = None 40 self._comment = '' 41 42 # Check if we were passed a file-like object 43 if isinstance(file, basestring): 44 self._filePassed = 0 45 self.filename = file 46 modeDict = {'r' : 'rb', 'w': 'wb', 'a' : 'r+b'} 47 try: 48 self.fp = open(file, modeDict[mode]) 49 except IOError: 50 if mode == 'a': 51 mode = key = 'w' 52 self.fp = open(file, modeDict[mode]) 53 else: 54 raise 55 else: 56 self._filePassed = 1 57 self.fp = file 58 self.filename = getattr(file, 'name', None) 59 60 try: 61 if key == 'r': 62 self._RealGetContents() 63 elif key == 'w': 64 # set the modified flag so central directory gets written 65 # even if no files are added to the archive 66 self._didModify = True 67 elif key == 'a': 68 try: 69 # See if file is a zip file 70 self._RealGetContents() 71 # seek to start of directory and overwrite 72 self.fp.seek(self.start_dir, 0) 73 except BadZipfile: 74 # file is not a zip file, just append 75 self.fp.seek(0, 2) 76 77 # set the modified flag so central directory gets written 78 # even if no files are added to the archive 79 self._didModify = True 80 else: 81 raise RuntimeError('Mode must be "r", "w" or "a"') 82 except: 83 fp = self.fp 84 self.fp = None 85 if not self._filePassed: 86 fp.close() 87 raise 88 89 def __enter__(self): 90 return self 91 92 def __exit__(self, type, value, traceback): 93 self.close() 94 95 def _RealGetContents(self): 96 """Read in the table of contents for the ZIP file.""" 97 fp = self.fp 98 try: 99 endrec = _EndRecData(fp) 100 except IOError: 101 raise BadZipfile("File is not a zip file") 102 if not endrec: 103 raise BadZipfile, "File is not a zip file" 104 if self.debug > 1: 105 print endrec 106 size_cd = endrec[_ECD_SIZE] # bytes in central directory 107 offset_cd = endrec[_ECD_OFFSET] # offset of central directory 108 self._comment = endrec[_ECD_COMMENT] # archive comment 109 110 # "concat" is zero, unless zip was concatenated to another file 111 concat = endrec[_ECD_LOCATION] - size_cd - offset_cd 112 if endrec[_ECD_SIGNATURE] == stringEndArchive64: 113 # If Zip64 extension structures are present, account for them 114 concat -= (sizeEndCentDir64 + sizeEndCentDir64Locator) 115 116 if self.debug > 2: 117 inferred = concat + offset_cd 118 print "given, inferred, offset", offset_cd, inferred, concat 119 # self.start_dir: Position of start of central directory 120 self.start_dir = offset_cd + concat 121 fp.seek(self.start_dir, 0) 122 data = fp.read(size_cd) 123 fp = cStringIO.StringIO(data) 124 total = 0 125 while total < size_cd: 126 centdir = fp.read(sizeCentralDir) 127 if len(centdir) != sizeCentralDir: 128 raise BadZipfile("Truncated central directory") 129 centdir = struct.unpack(structCentralDir, centdir) 130 if centdir[_CD_SIGNATURE] != stringCentralDir: 131 raise BadZipfile("Bad magic number for central directory") 132 if self.debug > 2: 133 print centdir 134 filename = fp.read(centdir[_CD_FILENAME_LENGTH]) 135 # Create ZipInfo instance to store file information 136 x = ZipInfo(filename) 137 x.extra = fp.read(centdir[_CD_EXTRA_FIELD_LENGTH]) 138 x.comment = fp.read(centdir[_CD_COMMENT_LENGTH]) 139 x.header_offset = centdir[_CD_LOCAL_HEADER_OFFSET] 140 (x.create_version, x.create_system, x.extract_version, x.reserved, 141 x.flag_bits, x.compress_type, t, d, 142 x.CRC, x.compress_size, x.file_size) = centdir[1:12] 143 x.volume, x.internal_attr, x.external_attr = centdir[15:18] 144 # Convert date/time code to (year, month, day, hour, min, sec) 145 x._raw_time = t 146 x.date_time = ( (d>>9)+1980, (d>>5)&0xF, d&0x1F, 147 t>>11, (t>>5)&0x3F, (t&0x1F) * 2 ) 148 149 x._decodeExtra() 150 x.header_offset = x.header_offset + concat 151 x.filename = x._decodeFilename() 152 self.filelist.append(x) 153 self.NameToInfo[x.filename] = x 154 155 # update total bytes read from central directory 156 total = (total + sizeCentralDir + centdir[_CD_FILENAME_LENGTH] 157 + centdir[_CD_EXTRA_FIELD_LENGTH] 158 + centdir[_CD_COMMENT_LENGTH]) 159 160 if self.debug > 2: 161 print "total", total 162 163 164 def namelist(self): 165 """Return a list of file names in the archive.""" 166 l = [] 167 for data in self.filelist: 168 l.append(data.filename) 169 return l 170 171 def infolist(self): 172 """Return a list of class ZipInfo instances for files in the 173 archive.""" 174 return self.filelist 175 176 def printdir(self): 177 """Print a table of contents for the zip file.""" 178 print "%-46s %19s %12s" % ("File Name", "Modified ", "Size") 179 for zinfo in self.filelist: 180 date = "%d-%02d-%02d %02d:%02d:%02d" % zinfo.date_time[:6] 181 print "%-46s %s %12d" % (zinfo.filename, date, zinfo.file_size) 182 183 def testzip(self): 184 """Read all the files and check the CRC.""" 185 chunk_size = 2 ** 20 186 for zinfo in self.filelist: 187 try: 188 # Read by chunks, to avoid an OverflowError or a 189 # MemoryError with very large embedded files. 190 with self.open(zinfo.filename, "r") as f: 191 while f.read(chunk_size): # Check CRC-32 192 pass 193 except BadZipfile: 194 return zinfo.filename 195 196 def getinfo(self, name): 197 """Return the instance of ZipInfo given 'name'.""" 198 info = self.NameToInfo.get(name) 199 if info is None: 200 raise KeyError( 201 'There is no item named %r in the archive' % name) 202 203 return info 204 205 def setpassword(self, pwd): 206 """Set default password for encrypted files.""" 207 self.pwd = pwd 208 209 @property 210 def comment(self): 211 """The comment text associated with the ZIP file.""" 212 return self._comment 213 214 @comment.setter 215 def comment(self, comment): 216 # check for valid comment length 217 if len(comment) > ZIP_MAX_COMMENT: 218 import warnings 219 warnings.warn('Archive comment is too long; truncating to %d bytes' 220 % ZIP_MAX_COMMENT, stacklevel=2) 221 comment = comment[:ZIP_MAX_COMMENT] 222 self._comment = comment 223 self._didModify = True 224 225 def read(self, name, pwd=None): 226 """Return file bytes (as a string) for name.""" 227 return self.open(name, "r", pwd).read() 228 229 def open(self, name, mode="r", pwd=None): 230 """Return file-like object for 'name'.""" 231 if mode not in ("r", "U", "rU"): 232 raise RuntimeError, 'open() requires mode "r", "U", or "rU"' 233 if not self.fp: 234 raise RuntimeError, 235 "Attempt to read ZIP archive that was already closed" 236 237 # Only open a new file for instances where we were not 238 # given a file object in the constructor 239 if self._filePassed: 240 zef_file = self.fp 241 should_close = False 242 else: 243 zef_file = open(self.filename, 'rb') 244 should_close = True 245 246 try: 247 # Make sure we have an info object 248 if isinstance(name, ZipInfo): 249 # 'name' is already an info object 250 zinfo = name 251 else: 252 # Get info object for name 253 zinfo = self.getinfo(name) 254 255 zef_file.seek(zinfo.header_offset, 0) 256 257 # Skip the file header: 258 fheader = zef_file.read(sizeFileHeader) 259 if len(fheader) != sizeFileHeader: 260 raise BadZipfile("Truncated file header") 261 fheader = struct.unpack(structFileHeader, fheader) 262 if fheader[_FH_SIGNATURE] != stringFileHeader: 263 raise BadZipfile("Bad magic number for file header") 264 265 fname = zef_file.read(fheader[_FH_FILENAME_LENGTH]) 266 if fheader[_FH_EXTRA_FIELD_LENGTH]: 267 zef_file.read(fheader[_FH_EXTRA_FIELD_LENGTH]) 268 269 if fname != zinfo.orig_filename: 270 raise BadZipfile, 271 'File name in directory "%s" and header "%s" differ.' % ( 272 zinfo.orig_filename, fname) 273 274 # check for encrypted flag & handle password 275 is_encrypted = zinfo.flag_bits & 0x1 276 zd = None 277 if is_encrypted: 278 if not pwd: 279 pwd = self.pwd 280 if not pwd: 281 raise RuntimeError, "File %s is encrypted, " 282 "password required for extraction" % name 283 284 zd = _ZipDecrypter(pwd) 285 # The first 12 bytes in the cypher stream is an encryption header 286 # used to strengthen the algorithm. The first 11 bytes are 287 # completely random, while the 12th contains the MSB of the CRC, 288 # or the MSB of the file time depending on the header type 289 # and is used to check the correctness of the password. 290 bytes = zef_file.read(12) 291 h = map(zd, bytes[0:12]) 292 if zinfo.flag_bits & 0x8: 293 # compare against the file type from extended local headers 294 check_byte = (zinfo._raw_time >> 8) & 0xff 295 else: 296 # compare against the CRC otherwise 297 check_byte = (zinfo.CRC >> 24) & 0xff 298 if ord(h[11]) != check_byte: 299 raise RuntimeError("Bad password for file", name) 300 301 return ZipExtFile(zef_file, mode, zinfo, zd, 302 close_fileobj=should_close) 303 except: 304 if should_close: 305 zef_file.close() 306 raise 307 308 def extract(self, member, path=None, pwd=None): 309 """Extract a member from the archive to the current working directory, 310 using its full name. Its file information is extracted as accurately 311 as possible. `member' may be a filename or a ZipInfo object. You can 312 specify a different directory using `path'. 313 """ 314 if not isinstance(member, ZipInfo): 315 member = self.getinfo(member) 316 317 if path is None: 318 path = os.getcwd() 319 320 return self._extract_member(member, path, pwd) 321 322 def extractall(self, path=None, members=None, pwd=None): 323 """Extract all members from the archive to the current working 324 directory. `path' specifies a different directory to extract to. 325 `members' is optional and must be a subset of the list returned 326 by namelist(). 327 """ 328 if members is None: 329 members = self.namelist() 330 331 for zipinfo in members: 332 self.extract(zipinfo, path, pwd) 333 334 def _extract_member(self, member, targetpath, pwd): 335 """Extract the ZipInfo object 'member' to a physical 336 file on the path targetpath. 337 """ 338 # build the destination pathname, replacing 339 # forward slashes to platform specific separators. 340 arcname = member.filename.replace('/', os.path.sep) 341 342 if os.path.altsep: 343 arcname = arcname.replace(os.path.altsep, os.path.sep) 344 # interpret absolute pathname as relative, remove drive letter or 345 # UNC path, redundant separators, "." and ".." components. 346 arcname = os.path.splitdrive(arcname)[1] 347 arcname = os.path.sep.join(x for x in arcname.split(os.path.sep) 348 if x not in ('', os.path.curdir, os.path.pardir)) 349 if os.path.sep == '\': 350 # filter illegal characters on Windows 351 illegal = ':<>|"?*' 352 if isinstance(arcname, unicode): 353 table = {ord(c): ord('_') for c in illegal} 354 else: 355 table = string.maketrans(illegal, '_' * len(illegal)) 356 arcname = arcname.translate(table) 357 # remove trailing dots 358 arcname = (x.rstrip('.') for x in arcname.split(os.path.sep)) 359 arcname = os.path.sep.join(x for x in arcname if x) 360 361 targetpath = os.path.join(targetpath, arcname) 362 targetpath = os.path.normpath(targetpath) 363 364 # Create all upper directories if necessary. 365 upperdirs = os.path.dirname(targetpath) 366 if upperdirs and not os.path.exists(upperdirs): 367 os.makedirs(upperdirs) 368 369 if member.filename[-1] == '/': 370 if not os.path.isdir(targetpath): 371 os.mkdir(targetpath) 372 return targetpath 373 374 with self.open(member, pwd=pwd) as source, 375 file(targetpath, "wb") as target: 376 shutil.copyfileobj(source, target) 377 378 return targetpath 379 380 def _writecheck(self, zinfo): 381 """Check for errors before writing a file to the archive.""" 382 if zinfo.filename in self.NameToInfo: 383 import warnings 384 warnings.warn('Duplicate name: %r' % zinfo.filename, stacklevel=3) 385 if self.mode not in ("w", "a"): 386 raise RuntimeError, 'write() requires mode "w" or "a"' 387 if not self.fp: 388 raise RuntimeError, 389 "Attempt to write ZIP archive that was already closed" 390 if zinfo.compress_type == ZIP_DEFLATED and not zlib: 391 raise RuntimeError, 392 "Compression requires the (missing) zlib module" 393 if zinfo.compress_type not in (ZIP_STORED, ZIP_DEFLATED): 394 raise RuntimeError, 395 "That compression method is not supported" 396 if not self._allowZip64: 397 requires_zip64 = None 398 if len(self.filelist) >= ZIP_FILECOUNT_LIMIT: 399 requires_zip64 = "Files count" 400 elif zinfo.file_size > ZIP64_LIMIT: 401 requires_zip64 = "Filesize" 402 elif zinfo.header_offset > ZIP64_LIMIT: 403 requires_zip64 = "Zipfile size" 404 if requires_zip64: 405 raise LargeZipFile(requires_zip64 + 406 " would require ZIP64 extensions") 407 408 def write(self, filename, arcname=None, compress_type=None): 409 """Put the bytes from filename into the archive under the name 410 arcname.""" 411 if not self.fp: 412 raise RuntimeError( 413 "Attempt to write to ZIP archive that was already closed") 414 415 st = os.stat(filename) 416 isdir = stat.S_ISDIR(st.st_mode) 417 mtime = time.localtime(st.st_mtime) 418 date_time = mtime[0:6] 419 # Create ZipInfo instance to store file information 420 if arcname is None: 421 arcname = filename 422 arcname = os.path.normpath(os.path.splitdrive(arcname)[1]) 423 while arcname[0] in (os.sep, os.altsep): 424 arcname = arcname[1:] 425 if isdir: 426 arcname += '/' 427 zinfo = ZipInfo(arcname, date_time) 428 zinfo.external_attr = (st[0] & 0xFFFF) << 16L # Unix attributes 429 if compress_type is None: 430 zinfo.compress_type = self.compression 431 else: 432 zinfo.compress_type = compress_type 433 434 zinfo.file_size = st.st_size 435 zinfo.flag_bits = 0x00 436 zinfo.header_offset = self.fp.tell() # Start of header bytes 437 438 self._writecheck(zinfo) 439 self._didModify = True 440 441 if isdir: 442 zinfo.file_size = 0 443 zinfo.compress_size = 0 444 zinfo.CRC = 0 445 zinfo.external_attr |= 0x10 # MS-DOS directory flag 446 self.filelist.append(zinfo) 447 self.NameToInfo[zinfo.filename] = zinfo 448 self.fp.write(zinfo.FileHeader(False)) 449 return 450 451 with open(filename, "rb") as fp: 452 # Must overwrite CRC and sizes with correct data later 453 zinfo.CRC = CRC = 0 454 zinfo.compress_size = compress_size = 0 455 # Compressed size can be larger than uncompressed size 456 zip64 = self._allowZip64 and 457 zinfo.file_size * 1.05 > ZIP64_LIMIT 458 self.fp.write(zinfo.FileHeader(zip64)) 459 if zinfo.compress_type == ZIP_DEFLATED: 460 cmpr = zlib.compressobj(zlib.Z_DEFAULT_COMPRESSION, 461 zlib.DEFLATED, -15) 462 else: 463 cmpr = None 464 file_size = 0 465 while 1: 466 buf = fp.read(1024 * 8) 467 if not buf: 468 break 469 file_size = file_size + len(buf) 470 CRC = crc32(buf, CRC) & 0xffffffff 471 if cmpr: 472 buf = cmpr.compress(buf) 473 compress_size = compress_size + len(buf) 474 self.fp.write(buf) 475 if cmpr: 476 buf = cmpr.flush() 477 compress_size = compress_size + len(buf) 478 self.fp.write(buf) 479 zinfo.compress_size = compress_size 480 else: 481 zinfo.compress_size = file_size 482 zinfo.CRC = CRC 483 zinfo.file_size = file_size 484 if not zip64 and self._allowZip64: 485 if file_size > ZIP64_LIMIT: 486 raise RuntimeError('File size has increased during compressing') 487 if compress_size > ZIP64_LIMIT: 488 raise RuntimeError('Compressed size larger than uncompressed size') 489 # Seek backwards and write file header (which will now include 490 # correct CRC and file sizes) 491 position = self.fp.tell() # Preserve current position in file 492 self.fp.seek(zinfo.header_offset, 0) 493 self.fp.write(zinfo.FileHeader(zip64)) 494 self.fp.seek(position, 0) 495 self.filelist.append(zinfo) 496 self.NameToInfo[zinfo.filename] = zinfo 497 498 def writestr(self, zinfo_or_arcname, bytes, compress_type=None): 499 """Write a file into the archive. The contents is the string 500 'bytes'. 'zinfo_or_arcname' is either a ZipInfo instance or 501 the name of the file in the archive.""" 502 if not isinstance(zinfo_or_arcname, ZipInfo): 503 zinfo = ZipInfo(filename=zinfo_or_arcname, 504 date_time=time.localtime(time.time())[:6]) 505 506 zinfo.compress_type = self.compression 507 if zinfo.filename[-1] == '/': 508 zinfo.external_attr = 0o40775 << 16 # drwxrwxr-x 509 zinfo.external_attr |= 0x10 # MS-DOS directory flag 510 else: 511 zinfo.external_attr = 0o600 << 16 # ?rw------- 512 else: 513 zinfo = zinfo_or_arcname 514 515 if not self.fp: 516 raise RuntimeError( 517 "Attempt to write to ZIP archive that was already closed") 518 519 if compress_type is not None: 520 zinfo.compress_type = compress_type 521 522 zinfo.file_size = len(bytes) # Uncompressed size 523 zinfo.header_offset = self.fp.tell() # Start of header bytes 524 self._writecheck(zinfo) 525 self._didModify = True 526 zinfo.CRC = crc32(bytes) & 0xffffffff # CRC-32 checksum 527 if zinfo.compress_type == ZIP_DEFLATED: 528 co = zlib.compressobj(zlib.Z_DEFAULT_COMPRESSION, 529 zlib.DEFLATED, -15) 530 bytes = co.compress(bytes) + co.flush() 531 zinfo.compress_size = len(bytes) # Compressed size 532 else: 533 zinfo.compress_size = zinfo.file_size 534 zip64 = zinfo.file_size > ZIP64_LIMIT or 535 zinfo.compress_size > ZIP64_LIMIT 536 if zip64 and not self._allowZip64: 537 raise LargeZipFile("Filesize would require ZIP64 extensions") 538 self.fp.write(zinfo.FileHeader(zip64)) 539 self.fp.write(bytes) 540 if zinfo.flag_bits & 0x08: 541 # Write CRC and file sizes after the file data 542 fmt = '<LQQ' if zip64 else '<LLL' 543 self.fp.write(struct.pack(fmt, zinfo.CRC, zinfo.compress_size, 544 zinfo.file_size)) 545 self.fp.flush() 546 self.filelist.append(zinfo) 547 self.NameToInfo[zinfo.filename] = zinfo 548 549 def __del__(self): 550 """Call the "close()" method in case the user forgot.""" 551 self.close() 552 553 def close(self): 554 """Close the file, and for mode "w" and "a" write the ending 555 records.""" 556 if self.fp is None: 557 return 558 559 try: 560 if self.mode in ("w", "a") and self._didModify: # write ending records 561 pos1 = self.fp.tell() 562 for zinfo in self.filelist: # write central directory 563 dt = zinfo.date_time 564 dosdate = (dt[0] - 1980) << 9 | dt[1] << 5 | dt[2] 565 dostime = dt[3] << 11 | dt[4] << 5 | (dt[5] // 2) 566 extra = [] 567 if zinfo.file_size > ZIP64_LIMIT 568 or zinfo.compress_size > ZIP64_LIMIT: 569 extra.append(zinfo.file_size) 570 extra.append(zinfo.compress_size) 571 file_size = 0xffffffff 572 compress_size = 0xffffffff 573 else: 574 file_size = zinfo.file_size 575 compress_size = zinfo.compress_size 576 577 if zinfo.header_offset > ZIP64_LIMIT: 578 extra.append(zinfo.header_offset) 579 header_offset = 0xffffffffL 580 else: 581 header_offset = zinfo.header_offset 582 583 extra_data = zinfo.extra 584 if extra: 585 # Append a ZIP64 field to the extra's 586 extra_data = struct.pack( 587 '<HH' + 'Q'*len(extra), 588 1, 8*len(extra), *extra) + extra_data 589 590 extract_version = max(45, zinfo.extract_version) 591 create_version = max(45, zinfo.create_version) 592 else: 593 extract_version = zinfo.extract_version 594 create_version = zinfo.create_version 595 596 try: 597 filename, flag_bits = zinfo._encodeFilenameFlags() 598 centdir = struct.pack(structCentralDir, 599 stringCentralDir, create_version, 600 zinfo.create_system, extract_version, zinfo.reserved, 601 flag_bits, zinfo.compress_type, dostime, dosdate, 602 zinfo.CRC, compress_size, file_size, 603 len(filename), len(extra_data), len(zinfo.comment), 604 0, zinfo.internal_attr, zinfo.external_attr, 605 header_offset) 606 except DeprecationWarning: 607 print >>sys.stderr, (structCentralDir, 608 stringCentralDir, create_version, 609 zinfo.create_system, extract_version, zinfo.reserved, 610 zinfo.flag_bits, zinfo.compress_type, dostime, dosdate, 611 zinfo.CRC, compress_size, file_size, 612 len(zinfo.filename), len(extra_data), len(zinfo.comment), 613 0, zinfo.internal_attr, zinfo.external_attr, 614 header_offset) 615 raise 616 self.fp.write(centdir) 617 self.fp.write(filename) 618 self.fp.write(extra_data) 619 self.fp.write(zinfo.comment) 620 621 pos2 = self.fp.tell() 622 # Write end-of-zip-archive record 623 centDirCount = len(self.filelist) 624 centDirSize = pos2 - pos1 625 centDirOffset = pos1 626 requires_zip64 = None 627 if centDirCount > ZIP_FILECOUNT_LIMIT: 628 requires_zip64 = "Files count" 629 elif centDirOffset > ZIP64_LIMIT: 630 requires_zip64 = "Central directory offset" 631 elif centDirSize > ZIP64_LIMIT: 632 requires_zip64 = "Central directory size" 633 if requires_zip64: 634 # Need to write the ZIP64 end-of-archive records 635 if not self._allowZip64: 636 raise LargeZipFile(requires_zip64 + 637 " would require ZIP64 extensions") 638 zip64endrec = struct.pack( 639 structEndArchive64, stringEndArchive64, 640 44, 45, 45, 0, 0, centDirCount, centDirCount, 641 centDirSize, centDirOffset) 642 self.fp.write(zip64endrec) 643 644 zip64locrec = struct.pack( 645 structEndArchive64Locator, 646 stringEndArchive64Locator, 0, pos2, 1) 647 self.fp.write(zip64locrec) 648 centDirCount = min(centDirCount, 0xFFFF) 649 centDirSize = min(centDirSize, 0xFFFFFFFF) 650 centDirOffset = min(centDirOffset, 0xFFFFFFFF) 651 652 endrec = struct.pack(structEndArchive, stringEndArchive, 653 0, 0, centDirCount, centDirCount, 654 centDirSize, centDirOffset, len(self._comment)) 655 self.fp.write(endrec) 656 self.fp.write(self._comment) 657 self.fp.flush() 658 finally: 659 fp = self.fp 660 self.fp = None 661 if not self._filePassed: 662 fp.close() 663 664 ZipFile
1 class TarFile(object): 2 """The TarFile Class provides an interface to tar archives. 3 """ 4 5 debug = 0 # May be set from 0 (no msgs) to 3 (all msgs) 6 7 dereference = False # If true, add content of linked file to the 8 # tar file, else the link. 9 10 ignore_zeros = False # If true, skips empty or invalid blocks and 11 # continues processing. 12 13 errorlevel = 1 # If 0, fatal errors only appear in debug 14 # messages (if debug >= 0). If > 0, errors 15 # are passed to the caller as exceptions. 16 17 format = DEFAULT_FORMAT # The format to use when creating an archive. 18 19 encoding = ENCODING # Encoding for 8-bit character strings. 20 21 errors = None # Error handler for unicode conversion. 22 23 tarinfo = TarInfo # The default TarInfo class to use. 24 25 fileobject = ExFileObject # The default ExFileObject class to use. 26 27 def __init__(self, name=None, mode="r", fileobj=None, format=None, 28 tarinfo=None, dereference=None, ignore_zeros=None, encoding=None, 29 errors=None, pax_headers=None, debug=None, errorlevel=None): 30 """Open an (uncompressed) tar archive `name'. `mode' is either 'r' to 31 read from an existing archive, 'a' to append data to an existing 32 file or 'w' to create a new file overwriting an existing one. `mode' 33 defaults to 'r'. 34 If `fileobj' is given, it is used for reading or writing data. If it 35 can be determined, `mode' is overridden by `fileobj's mode. 36 `fileobj' is not closed, when TarFile is closed. 37 """ 38 modes = {"r": "rb", "a": "r+b", "w": "wb"} 39 if mode not in modes: 40 raise ValueError("mode must be 'r', 'a' or 'w'") 41 self.mode = mode 42 self._mode = modes[mode] 43 44 if not fileobj: 45 if self.mode == "a" and not os.path.exists(name): 46 # Create nonexistent files in append mode. 47 self.mode = "w" 48 self._mode = "wb" 49 fileobj = bltn_open(name, self._mode) 50 self._extfileobj = False 51 else: 52 if name is None and hasattr(fileobj, "name"): 53 name = fileobj.name 54 if hasattr(fileobj, "mode"): 55 self._mode = fileobj.mode 56 self._extfileobj = True 57 self.name = os.path.abspath(name) if name else None 58 self.fileobj = fileobj 59 60 # Init attributes. 61 if format is not None: 62 self.format = format 63 if tarinfo is not None: 64 self.tarinfo = tarinfo 65 if dereference is not None: 66 self.dereference = dereference 67 if ignore_zeros is not None: 68 self.ignore_zeros = ignore_zeros 69 if encoding is not None: 70 self.encoding = encoding 71 72 if errors is not None: 73 self.errors = errors 74 elif mode == "r": 75 self.errors = "utf-8" 76 else: 77 self.errors = "strict" 78 79 if pax_headers is not None and self.format == PAX_FORMAT: 80 self.pax_headers = pax_headers 81 else: 82 self.pax_headers = {} 83 84 if debug is not None: 85 self.debug = debug 86 if errorlevel is not None: 87 self.errorlevel = errorlevel 88 89 # Init datastructures. 90 self.closed = False 91 self.members = [] # list of members as TarInfo objects 92 self._loaded = False # flag if all members have been read 93 self.offset = self.fileobj.tell() 94 # current position in the archive file 95 self.inodes = {} # dictionary caching the inodes of 96 # archive members already added 97 98 try: 99 if self.mode == "r": 100 self.firstmember = None 101 self.firstmember = self.next() 102 103 if self.mode == "a": 104 # Move to the end of the archive, 105 # before the first empty block. 106 while True: 107 self.fileobj.seek(self.offset) 108 try: 109 tarinfo = self.tarinfo.fromtarfile(self) 110 self.members.append(tarinfo) 111 except EOFHeaderError: 112 self.fileobj.seek(self.offset) 113 break 114 except HeaderError, e: 115 raise ReadError(str(e)) 116 117 if self.mode in "aw": 118 self._loaded = True 119 120 if self.pax_headers: 121 buf = self.tarinfo.create_pax_global_header(self.pax_headers.copy()) 122 self.fileobj.write(buf) 123 self.offset += len(buf) 124 except: 125 if not self._extfileobj: 126 self.fileobj.close() 127 self.closed = True 128 raise 129 130 def _getposix(self): 131 return self.format == USTAR_FORMAT 132 def _setposix(self, value): 133 import warnings 134 warnings.warn("use the format attribute instead", DeprecationWarning, 135 2) 136 if value: 137 self.format = USTAR_FORMAT 138 else: 139 self.format = GNU_FORMAT 140 posix = property(_getposix, _setposix) 141 142 #-------------------------------------------------------------------------- 143 # Below are the classmethods which act as alternate constructors to the 144 # TarFile class. The open() method is the only one that is needed for 145 # public use; it is the "super"-constructor and is able to select an 146 # adequate "sub"-constructor for a particular compression using the mapping 147 # from OPEN_METH. 148 # 149 # This concept allows one to subclass TarFile without losing the comfort of 150 # the super-constructor. A sub-constructor is registered and made available 151 # by adding it to the mapping in OPEN_METH. 152 153 @classmethod 154 def open(cls, name=None, mode="r", fileobj=None, bufsize=RECORDSIZE, **kwargs): 155 """Open a tar archive for reading, writing or appending. Return 156 an appropriate TarFile class. 157 158 mode: 159 'r' or 'r:*' open for reading with transparent compression 160 'r:' open for reading exclusively uncompressed 161 'r:gz' open for reading with gzip compression 162 'r:bz2' open for reading with bzip2 compression 163 'a' or 'a:' open for appending, creating the file if necessary 164 'w' or 'w:' open for writing without compression 165 'w:gz' open for writing with gzip compression 166 'w:bz2' open for writing with bzip2 compression 167 168 'r|*' open a stream of tar blocks with transparent compression 169 'r|' open an uncompressed stream of tar blocks for reading 170 'r|gz' open a gzip compressed stream of tar blocks 171 'r|bz2' open a bzip2 compressed stream of tar blocks 172 'w|' open an uncompressed stream for writing 173 'w|gz' open a gzip compressed stream for writing 174 'w|bz2' open a bzip2 compressed stream for writing 175 """ 176 177 if not name and not fileobj: 178 raise ValueError("nothing to open") 179 180 if mode in ("r", "r:*"): 181 # Find out which *open() is appropriate for opening the file. 182 for comptype in cls.OPEN_METH: 183 func = getattr(cls, cls.OPEN_METH[comptype]) 184 if fileobj is not None: 185 saved_pos = fileobj.tell() 186 try: 187 return func(name, "r", fileobj, **kwargs) 188 except (ReadError, CompressionError), e: 189 if fileobj is not None: 190 fileobj.seek(saved_pos) 191 continue 192 raise ReadError("file could not be opened successfully") 193 194 elif ":" in mode: 195 filemode, comptype = mode.split(":", 1) 196 filemode = filemode or "r" 197 comptype = comptype or "tar" 198 199 # Select the *open() function according to 200 # given compression. 201 if comptype in cls.OPEN_METH: 202 func = getattr(cls, cls.OPEN_METH[comptype]) 203 else: 204 raise CompressionError("unknown compression type %r" % comptype) 205 return func(name, filemode, fileobj, **kwargs) 206 207 elif "|" in mode: 208 filemode, comptype = mode.split("|", 1) 209 filemode = filemode or "r" 210 comptype = comptype or "tar" 211 212 if filemode not in ("r", "w"): 213 raise ValueError("mode must be 'r' or 'w'") 214 215 stream = _Stream(name, filemode, comptype, fileobj, bufsize) 216 try: 217 t = cls(name, filemode, stream, **kwargs) 218 except: 219 stream.close() 220 raise 221 t._extfileobj = False 222 return t 223 224 elif mode in ("a", "w"): 225 return cls.taropen(name, mode, fileobj, **kwargs) 226 227 raise ValueError("undiscernible mode") 228 229 @classmethod 230 def taropen(cls, name, mode="r", fileobj=None, **kwargs): 231 """Open uncompressed tar archive name for reading or writing. 232 """ 233 if mode not in ("r", "a", "w"): 234 raise ValueError("mode must be 'r', 'a' or 'w'") 235 return cls(name, mode, fileobj, **kwargs) 236 237 @classmethod 238 def gzopen(cls, name, mode="r", fileobj=None, compresslevel=9, **kwargs): 239 """Open gzip compressed tar archive name for reading or writing. 240 Appending is not allowed. 241 """ 242 if mode not in ("r", "w"): 243 raise ValueError("mode must be 'r' or 'w'") 244 245 try: 246 import gzip 247 gzip.GzipFile 248 except (ImportError, AttributeError): 249 raise CompressionError("gzip module is not available") 250 251 try: 252 fileobj = gzip.GzipFile(name, mode, compresslevel, fileobj) 253 except OSError: 254 if fileobj is not None and mode == 'r': 255 raise ReadError("not a gzip file") 256 raise 257 258 try: 259 t = cls.taropen(name, mode, fileobj, **kwargs) 260 except IOError: 261 fileobj.close() 262 if mode == 'r': 263 raise ReadError("not a gzip file") 264 raise 265 except: 266 fileobj.close() 267 raise 268 t._extfileobj = False 269 return t 270 271 @classmethod 272 def bz2open(cls, name, mode="r", fileobj=None, compresslevel=9, **kwargs): 273 """Open bzip2 compressed tar archive name for reading or writing. 274 Appending is not allowed. 275 """ 276 if mode not in ("r", "w"): 277 raise ValueError("mode must be 'r' or 'w'.") 278 279 try: 280 import bz2 281 except ImportError: 282 raise CompressionError("bz2 module is not available") 283 284 if fileobj is not None: 285 fileobj = _BZ2Proxy(fileobj, mode) 286 else: 287 fileobj = bz2.BZ2File(name, mode, compresslevel=compresslevel) 288 289 try: 290 t = cls.taropen(name, mode, fileobj, **kwargs) 291 except (IOError, EOFError): 292 fileobj.close() 293 if mode == 'r': 294 raise ReadError("not a bzip2 file") 295 raise 296 except: 297 fileobj.close() 298 raise 299 t._extfileobj = False 300 return t 301 302 # All *open() methods are registered here. 303 OPEN_METH = { 304 "tar": "taropen", # uncompressed tar 305 "gz": "gzopen", # gzip compressed tar 306 "bz2": "bz2open" # bzip2 compressed tar 307 } 308 309 #-------------------------------------------------------------------------- 310 # The public methods which TarFile provides: 311 312 def close(self): 313 """Close the TarFile. In write-mode, two finishing zero blocks are 314 appended to the archive. 315 """ 316 if self.closed: 317 return 318 319 if self.mode in "aw": 320 self.fileobj.write(NUL * (BLOCKSIZE * 2)) 321 self.offset += (BLOCKSIZE * 2) 322 # fill up the end with zero-blocks 323 # (like option -b20 for tar does) 324 blocks, remainder = divmod(self.offset, RECORDSIZE) 325 if remainder > 0: 326 self.fileobj.write(NUL * (RECORDSIZE - remainder)) 327 328 if not self._extfileobj: 329 self.fileobj.close() 330 self.closed = True 331 332 def getmember(self, name): 333 """Return a TarInfo object for member `name'. If `name' can not be 334 found in the archive, KeyError is raised. If a member occurs more 335 than once in the archive, its last occurrence is assumed to be the 336 most up-to-date version. 337 """ 338 tarinfo = self._getmember(name) 339 if tarinfo is None: 340 raise KeyError("filename %r not found" % name) 341 return tarinfo 342 343 def getmembers(self): 344 """Return the members of the archive as a list of TarInfo objects. The 345 list has the same order as the members in the archive. 346 """ 347 self._check() 348 if not self._loaded: # if we want to obtain a list of 349 self._load() # all members, we first have to 350 # scan the whole archive. 351 return self.members 352 353 def getnames(self): 354 """Return the members of the archive as a list of their names. It has 355 the same order as the list returned by getmembers(). 356 """ 357 return [tarinfo.name for tarinfo in self.getmembers()] 358 359 def gettarinfo(self, name=None, arcname=None, fileobj=None): 360 """Create a TarInfo object for either the file `name' or the file 361 object `fileobj' (using os.fstat on its file descriptor). You can 362 modify some of the TarInfo's attributes before you add it using 363 addfile(). If given, `arcname' specifies an alternative name for the 364 file in the archive. 365 """ 366 self._check("aw") 367 368 # When fileobj is given, replace name by 369 # fileobj's real name. 370 if fileobj is not None: 371 name = fileobj.name 372 373 # Building the name of the member in the archive. 374 # Backward slashes are converted to forward slashes, 375 # Absolute paths are turned to relative paths. 376 if arcname is None: 377 arcname = name 378 drv, arcname = os.path.splitdrive(arcname) 379 arcname = arcname.replace(os.sep, "/") 380 arcname = arcname.lstrip("/") 381 382 # Now, fill the TarInfo object with 383 # information specific for the file. 384 tarinfo = self.tarinfo() 385 tarinfo.tarfile = self 386 387 # Use os.stat or os.lstat, depending on platform 388 # and if symlinks shall be resolved. 389 if fileobj is None: 390 if hasattr(os, "lstat") and not self.dereference: 391 statres = os.lstat(name) 392 else: 393 statres = os.stat(name) 394 else: 395 statres = os.fstat(fileobj.fileno()) 396 linkname = "" 397 398 stmd = statres.st_mode 399 if stat.S_ISREG(stmd): 400 inode = (statres.st_ino, statres.st_dev) 401 if not self.dereference and statres.st_nlink > 1 and 402 inode in self.inodes and arcname != self.inodes[inode]: 403 # Is it a hardlink to an already 404 # archived file? 405 type = LNKTYPE 406 linkname = self.inodes[inode] 407 else: 408 # The inode is added only if its valid. 409 # For win32 it is always 0. 410 type = REGTYPE 411 if inode[0]: 412 self.inodes[inode] = arcname 413 elif stat.S_ISDIR(stmd): 414 type = DIRTYPE 415 elif stat.S_ISFIFO(stmd): 416 type = FIFOTYPE 417 elif stat.S_ISLNK(stmd): 418 type = SYMTYPE 419 linkname = os.readlink(name) 420 elif stat.S_ISCHR(stmd): 421 type = CHRTYPE 422 elif stat.S_ISBLK(stmd): 423 type = BLKTYPE 424 else: 425 return None 426 427 # Fill the TarInfo object with all 428 # information we can get. 429 tarinfo.name = arcname 430 tarinfo.mode = stmd 431 tarinfo.uid = statres.st_uid 432 tarinfo.gid = statres.st_gid 433 if type == REGTYPE: 434 tarinfo.size = statres.st_size 435 else: 436 tarinfo.size = 0L 437 tarinfo.mtime = statres.st_mtime 438 tarinfo.type = type 439 tarinfo.linkname = linkname 440 if pwd: 441 try: 442 tarinfo.uname = pwd.getpwuid(tarinfo.uid)[0] 443 except KeyError: 444 pass 445 if grp: 446 try: 447 tarinfo.gname = grp.getgrgid(tarinfo.gid)[0] 448 except KeyError: 449 pass 450 451 if type in (CHRTYPE, BLKTYPE): 452 if hasattr(os, "major") and hasattr(os, "minor"): 453 tarinfo.devmajor = os.major(statres.st_rdev) 454 tarinfo.devminor = os.minor(statres.st_rdev) 455 return tarinfo 456 457 def list(self, verbose=True): 458 """Print a table of contents to sys.stdout. If `verbose' is False, only 459 the names of the members are printed. If it is True, an `ls -l'-like 460 output is produced. 461 """ 462 self._check() 463 464 for tarinfo in self: 465 if verbose: 466 print filemode(tarinfo.mode), 467 print "%s/%s" % (tarinfo.uname or tarinfo.uid, 468 tarinfo.gname or tarinfo.gid), 469 if tarinfo.ischr() or tarinfo.isblk(): 470 print "%10s" % ("%d,%d" 471 % (tarinfo.devmajor, tarinfo.devminor)), 472 else: 473 print "%10d" % tarinfo.size, 474 print "%d-%02d-%02d %02d:%02d:%02d" 475 % time.localtime(tarinfo.mtime)[:6], 476 477 print tarinfo.name + ("/" if tarinfo.isdir() else ""), 478 479 if verbose: 480 if tarinfo.issym(): 481 print "->", tarinfo.linkname, 482 if tarinfo.islnk(): 483 print "link to", tarinfo.linkname, 484 print 485 486 def add(self, name, arcname=None, recursive=True, exclude=None, filter=None): 487 """Add the file `name' to the archive. `name' may be any type of file 488 (directory, fifo, symbolic link, etc.). If given, `arcname' 489 specifies an alternative name for the file in the archive. 490 Directories are added recursively by default. This can be avoided by 491 setting `recursive' to False. `exclude' is a function that should 492 return True for each filename to be excluded. `filter' is a function 493 that expects a TarInfo object argument and returns the changed 494 TarInfo object, if it returns None the TarInfo object will be 495 excluded from the archive. 496 """ 497 self._check("aw") 498 499 if arcname is None: 500 arcname = name 501 502 # Exclude pathnames. 503 if exclude is not None: 504 import warnings 505 warnings.warn("use the filter argument instead", 506 DeprecationWarning, 2) 507 if exclude(name): 508 self._dbg(2, "tarfile: Excluded %r" % name) 509 return 510 511 # Skip if somebody tries to archive the archive... 512 if self.name is not None and os.path.abspath(name) == self.name: 513 self._dbg(2, "tarfile: Skipped %r" % name) 514 return 515 516 self._dbg(1, name) 517 518 # Create a TarInfo object from the file. 519 tarinfo = self.gettarinfo(name, arcname) 520 521 if tarinfo is None: 522 self._dbg(1, "tarfile: Unsupported type %r" % name) 523 return 524 525 # Change or exclude the TarInfo object. 526 if filter is not None: 527 tarinfo = filter(tarinfo) 528 if tarinfo is None: 529 self._dbg(2, "tarfile: Excluded %r" % name) 530 return 531 532 # Append the tar header and data to the archive. 533 if tarinfo.isreg(): 534 with bltn_open(name, "rb") as f: 535 self.addfile(tarinfo, f) 536 537 elif tarinfo.isdir(): 538 self.addfile(tarinfo) 539 if recursive: 540 for f in os.listdir(name): 541 self.add(os.path.join(name, f), os.path.join(arcname, f), 542 recursive, exclude, filter) 543 544 else: 545 self.addfile(tarinfo) 546 547 def addfile(self, tarinfo, fileobj=None): 548 """Add the TarInfo object `tarinfo' to the archive. If `fileobj' is 549 given, tarinfo.size bytes are read from it and added to the archive. 550 You can create TarInfo objects using gettarinfo(). 551 On Windows platforms, `fileobj' should always be opened with mode 552 'rb' to avoid irritation about the file size. 553 """ 554 self._check("aw") 555 556 tarinfo = copy.copy(tarinfo) 557 558 buf = tarinfo.tobuf(self.format, self.encoding, self.errors) 559 self.fileobj.write(buf) 560 self.offset += len(buf) 561 562 # If there's data to follow, append it. 563 if fileobj is not None: 564 copyfileobj(fileobj, self.fileobj, tarinfo.size) 565 blocks, remainder = divmod(tarinfo.size, BLOCKSIZE) 566 if remainder > 0: 567 self.fileobj.write(NUL * (BLOCKSIZE - remainder)) 568 blocks += 1 569 self.offset += blocks * BLOCKSIZE 570 571 self.members.append(tarinfo) 572 573 def extractall(self, path=".", members=None): 574 """Extract all members from the archive to the current working 575 directory and set owner, modification time and permissions on 576 directories afterwards. `path' specifies a different directory 577 to extract to. `members' is optional and must be a subset of the 578 list returned by getmembers(). 579 """ 580 directories = [] 581 582 if members is None: 583 members = self 584 585 for tarinfo in members: 586 if tarinfo.isdir(): 587 # Extract directories with a safe mode. 588 directories.append(tarinfo) 589 tarinfo = copy.copy(tarinfo) 590 tarinfo.mode = 0700 591 self.extract(tarinfo, path) 592 593 # Reverse sort directories. 594 directories.sort(key=operator.attrgetter('name')) 595 directories.reverse() 596 597 # Set correct owner, mtime and filemode on directories. 598 for tarinfo in directories: 599 dirpath = os.path.join(path, tarinfo.name) 600 try: 601 self.chown(tarinfo, dirpath) 602 self.utime(tarinfo, dirpath) 603 self.chmod(tarinfo, dirpath) 604 except ExtractError, e: 605 if self.errorlevel > 1: 606 raise 607 else: 608 self._dbg(1, "tarfile: %s" % e) 609 610 def extract(self, member, path=""): 611 """Extract a member from the archive to the current working directory, 612 using its full name. Its file information is extracted as accurately 613 as possible. `member' may be a filename or a TarInfo object. You can 614 specify a different directory using `path'. 615 """ 616 self._check("r") 617 618 if isinstance(member, basestring): 619 tarinfo = self.getmember(member) 620 else: 621 tarinfo = member 622 623 # Prepare the link target for makelink(). 624 if tarinfo.islnk(): 625 tarinfo._link_target = os.path.join(path, tarinfo.linkname) 626 627 try: 628 self._extract_member(tarinfo, os.path.join(path, tarinfo.name)) 629 except EnvironmentError, e: 630 if self.errorlevel > 0: 631 raise 632 else: 633 if e.filename is None: 634 self._dbg(1, "tarfile: %s" % e.strerror) 635 else: 636 self._dbg(1, "tarfile: %s %r" % (e.strerror, e.filename)) 637 except ExtractError, e: 638 if self.errorlevel > 1: 639 raise 640 else: 641 self._dbg(1, "tarfile: %s" % e) 642 643 def extractfile(self, member): 644 """Extract a member from the archive as a file object. `member' may be 645 a filename or a TarInfo object. If `member' is a regular file, a 646 file-like object is returned. If `member' is a link, a file-like 647 object is constructed from the link's target. If `member' is none of 648 the above, None is returned. 649 The file-like object is read-only and provides the following 650 methods: read(), readline(), readlines(), seek() and tell() 651 """ 652 self._check("r") 653 654 if isinstance(member, basestring): 655 tarinfo = self.getmember(member) 656 else: 657 tarinfo = member 658 659 if tarinfo.isreg(): 660 return self.fileobject(self, tarinfo) 661 662 elif tarinfo.type not in SUPPORTED_TYPES: 663 # If a member's type is unknown, it is treated as a 664 # regular file. 665 return self.fileobject(self, tarinfo) 666 667 elif tarinfo.islnk() or tarinfo.issym(): 668 if isinstance(self.fileobj, _Stream): 669 # A small but ugly workaround for the case that someone tries 670 # to extract a (sym)link as a file-object from a non-seekable 671 # stream of tar blocks. 672 raise StreamError("cannot extract (sym)link as file object") 673 else: 674 # A (sym)link's file object is its target's file object. 675 return self.extractfile(self._find_link_target(tarinfo)) 676 else: 677 # If there's no data associated with the member (directory, chrdev, 678 # blkdev, etc.), return None instead of a file object. 679 return None 680 681 def _extract_member(self, tarinfo, targetpath): 682 """Extract the TarInfo object tarinfo to a physical 683 file called targetpath. 684 """ 685 # Fetch the TarInfo object for the given name 686 # and build the destination pathname, replacing 687 # forward slashes to platform specific separators. 688 targetpath = targetpath.rstrip("/") 689 targetpath = targetpath.replace("/", os.sep) 690 691 # Create all upper directories. 692 upperdirs = os.path.dirname(targetpath) 693 if upperdirs and not os.path.exists(upperdirs): 694 # Create directories that are not part of the archive with 695 # default permissions. 696 os.makedirs(upperdirs) 697 698 if tarinfo.islnk() or tarinfo.issym(): 699 self._dbg(1, "%s -> %s" % (tarinfo.name, tarinfo.linkname)) 700 else: 701 self._dbg(1, tarinfo.name) 702 703 if tarinfo.isreg(): 704 self.makefile(tarinfo, targetpath) 705 elif tarinfo.isdir(): 706 self.makedir(tarinfo, targetpath) 707 elif tarinfo.isfifo(): 708 self.makefifo(tarinfo, targetpath) 709 elif tarinfo.ischr() or tarinfo.isblk(): 710 self.makedev(tarinfo, targetpath) 711 elif tarinfo.islnk() or tarinfo.issym(): 712 self.makelink(tarinfo, targetpath) 713 elif tarinfo.type not in SUPPORTED_TYPES: 714 self.makeunknown(tarinfo, targetpath) 715 else: 716 self.makefile(tarinfo, targetpath) 717 718 self.chown(tarinfo, targetpath) 719 if not tarinfo.issym(): 720 self.chmod(tarinfo, targetpath) 721 self.utime(tarinfo, targetpath) 722 723 #-------------------------------------------------------------------------- 724 # Below are the different file methods. They are called via 725 # _extract_member() when extract() is called. They can be replaced in a 726 # subclass to implement other functionality. 727 728 def makedir(self, tarinfo, targetpath): 729 """Make a directory called targetpath. 730 """ 731 try: 732 # Use a safe mode for the directory, the real mode is set 733 # later in _extract_member(). 734 os.mkdir(targetpath, 0700) 735 except EnvironmentError, e: 736 if e.errno != errno.EEXIST: 737 raise 738 739 def makefile(self, tarinfo, targetpath): 740 """Make a file called targetpath. 741 """ 742 source = self.extractfile(tarinfo) 743 try: 744 with bltn_open(targetpath, "wb") as target: 745 copyfileobj(source, target) 746 finally: 747 source.close() 748 749 def makeunknown(self, tarinfo, targetpath): 750 """Make a file from a TarInfo object with an unknown type 751 at targetpath. 752 """ 753 self.makefile(tarinfo, targetpath) 754 self._dbg(1, "tarfile: Unknown file type %r, " 755 "extracted as regular file." % tarinfo.type) 756 757 def makefifo(self, tarinfo, targetpath): 758 """Make a fifo called targetpath. 759 """ 760 if hasattr(os, "mkfifo"): 761 os.mkfifo(targetpath) 762 else: 763 raise ExtractError("fifo not supported by system") 764 765 def makedev(self, tarinfo, targetpath): 766 """Make a character or block device called targetpath. 767 """ 768 if not hasattr(os, "mknod") or not hasattr(os, "makedev"): 769 raise ExtractError("special devices not supported by system") 770 771 mode = tarinfo.mode 772 if tarinfo.isblk(): 773 mode |= stat.S_IFBLK 774 else: 775 mode |= stat.S_IFCHR 776 777 os.mknod(targetpath, mode, 778 os.makedev(tarinfo.devmajor, tarinfo.devminor)) 779 780 def makelink(self, tarinfo, targetpath): 781 """Make a (symbolic) link called targetpath. If it cannot be created 782 (platform limitation), we try to make a copy of the referenced file 783 instead of a link. 784 """ 785 if hasattr(os, "symlink") and hasattr(os, "link"): 786 # For systems that support symbolic and hard links. 787 if tarinfo.issym(): 788 if os.path.lexists(targetpath): 789 os.unlink(targetpath) 790 os.symlink(tarinfo.linkname, targetpath) 791 else: 792 # See extract(). 793 if os.path.exists(tarinfo._link_target): 794 if os.path.lexists(targetpath): 795 os.unlink(targetpath) 796 os.link(tarinfo._link_target, targetpath) 797 else: 798 self._extract_member(self._find_link_target(tarinfo), targetpath) 799 else: 800 try: 801 self._extract_member(self._find_link_target(tarinfo), targetpath) 802 except KeyError: 803 raise ExtractError("unable to resolve link inside archive") 804 805 def chown(self, tarinfo, targetpath): 806 """Set owner of targetpath according to tarinfo. 807 """ 808 if pwd and hasattr(os, "geteuid") and os.geteuid() == 0: 809 # We have to be root to do so. 810 try: 811 g = grp.getgrnam(tarinfo.gname)[2] 812 except KeyError: 813 g = tarinfo.gid 814 try: 815 u = pwd.getpwnam(tarinfo.uname)[2] 816 except KeyError: 817 u = tarinfo.uid 818 try: 819 if tarinfo.issym() and hasattr(os, "lchown"): 820 os.lchown(targetpath, u, g) 821 else: 822 if sys.platform != "os2emx": 823 os.chown(targetpath, u, g) 824 except EnvironmentError, e: 825 raise ExtractError("could not change owner") 826 827 def chmod(self, tarinfo, targetpath): 828 """Set file permissions of targetpath according to tarinfo. 829 """ 830 if hasattr(os, 'chmod'): 831 try: 832 os.chmod(targetpath, tarinfo.mode) 833 except EnvironmentError, e: 834 raise ExtractError("could not change mode") 835 836 def utime(self, tarinfo, targetpath): 837 """Set modification time of targetpath according to tarinfo. 838 """ 839 if not hasattr(os, 'utime'): 840 return 841 try: 842 os.utime(targetpath, (tarinfo.mtime, tarinfo.mtime)) 843 except EnvironmentError, e: 844 raise ExtractError("could not change modification time") 845 846 #-------------------------------------------------------------------------- 847 def next(self): 848 """Return the next member of the archive as a TarInfo object, when 849 TarFile is opened for reading. Return None if there is no more 850 available. 851 """ 852 self._check("ra") 853 if self.firstmember is not None: 854 m = self.firstmember 855 self.firstmember = None 856 return m 857 858 # Read the next block. 859 self.fileobj.seek(self.offset) 860 tarinfo = None 861 while True: 862 try: 863 tarinfo = self.tarinfo.fromtarfile(self) 864 except EOFHeaderError, e: 865 if self.ignore_zeros: 866 self._dbg(2, "0x%X: %s" % (self.offset, e)) 867 self.offset += BLOCKSIZE 868 continue 869 except InvalidHeaderError, e: 870 if self.ignore_zeros: 871 self._dbg(2, "0x%X: %s" % (self.offset, e)) 872 self.offset += BLOCKSIZE 873 continue 874 elif self.offset == 0: 875 raise ReadError(str(e)) 876 except EmptyHeaderError: 877 if self.offset == 0: 878 raise ReadError("empty file") 879 except TruncatedHeaderError, e: 880 if self.offset == 0: 881 raise ReadError(str(e)) 882 except SubsequentHeaderError, e: 883 raise ReadError(str(e)) 884 break 885 886 if tarinfo is not None: 887 self.members.append(tarinfo) 888 else: 889 self._loaded = True 890 891 return tarinfo 892 893 #-------------------------------------------------------------------------- 894 # Little helper methods: 895 896 def _getmember(self, name, tarinfo=None, normalize=False): 897 """Find an archive member by name from bottom to top. 898 If tarinfo is given, it is used as the starting point. 899 """ 900 # Ensure that all members have been loaded. 901 members = self.getmembers() 902 903 # Limit the member search list up to tarinfo. 904 if tarinfo is not None: 905 members = members[:members.index(tarinfo)] 906 907 if normalize: 908 name = os.path.normpath(name) 909 910 for member in reversed(members): 911 if normalize: 912 member_name = os.path.normpath(member.name) 913 else: 914 member_name = member.name 915 916 if name == member_name: 917 return member 918 919 def _load(self): 920 """Read through the entire archive file and look for readable 921 members. 922 """ 923 while True: 924 tarinfo = self.next() 925 if tarinfo is None: 926 break 927 self._loaded = True 928 929 def _check(self, mode=None): 930 """Check if TarFile is still open, and if the operation's mode 931 corresponds to TarFile's mode. 932 """ 933 if self.closed: 934 raise IOError("%s is closed" % self.__class__.__name__) 935 if mode is not None and self.mode not in mode: 936 raise IOError("bad operation for mode %r" % self.mode) 937 938 def _find_link_target(self, tarinfo): 939 """Find the target member of a symlink or hardlink member in the 940 archive. 941 """ 942 if tarinfo.issym(): 943 # Always search the entire archive. 944 linkname = "/".join(filter(None, (os.path.dirname(tarinfo.name), tarinfo.linkname))) 945 limit = None 946 else: 947 # Search the archive before the link, because a hard link is 948 # just a reference to an already archived file. 949 linkname = tarinfo.linkname 950 limit = tarinfo 951 952 member = self._getmember(linkname, tarinfo=limit, normalize=True) 953 if member is None: 954 raise KeyError("linkname %r not found" % linkname) 955 return member 956 957 def __iter__(self): 958 """Provide an iterator object. 959 """ 960 if self._loaded: 961 return iter(self.members) 962 else: 963 return TarIter(self) 964 965 def _dbg(self, level, msg): 966 """Write debugging output to sys.stderr. 967 """ 968 if level <= self.debug: 969 print >> sys.stderr, msg 970 971 def __enter__(self): 972 self._check() 973 return self 974 975 def __exit__(self, type, value, traceback): 976 if type is None: 977 self.close() 978 else: 979 # An exception occurred. We must not call close() because 980 # it would try to write end-of-archive blocks and padding. 981 if not self._extfileobj: 982 self.fileobj.close() 983 self.closed = True 984 # class TarFile 985 986 TarFile
6. json和pickle模块
文件只能存二进制或字符串,不能存其他类型,所以用到了用于序列化的两个模块:
json,用于字符串和python数据类型间进行转换,将数据通过特殊的形式转换为所有语言都认识的字符串(字典,变量,列表。。。)
pickle,用于python特有的类型和python的数据类型间进行转换,将数据通过特殊的形式转换为只有python认识的字符串(函数,类)
① json模块:
1 #json序列化和反序列化
2 import json
3
4 info = {
5 "name":"mm",
6 "age":18
7 }
8
9 with open("test","w") as f:
10 f.write(json.dumps(info)) #用json将info写入文件test中
11
12 with open("test","r") as f:
13 info = json.loads(f.read())
14 print(info)
15 #{'name': 'mm', 'age': 18}
② pickle模块:
1 #pickle 序列化和反序列化 2 import pickle 3 4 def func(): 5 info = { 6 "name":"mm", 7 "age":18 8 } 9 print(info,type(info)) 10 11 func() 12 #{'name': 'mm', 'age': 18} <class 'dict'> 13 14 with open("test2","wb",) as f: 15 f.write(pickle.dumps(func)) #用pickle将func写入到文件test中 16 17 with open("test2","rb") as f: 18 func_new = pickle.loads(f.read()) 19 func_new() 20 #{'name': 'mm', 'age': 18} <class 'dict'>
更多内容-》》http://openskill.cn/article/472
7. shelve模块
shelve模块内部对pickle进行了封装,shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
1 import shelve 2 3 # k,v方式存储数据 4 s = shelve.open("shelve_test") #打开一个文件 5 tuple = (1,2,3,4) 6 list = ['a','b','c','d'] 7 info = {"name":"mm","age":18} 8 s["tuple"] = tuple # 持久化元组 9 s["list"] = list 10 s["info"] = info 11 s.close() 12 13 #通过key获取value值 14 d = shelve.open("shelve_test") # 打开一个文件 15 print(d["tuple"]) # 读取 16 print(d.get("list")) 17 print(d.get("info")) 18 # (1, 2, 3, 4) 19 # ['a', 'b', 'c', 'd'] 20 # {'name': 'mm', 'age': 18} 21 d.close() 22 23 # 循环打印key值 24 s = shelve.open("shelve_test") #打开一个文件 25 for k in s.keys(): #循环key值 26 print(k) 27 28 # tuple 29 # list 30 # info 31 s.close() 32 33 # 更新key的value值 34 s = shelve.open("shelve_test") # 打开一个文件 35 s.update({"list":[22,33]}) # 重新赋值 或者s["list"] = [22,33] 36 print(s["list"]) 37 38 #[22,33] 39 s.close()
8.xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml
xml的格式如下,就是通过<>节点来区别数据结构的:
1 <?xml version="1.0"?> 2 <data> 3 <country name="Liechtenstein"> 4 <rank updated="yes">2</rank> 5 <year>2008</year> 6 <gdppc>141100</gdppc> 7 <neighbor name="Austria" direction="E"/> 8 <neighbor name="Switzerland" direction="W"/> 9 </country> 10 <country name="Singapore"> 11 <rank updated="yes">5</rank> 12 <year>2011</year> 13 <gdppc>59900</gdppc> 14 <neighbor name="Malaysia" direction="N"/> 15 </country> 16 <country name="Panama"> 17 <rank updated="yes">69</rank> 18 <year>2011</year> 19 <gdppc>13600</gdppc> 20 <neighbor name="Costa Rica" direction="W"/> 21 <neighbor name="Colombia" direction="E"/> 22 </country> 23 </data>
xml协议在各个语言里的都是支持的,在python中可以用以下模块操作xml
1 import xml.etree.ElementTree as ET 2 3 tree = ET.parse("xmltest.xml") 4 root = tree.getroot() 5 print(root.tag) 6 7 #遍历xml文档 8 for child in root: 9 print(child.tag,child.attrib) 10 for i in child: 11 print(i.tag,i.text) 12 13 print("----------------") 14 15 #只遍历year 节点 16 for node in root.iter('year'): 17 print(node.tag,node.text)
修改和删除xml文档内容
1 import xml.etree.ElementTree as ET 2 3 tree = ET.parse("xmltest.xml") 4 root = tree.getroot() 5 6 # 修改 7 for node in root.iter('year'): 8 new_year = int(node.text) + 1 9 node.text = str(new_year) 10 node.set("updated", "yes") 11 12 tree.write("xmltest.xml") 13 14 # 删除node 15 for country in root.findall('country'): 16 rank = int(country.find('rank').text) 17 if rank > 50: 18 root.remove(country) 19 20 tree.write('output.xml')
自己创建xml文档
1 import xml.etree.ElementTree as ET 2 3 new_xml = ET.Element("personinfolist") 4 personinfo = ET.SubElement(new_xml, "personinfo", attrib={"enrolled": "yes"}) 5 name = ET.SubElement(personinfo, "name") 6 name.text = "tt" 7 age = ET.SubElement(personinfo, "age", attrib={"checked": "no"}) 8 sex = ET.SubElement(personinfo, "sex") 9 age.text = '33' 10 personinfo2 = ET.SubElement(new_xml, "personinfo", attrib={"enrolled": "no"}) 11 name = ET.SubElement(personinfo2, "name") 12 name.text = "mm" 13 age = ET.SubElement(personinfo2, "age") 14 age.text = '19' 15 16 et = ET.ElementTree(new_xml) # 生成文档对象 17 et.write("test.xml", encoding="utf-8", xml_declaration=True) 18 19 ET.dump(new_xml) # 打印生成的格式
9.configparser模块
用于生成和修改常见配置文档,当前模块的名称在 python 3.x 版本中变更为 configparser
来看一个好多软件的常见文档格式如下:
[DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
1 import configparser 2 3 config = configparser.ConfigParser() 4 config["DEFAULT"] = {'ServerAliveInterval': '45', 5 'Compression': 'yes', 6 'CompressionLevel': '9'} 7 8 config['bitbucket.org'] = {} 9 config['bitbucket.org']['User'] = 'hg' 10 config['topsecret.server.com'] = {} 11 topsecret = config['topsecret.server.com'] 12 topsecret['Host Port'] = '50022' # mutates the parser 13 topsecret['ForwardX11'] = 'no' # same here 14 config['DEFAULT']['ForwardX11'] = 'yes' 15 with open('example.ini', 'w') as configfile: 16 config.write(configfile)
写完了还可以再读出来哈:
1 import configparser 2 config = configparser.ConfigParser() 3 print(config.sections()) 4 # [] 5 print(config.read('example.ini')) 6 # ['example.ini'] 7 print(config.sections()) 8 # ['bitbucket.org', 'topsecret.server.com'] 9 print('bitbucket.org' in config) 10 # True 11 print('bytebong.com' in config) 12 # False 13 print(config['bitbucket.org']['User']) 14 # hg 15 print(config['DEFAULT']['Compression']) 16 # yes 17 topsecret = config['topsecret.server.com'] 18 print(topsecret['ForwardX11']) 19 # no 20 print(topsecret['host port']) 21 # 50022 22 for key in config['bitbucket.org']: 23 print(key) 24 # user 25 # serveraliveinterval 26 # compression 27 # compressionlevel 28 # forwardx11 29 print(config['bitbucket.org']['ForwardX11']) 30 #yes
configparser增删改查语法:
1 [section1] 2 k1 = v1 3 k2:v2 4 5 [section2] 6 k1 = v1 7 8 import ConfigParser 9 10 config = ConfigParser.ConfigParser() 11 config.read('i.cfg') 12 13 # ########## 读 ########## 14 #secs = config.sections() 15 #print secs 16 #options = config.options('group2') 17 #print options 18 19 #item_list = config.items('group2') 20 #print item_list 21 22 #val = config.get('group1','key') 23 #val = config.getint('group1','key') 24 25 # ########## 改写 ########## 26 #sec = config.remove_section('group1') 27 #config.write(open('i.cfg', "w")) 28 29 #sec = config.has_section('wupeiqi') 30 #sec = config.add_section('wupeiqi') 31 #config.write(open('i.cfg', "w")) 32 33 34 #config.set('group2','k1',11111) 35 #config.write(open('i.cfg', "w")) 36 37 #config.remove_option('group2','age') 38 #config.write(open('i.cfg', "w"))
10.hashlib模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
1 import hashlib 2 3 m = hashlib.md5() 4 m.update(b"Hello") 5 m.update(b"It's me") 6 print(m.digest()) 7 m.update(b"It's been a long time since last time we ...") 8 9 print(m.digest()) #2进制格式hash 10 print(len(m.hexdigest())) #16进制格式hash 11 ''' 12 def digest(self, *args, **kwargs): # real signature unknown 13 """ Return the digest value as a string of binary data. """ 14 pass 15 16 def hexdigest(self, *args, **kwargs): # real signature unknown 17 """ Return the digest value as a string of hexadecimal digits. """ 18 pass 19 20 ''' 21 import hashlib 22 23 # ######## md5 ######## 24 25 hash = hashlib.md5() 26 hash.update('admin') 27 print(hash.hexdigest()) 28 29 # ######## sha1 ######## 30 31 hash = hashlib.sha1() 32 hash.update('admin') 33 print(hash.hexdigest()) 34 35 # ######## sha256 ######## 36 37 hash = hashlib.sha256() 38 hash.update('admin') 39 print(hash.hexdigest()) 40 41 42 # ######## sha384 ######## 43 44 hash = hashlib.sha384() 45 hash.update('admin') 46 print(hash.hexdigest()) 47 48 # ######## sha512 ######## 49 50 hash = hashlib.sha512() 51 hash.update('admin') 52 print(hash.hexdigest())
还不够吊?python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
1 import hmac 2 h = hmac.new(b"mm","love you 宝贝".encode(encoding="utf-8")) 3 print(h.hexdigest()) 4 # 2473ff5df2affb790010cc92cd227780 5 6 t = hmac.new(b"mm") 7 t.update("love you 宝贝".encode(encoding="utf-8")) 8 print(t.hexdigest()) 9 # 2473ff5df2affb790010cc92cd227780